哈夫曼树(最优树)
带权路径长度 最短的树
路径 :从树中一个结点到另一个结点之间的分支构成这两个结点间的路径。
结点的路径长度 :两结点间路径上的分支数。

树的路径长度 :从树根到每一个结点的路径长度之和。记作:
结点数目相同的二叉树中,完全二叉树是路径长度最短的二叉树。
权(weight) :将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度 :从根结点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度WPL(Weighted Path Length) :树中所有叶子结点的带权路径长度之和。
WPL
有四个结点
,权值为
,如下图所示,计算
:

构造哈夫曼树的方法
(1)根据
个给定的权值
构成n棵二叉树的森林
,其中
只有一个带权为
的根结点。
(2)在
中选取两棵根结点的权值最小的树作为左右子树,构造一颗新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
(3)在
中删除这两棵树,同时将得到的二叉树加入森林中。

总结
(1)在哈夫曼算法中,初始时有n棵二叉树,要经过
次合并最终形成哈夫曼树。
(2)经过
次合并产生
个新结点,且这
个新结点都是具有两个孩子的分支结点。
哈夫曼树构造算法的实现
采用顺序存储结构——一维结构数组 HuffmanTree H;
typedef struct
{
int weight;
int parent, lch, rch;
}HTNode,*HuffmanTree;
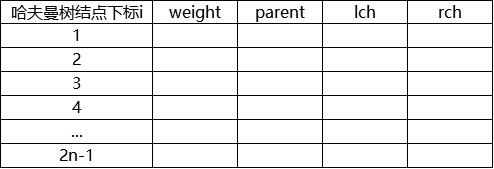
lch,rch存放的是数组下标
算法实现
- 初始化 ;
- 输入初始n个叶子结点,置 的 值
- 进行以下
次合并,依次产生
个结点
(a)在 中选两个未被选过(从 的结点中选)的weight最小的两个结点 和 , 、 为两个最小结点下标;
(b)修改 和 的 值: ; ;
(c)修改新产生的 :
代码实现
void CreateHuffmanTree(HuffmanTree HT, int n)
{
//构造哈夫曼树——哈夫曼算法
if (n <= 1)
return;
int m = 2 * n - 1;
HT = (HTNode*)malloc((m + 1) * sizeof(HTNode));
for (int i = 1; i <= m; ++i)
{
HT[i].lch = 0;
HT[i].rch = 0;
HT[i].parent = 0;
}
for (int i = 1; i <= n; ++i)
scanf_s("%d", &HT[i].weight);//输入前n个元素的weight值
for (i = n + 1; i <= m; i++)
{
Select(HT, i - 1, s1, s2);//在HT[k](1<=k<=i-1)中选择两个其双亲域为0,且权值最小的结点,并且返回它们在HT中的序号s1,s2
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lch = s1;
HT[i].rch = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
}
哈夫曼编码
问题:什么样的前缀码能使得电文总长最短?
方法:
- 统计字符集中每个字符在电文中出现的平均概率(概率越大要求编码越短)。
- 利用哈夫曼树的特点:权越大的叶子离根越近;将每个字符的概率值作为权值,构造哈夫曼树。则概率越大的结点,路径越短。
- 在哈夫曼树的每个分支上标上
或
:
结点的左分支标 ,右分支标
把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码。
要传输的字符集D={A,B,C,D,E},字符出现频率w={7,5,5,2,4}

- 为什么哈夫曼编码能够保证是前缀编码?
没有一片树叶是另一片树叶的祖先,所以每个叶结点的编码就不可能是其他叶结点编码的前缀。 - 为什么哈夫曼编码能够保证字符编码总长最短?
因为哈夫曼树的带权路径长度最短,故字符编码的总长最短。
性质一: 哈夫曼编码是前缀码
性质二: 哈夫曼编码是最优前缀码
哈夫曼树 文件的编码与解码