本文翻译和精简自 Stanford cs224n lec08
1. Seq2seq
1.1 seq2seq的训练

可以看出,整个seq2seq模型分为两大部分:Encoder RNN和Decoder RNN。
在Encoder RNN部分,先将待翻译的原文经过一个RNN (这里可以是vanilla RNN, LSTM,GRU等等),并且使用最后一个隐藏状态作为整句话的encoding表示,作为Decoder RNN的初始隐藏状态输入到Decoder RNN中去。
在Decoder RNN部分,每个timestep的输入就是翻译后的词语embedding,将每一步的隐藏状态经过全连接层,得到整个词汇表每个词的概率分布,然后和实际的词语(one-hot编码)去对比,得到交叉熵损失。将所有的交叉熵损失求平均,即可得到整体的损失。
1.2 Seq2seq的测试
1.2.1 网络结构

decoder RNN 的第一个输入是 <START>, 每一步的hidden state再经过一个全连接层得到整个词汇表的概率分布,之后取一个概率最大的词(argmax)作为此时的翻译。每一个 timestep 的翻译词作为下一个timestep的输入,以此继续,直到最后输出<END>
1.2.2 解决局部极小 – beam search
greedy decoding:

贪婪的decoding方法就是每一步都选概率最大的那个词语作为下一步的输入。这种方法的问题就是无法回退->可能陷入局部极小值(local minimia).
所以,我们引入了beam search的方法。
beam search的核心思想是,每一步都考虑 k 个最可能的翻译词语, k叫beam size。最后得到若干个翻译结果,这些结果叫hypothesis,然后选择一个概率最大的hypothesis即可。
例如,当选择k = 2时,翻译 il a’ m’ entarte:

<START>后面概率最大的两个词是"I"和"he",概率的log值分别为-0.9和-0.7。我们就取这两个词继续往下递归,"<start>he"再往后概率最大的两个词是"hit"和"struck",其概率的对数加上之前的-0.7,分别得到-1.7和-2.9,也就是"he hit"和"he struck"的得分分别为 -1.7 和-2.9 。同理,“I was"和” I got"的得分分别为 -1.6 和-1.8. 在这一步,又取得分最高的两句话"he hit"(-1.7)和"I was"(-1.6)往下递归,在此省略若干步骤…
迭代若干步之后得到:

取最终得分最高的那句话,“he hit me with a pie.”

beam search 的终止条件:
在 beam search中,不同的词语选择方法会导致在不同的时候出现<END>,所以每个hypothesis(翻译句子)的长度都不一样。当一个hypothesis最终预测出了<END>,就说明这句话已经预测完毕了,就可以把这句话先放在一边,然后再用beam search取搜索其他的句子。
所以,beam search的终止条件可以为:
- 达到 timestep T
- 获得了 n 个完整的hypothesis
选择最好的hypothesis:
对于一个需要我们翻译的外文句子 x x x,有若干个可能的hypothesis,对每个hypothesis y 1 , . . . y t y_1,...y_t y1,...yt都计算一个score:
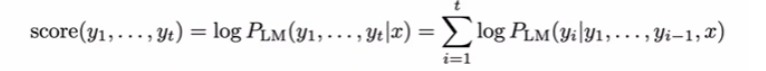
但是这个有一个非常明显的问题!就是越长的句子score越低,因为连乘导致了概率值越来越小。当然解决这个问题的方法也很简单了,就是对每个句子的长度做一个平均。
但是,回忆之前的这个例子:
我们好像没有对长度做平均对吧?这是因为每一步的句子长度都是一样的,平均和不平均没有任何区别。
1.3 seq2seq 的其他应用
- 文本摘要 (长文本->短文本)。关于文本摘要可以看这里:https://blog.csdn.net/weixin_41332009/article/details/111475885
- 对话(previous utterance->next utterance)
- 代码生成(自然语言->python代码),当然这个太难了…
1.4 机器翻译评估
BLEU(Bilingual Evaluation Understudy) 比较了我们的机器翻译结果和人翻译的结果(ground truth)进行相似度计算。这里所谓的“相似度”就是用两者的1-gram, 2-gram… n-gram重合度来算的。
同时,别忘了对长度较短的翻译做一个惩罚哦,这是因为如果我们让翻译特别短,只翻译出那些特别确定的词,那么n-gram重合度一定高,但是这并不是一个很好的翻译!
BLEU评测很有效,但有的时候并不完善。这是因为对于一句外文,有很多可能的翻译方式,如果只用n-gram进行精确匹配,可能会导致一个原本很好的翻译评分很低。
1.5 机器翻译的困难
- 对于一个我们根本没见过的词 (Out-of-vocabulary words, <unk>) 该如何翻译呢?
- 训练集和测试集必须非常相似。 (如果你用Wikipedia这种非常正式的语料库训练,再用人们在twitter上聊天做测试,效果一定不好)
- 对于长文本的翻译比较困难
- 某些语言平行语料非常少(如Thai-Eng)
- 训练语料的一些bias也会被机器翻译算法学去,导致在翻译测试的时候会体现出这种bias。
例如:

(这不是赤裸裸的性别歧视吗,本程序媛表示不服)但这就是因为在训练语料里面"she"比较有可能是"nurse", "he"比较有可能是"programmer"而已。
再看一个更可怕的例子:

这是因为Somali-Eng平行语料库主要是基于《圣经》,所以在这里机器翻译算法只是在用language model生成一些随机的词语而已…
2. Attention机制
2.1 没有Attention会怎样?

-
the orange box is the encoding of the whole source sentence, it need to capture all the information of the source sentence —> information bottleneck! (too much pressure on this single vector to be a good representation of the source sentence.)
-
the target sentence just have one input, i.e. the orange box, so it does not provide location information.
所以,attention机制就是为了解决这种 information bottleneck 的问题才引入的。
2.2 Attention的核心思想
on each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sentence.
一个例子:

对于decoder的每一个timestep t,都计算它和encoder的每一步的点乘,作为score。之后再把这些score做softmax,变成概率分布。可以看到,第一个柱子最高,说明我们在翻译<start>的时候,需要格外注意source sentence的第一个位置。

用概率分布去乘以encoder每一步的hidden state,得到一个加权的source sentence表示。

之后,把source sentence的表示和decoderRNN每一步的hidden state拼接在一起,得到一个长向量。然后再经过一层全连接网络,得到整个词汇表的概率分布。取一个argmax即得到这一步的预测值。


2.3 Attention的数学表示

2.4 Attention的好处
