Jibea
https://blog.csdn.net/qq_18603599/article/details/80865215
https://blog.csdn.net/qq_18603599/article/details/80865226
https://blog.csdn.net/qq_18603599/article/details/80865233
词性标注
北大词性标注集
宾州词性标注集
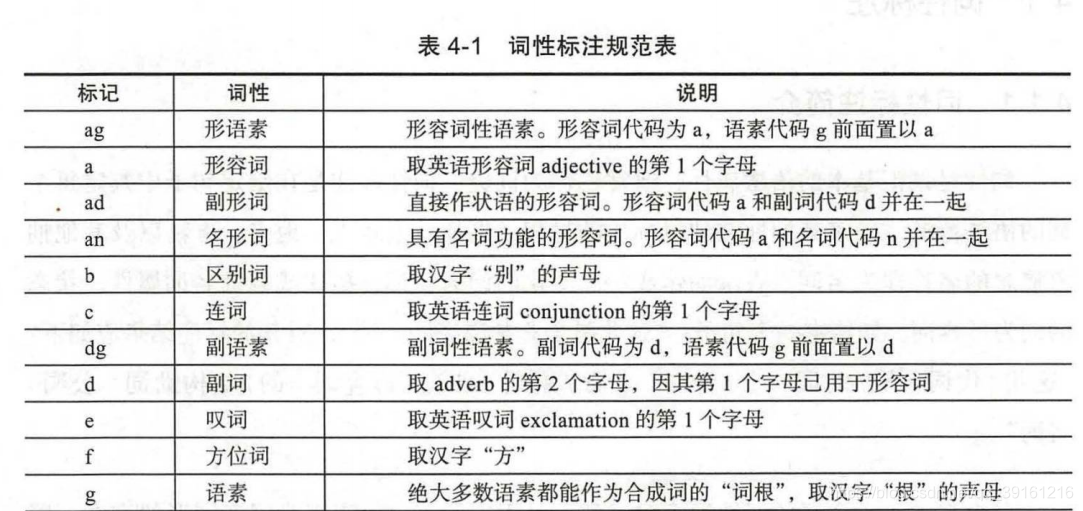
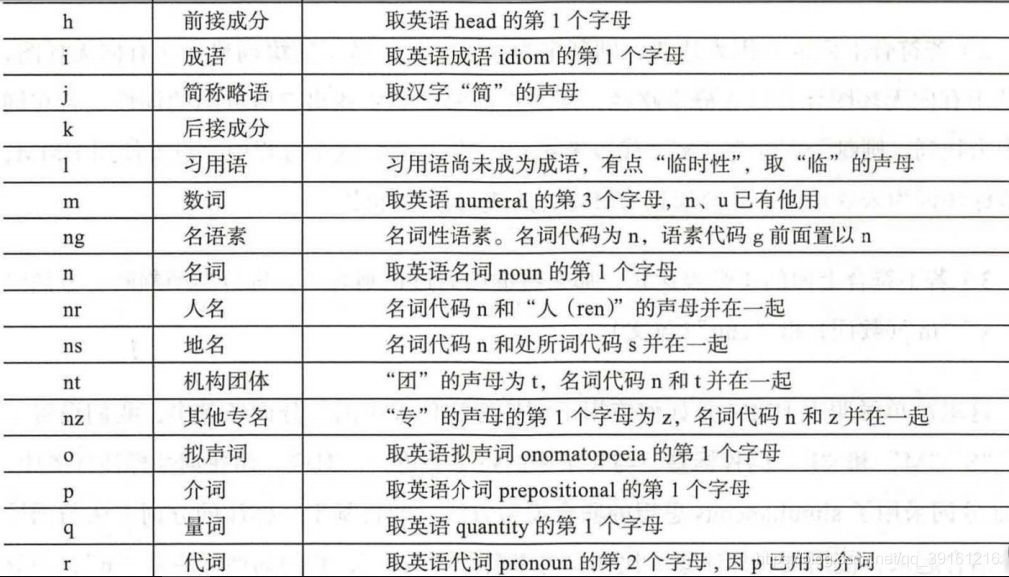
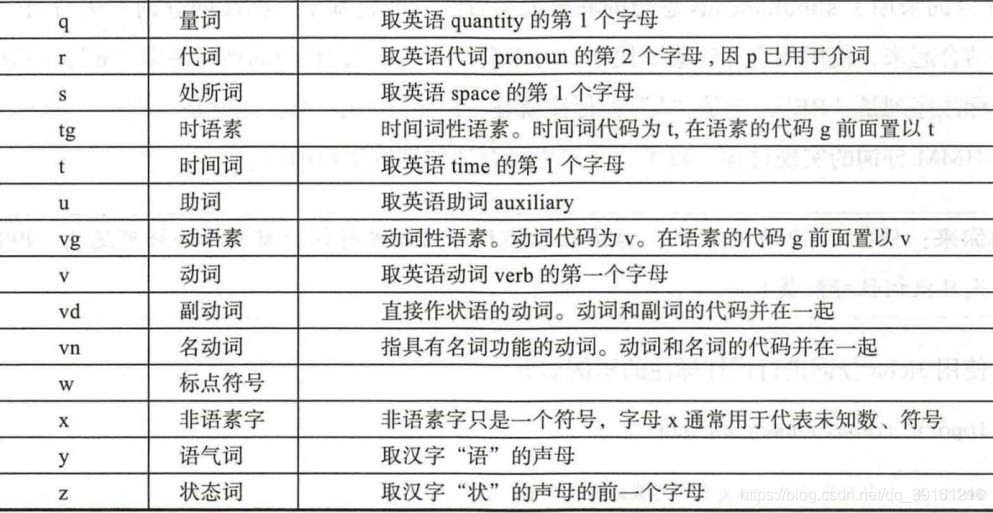
https://www.cnblogs.com/hapyygril/category/1333473.html
关键词提取算法 TF/IDF
词库中的某个词在当前文章中出现的频率

TF(i,j):关键词j在文档i中的出现频率。 n(i,j):关键词j在文档i中出现的次数
反文档频率”。先看什么是文档频率,文档频率DF就是一个词在整个文库词典中出现的频率,就拿上一个例子来讲:一个文件集中有100篇文章,共有10篇文章包含“机器学习”这个词,那么它的文档频率就是10/100=0.1,反文档频率IDF就是这个值的倒数,即10
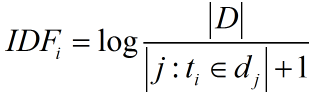
IDF(i):词语i的反文档频率
|D|:语料库中的文件总数
|j:t(i)属于d(j)|出现词语i的文档总数
+1是为了防止分母变0。
TextBank算法
Extraction和Abstraction。其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要