2.8mnist手写数字识别之模型保存与恢复精讲(百度架构师手把手带你零基础实践深度学习原版笔记系列)
目录
2.8mnist手写数字识别之模型保存与恢复精讲(百度架构师手把手带你零基础实践深度学习原版笔记系列)
模型加载及恢复训练
在之前的章节已经向读者介绍了将训练好的模型保存到磁盘文件的方法。应用程序可以随时加载模型,完成预测任务。但是在日常训练工作中,我们会遇到一些突发情况,导致训练过程主动或被动的中断。如果训练一个模型需要花费几天的时间,中断后从初始状态重新训练是不可接受的。
万幸的是,飞桨支持从上一次保存状态开始继续训练,只要我们随时保存训练过程中的模型状态,就不用从初始状态重新训练。
下面介绍恢复训练的实现方法,依然使用手写数字识别的案例,网络定义的部分保持不变。
import os
import random
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
import numpy as np
from PIL import Image
import gzip
import json
# 定义数据集读取器
def load_data(mode='train'):
# 数据文件
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
data = json.load(gzip.open(datafile))
train_set, val_set, eval_set = data
# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLS
IMG_ROWS = 28
IMG_COLS = 28
if mode == 'train':
imgs = train_set[0]
labels = train_set[1]
elif mode == 'valid':
imgs = val_set[0]
labels = val_set[1]
elif mode == 'eval':
imgs = eval_set[0]
labels = eval_set[1]
imgs_length = len(imgs)
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(
len(imgs), len(labels))
index_list = list(range(imgs_length))
# 读入数据时用到的batchsize
BATCHSIZE = 100
# 定义数据生成器
def data_generator():
if mode == 'train':
random.shuffle(index_list)
imgs_list = []
labels_list = []
for i in index_list:
img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.reshape(labels[i], [1]).astype('int64')
imgs_list.append(img)
labels_list.append(label)
if len(imgs_list) == BATCHSIZE:
yield np.array(imgs_list), np.array(labels_list)
imgs_list = []
labels_list = []
# 如果剩余数据的数目小于BATCHSIZE,
# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
#调用加载数据的函数
train_loader = load_data('train')
# 定义模型结构
class MNIST(fluid.dygraph.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一个卷积层,使用relu激活函数
self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义一个池化层,池化核为2,步长为2,使用最大池化方式
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一个卷积层,使用relu激活函数
self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义一个池化层,池化核为2,步长为2,使用最大池化方式
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一个全连接层,输出节点数为10
self.fc = Linear(input_dim=980, output_dim=10, act='softmax')
# 定义网络的前向计算过程
def forward(self, inputs, label):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = fluid.layers.reshape(x, [x.shape[0], 980])
x = self.fc(x)
if label is not None:
acc = fluid.layers.accuracy(input=x, label=label)
return x, acc
else:
return x
loading mnist dataset from ./work/mnist.json.gz ......
在开始介绍使用飞桨恢复训练前,先正常训练一个模型,优化器使用Adam,使用动态变化的学习率,学习率从0.01衰减到0.001。每训练一轮后保存一次模型,之后将采用其中某一轮的模型参数进行恢复训练,验证一次性训练和中断再恢复训练的模型表现是否一致(训练loss的变化)。
注意进行恢复训练的程序不仅要保存模型参数,还要保存优化器参数。这是因为某些优化器含有一些随着训练过程变换的参数,例如Adam, AdaGrad等优化器采用可变学习率的策略,随着训练进行会逐渐减少学习率。这些优化器的参数对于恢复训练至关重要。
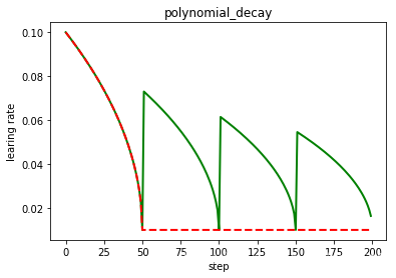
为了演示这个特性,下面训练程序使用Adam优化器,学习率以多项式曲线从0.01衰减到0.001(polynomial decay)。
lr = fluid.dygraph.PolynomialDecay(0.01, total_steps, 0.001)
- learning_rate:初始学习率
- decay_steps:衰减步数
- end_learning_rate:最终学习率
- power:多项式的幂,默认值为1.0
- cycle:下降后是否重新上升,polynomial decay的变化曲线下图所示。
#在使用GPU机器时,可以将use_gpu变量设置成True
use_gpu = False
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
model = MNIST()
model.train()
EPOCH_NUM = 5
BATCH_SIZE = 100
# 定义学习率,并加载优化器参数到模型中
total_steps = (int(60000//BATCH_SIZE) + 1) * EPOCH_NUM
lr = fluid.dygraph.PolynomialDecay(0.01, total_steps, 0.001)
# 使用Adam优化器
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=lr, parameter_list=model.parameters())
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程,同时拿到模型输出值和分类准确率
predict, acc = model(image, label)
avg_acc = fluid.layers.mean(acc)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.numpy(),avg_acc.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
# 保存模型参数和优化器的参数
fluid.save_dygraph(model.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id))
fluid.save_dygraph(optimizer.state_dict(), './checkpoint/mnist_epoch{}'.format(epoch_id))epoch: 0, batch: 0, loss is: [2.3720088], acc is [0.14] epoch: 0, batch: 200, loss is: [0.04033202], acc is [0.98] epoch: 0, batch: 400, loss is: [0.03195312], acc is [0.99] epoch: 1, batch: 0, loss is: [0.04147393], acc is [1.] epoch: 1, batch: 200, loss is: [0.00495559], acc is [1.] epoch: 1, batch: 400, loss is: [0.09799033], acc is [0.99] epoch: 2, batch: 0, loss is: [0.01665663], acc is [0.99] epoch: 2, batch: 200, loss is: [0.0056052], acc is [1.] epoch: 2, batch: 400, loss is: [0.05713874], acc is [0.99] epoch: 3, batch: 0, loss is: [0.01624688], acc is [0.99] epoch: 3, batch: 200, loss is: [0.05197361], acc is [0.99] epoch: 3, batch: 400, loss is: [0.0362546], acc is [0.99] epoch: 4, batch: 0, loss is: [0.02300941], acc is [0.99] epoch: 4, batch: 200, loss is: [0.00185198], acc is [1.] epoch: 4, batch: 400, loss is: [0.00332312], acc is [1.]
恢复训练
在上述训练代码中,我们训练了五轮(epoch)。在每轮结束时,均保存了模型参数和优化器相关的参数。
- 使用
model.state_dict()获取模型参数。 - 使用
optimizer.state_dict()获取优化器和学习率相关的参数。 - 调用
fluid.save_dygraph()将参数保存到本地。
比如第一轮训练保存的文件是mnist_epoch0.pdparams,mnist_epoch0.pdopt,分别存储了模型参数和优化器参数。
当加载模型时,如果模型参数文件和优化器参数文件是相同的,我们可以使用load_dygraph同时加载这两个文件,如下代码所示。
params_dict, opt_dict = fluid.load_dygraph(params_path)
如果模型参数文件和优化器参数文件的名字不同,需要调用两次load_dygraph分别获得模型参数和优化器参数。
如何判断模型是否准确的恢复训练呢?
理想的恢复训练是模型状态回到训练中断的时刻,恢复训练之后的梯度更新走向是和恢复训练前的梯度走向完全相同的。基于此,我们可以通过恢复训练后的损失变化,判断上述方法是否能准确的恢复训练。即从epoch 0结束时保存的模型参数和优化器状态恢复训练,校验其后训练的损失变化(epoch 1)是否和不中断时的训练完全一致。
说明:
恢复训练有如下两个要点:
- 保存模型时同时保存模型参数和优化器参数。
- 恢复参数时同时恢复模型参数和优化器参数。
下面的代码将展示恢复训练的过程,并验证恢复训练是否成功。其中,我们重新定义一个train_again()训练函数,加载模型参数并从第一个epoch开始训练,以便读者可以校验恢复训练后的损失变化。
params_path = "./checkpoint/mnist_epoch0"
#在使用GPU机器时,可以将use_gpu变量设置成True
use_gpu = False
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
# 加载模型参数到模型中
params_dict, opt_dict = fluid.load_dygraph(params_path)
model = MNIST()
##挂载模型
model.load_dict(params_dict)
EPOCH_NUM = 5
BATCH_SIZE = 100
# 定义学习率,并加载优化器参数到模型中
total_steps = (int(60000//BATCH_SIZE) + 1) * EPOCH_NUM
lr = fluid.dygraph.PolynomialDecay(0.01, total_steps, 0.001)
# 使用Adam优化器
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=lr, parameter_list=model.parameters())
##挂载优化器参数
optimizer.set_dict(opt_dict)
for epoch_id in range(1, EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程,同时拿到模型输出值和分类准确率
predict, acc = model(image, label)
avg_acc = fluid.layers.mean(acc)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.numpy(),avg_acc.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()epoch: 1, batch: 0, loss is: [0.03020493], acc is [0.99] epoch: 1, batch: 200, loss is: [0.04004116], acc is [0.99] epoch: 1, batch: 400, loss is: [0.30918032], acc is [0.97] epoch: 2, batch: 0, loss is: [0.0072555], acc is [1.] epoch: 2, batch: 200, loss is: [0.01369821], acc is [1.] epoch: 2, batch: 400, loss is: [0.01136284], acc is [1.] epoch: 3, batch: 0, loss is: [0.06296802], acc is [0.97] epoch: 3, batch: 200, loss is: [0.10049359], acc is [0.96] epoch: 3, batch: 400, loss is: [0.06160251], acc is [0.98] epoch: 4, batch: 0, loss is: [0.0346011], acc is [0.99] epoch: 4, batch: 200, loss is: [0.02092827], acc is [0.99] epoch: 4, batch: 400, loss is: [0.0224981], acc is [0.98]
从恢复训练的损失变化来看,加载模型参数继续训练的损失函数值和正常训练损失函数值是完全一致的,可见使用飞桨实现恢复训练是极其简单的。