摘要
本文提出了使用Wikipedia作为唯一知识源来解决开放领域问答:任何事实类问题的答案都是Wikipedia文章中的文本范围。 大规模的机器阅读任务将文档检索(查找相关文章)与机器文本理解(识别这些文章的答案范围)的挑战结合在一起。我们的方法将基于bigram哈希和TF-IDF匹配的搜索组件与经过训练以检测Wikipedia段落中的答案的多层循环神经网络模型相结合。我们在多个现有QA数据集上的实验表明,(1)两个模块使用的方法相对于现有技术而言都具有很高的竞争力;(2)使用远程监督对其组合进行多任务学习是完成这一艰巨任务的有效完整系统。
1.介绍
本文考虑了使用Wikipedia作为唯一知识源在开放领域环境中回答事实类问题,例如在百科全书中寻找答案时所遇到的问题。Wikipedia是不断发展的详细信息源,如果智能机器能够利用其强大功能,这些信息就可以为智能机器提供便利。不像Freebase或DBPedia之类的知识库(KB),尽管计算机更易于处理,但对于开放领域问题的回答却过于稀疏,维基百科包含了人类感兴趣的最新知识。但是,它是为人类而非机器阅读而设计的。
使用Wikipedia文章作为知识源会生成结合了大型开放域QA和机器理解文本挑战的问答(QA)任务。为了回答任何问题,必须首先检索超过500万个项目中的几篇相关文章,然后仔细扫描它们以找出答案。我们称此设置为机器大规模读取(machine reading at scale,MRS)。我们的工作将Wikipedia视为文章的集合,并且不依赖于其内部图结构。因此,我们的方法是通用的,可以转换为其他文档,书籍甚至每日更新的报纸。
诸如IBM的DeepQA之类的大规模QA系统依靠多种来源来回答:除了Wikipedia,它还与知识库,字典,甚至新闻文章,书籍等配对。因此,此类系统严重依赖来源之间的信息冗余来正确回答。 只有一个知识来源会迫使模型在寻找答案时非常精确,因为证据可能只会出现一次。因此,这一挑战鼓励研究机器的阅读能力,机器理解这一领域的主要资源是使用创建的SQuAD,CNN / Daily Mail和CBT等数据集。
但是,这些机器理解资源通常假定已经识别了一小段相关文本并将其提供给模型,模型只用在这段文本上找到对应答案即可,这对于构建开放领域QA系统是不现实的。与之形成鲜明对比的是,使用KB或对文档进行信息检索的方法必须将搜索用作解决方案的组成部分。取而代之的是,MRS专注于同时维持机器理解的挑战,这要求对文本有深刻的理解,同时保留了在大型开放资源上进行搜索的现实约束。
在本文中,我们展示了如何通过要求开放领域系统一次对所有数据执行良好的操作,来将多个现有的QA数据集用于评估MRS。我们开发了DrQA(如图1所示),这是一个来自Wikipedia的强大的问答系统,包括:
(1)Document Retriever,该模块使用bigram哈希和TF-IDF匹配,旨在针对给定的问题有效地返回相关文章的子集;
(2)Document Reader,其是一个多层循环神经网络机器理解模型,经过训练可以检测出这几份返回文档中的答案范围。
我们的实验表明,Document Retriever优于内置的Wikipedia搜索引擎,并且Document Reader在竞争非常激烈的SQuAD benchmark测试中达到了最新水平。最后,我们使用多个benchmarks对整个系统进行评估。特别是,我们证明,与单任务训练相比,通过使用多任务学习和远程监督,所有数据集的性能均得到改善。
2.相关工作
基于开放领域问答最初被定义为寻找非结构化文档集合中的答案,这与每年的TREC竞赛中的定义相同。随着知识库的发展,基于知识库的问答出现了许多最新的创新,例如基于Freebase知识库创建了诸如WebQuestions和SimpleQuestions之类的资源,或自动抽取的KB,例如OpenIE三元组和NELL。但是,知识库具有固有的局限性(不完整,固定的模式),这促使研究人员重新研究文本问答的原始设置。
重新审视此问题的第二个动机是机器理解文本,即在阅读了简短的文本或故事后去回答相关问题。该子领域最近有了新的进步,这要归功于新的深度学习架构,例如基于注意力和记忆增强的神经网络以及新的训练和评估数据集的发布,例如QuizBowl,基于新闻报道的CNN/Daily Mail,基于儿童读物的CBT,SQuAD和WikiReading,后面两者均基于Wikipedia。本文的目的是测试这些新的方法如何在开放领域QA框架中执行。
以前已经探讨了使用Wikipedia作为资源的问答。Ryu等人使用基于维基百科的知识模型进行开放领域的问答。他们根据不同类型的半结构化知识(例如信息框,文章结构,类别结构和定义)将文章内容与其他多个答案匹配模块结合在一起。同样,Ahn等人也将Wikipedia作为文本资源与其他资源相结合,在这种情况下,它还具有对其他文档的信息检索。 Buscaldi和Rosso还从Wikipedia挖掘知识以进行问答。他们没有将其用作寻找问题答案的资源,而是专注于验证其问答系统返回的答案,并使用Wikipedia类别来确定应与预期答案相符的一组模式。在我们的工作中,我们仅考虑文本的理解,并使用Wikipedia文本文档作为唯一的资源,以强调大规模阅读机器的任务,如第一节中所述。
有很多非常有用的全管道QA方法:(1)要么使用Web作为资源,例如QuASE;(2)要么使用Wikipedia作为资源,例如Microsoft的AskMSR,IBM的DeepQA以及YodaQA–后者是开源的,因此可用于比较目的。AskMSR是一个基于搜索引擎的问答系统,它依赖于“数据冗余,而不是对问题或候选答案的复杂语言分析”,即,它不像我们一样专注于机器理解。DeepQA是一个非常复杂的系统,它依赖于非结构化信息(包括文本文档)以及结构化数据(例如KB,数据库和本体),以生成候选答案或对证据进行投票。YodaQA是一个模仿DeepQA的开源系统,类似地将网站,信息提取,数据库和Wikipedia组合在一起。仅使用一种资源就使我们的理解任务更具挑战性。与这些方法进行比较可为性能的“上限”benchmark提供有用的数据点。
多任务学习和任务转移在机器学习中拥有丰富的历史(例如,在计算机视觉社区中使用的ImageNet,特别是在NLP中)。多项工作已尝试通过多任务学习来组合多个QA训练数据集,以(i)通过任务转移在整个数据集上实现改进;(ii)提供一个通用系统,由于源数据集之间不可避免的数据分布不同,因此能够提出不同种类的问题。Fader等人使用WebQuestions,TREC和WikiAnswers(四个KB)作为知识源,并报告了通过多任务学习对后两个数据集的改进。Bordes等人将WebQuestions和SimpleQuestions结合在一起,使用远程监管,以Freebase作为知识库,对两个数据集均进行了些微改进,尽管在仅训练一个数据集并测试另一个数据集时报告了较差的性能,这表明任务转移确实是一个具有挑战性的课题。我们的工作遵循相似的主题,但是必须检索然后读取文本文档,而不是使用KB,从而获得了较好的结果。
3.DrQA

在下面,我们描述我们的MRS系统DrQA,它由两个组件组成:
(1)用于查找相关文章的Document Retriever模块;
(2)用于从单个文档或少量文档集合中提取答案的机器理解模型Document Reader。
3.1 Document Retriever
遵循经典的QA系统,我们使用高效的(非机器学习)文档检索系统来首先缩小搜索范围,并专注于仅阅读可能相关的文章。与内置的基于ElasticSearch的Wikipedia Search API相比,简单的反向索引查找后再进行术语向量模型评分,在许多任务类型上都可以很好地完成此任务。 将文章和问题作为TF-IDF加权词袋向量进行比较。我们通过考虑具有n-gram特征的本地单词顺序来进一步改善我们的系统。 我们性能最好的系统使用bigram计数,同时通过使用(Weinberger et al.,2009)的哈希值将bigrams映射到具有未签名的murmur3哈希的
个取值,从而保留了速度和内存效率。
我们将Document Retriever用作完整模型的第一部分,方法是将其设置为返回5条有关任何问题的维基百科文章。这些文章然后由Document Reader处理。
3.2 Document Reader
我们的Document Reader模型的灵感来自于神经网络模型在机器理解任务方面的最新成功,其类似于(Hermann et al.,2015; Chen et al,.2016)中描述的AttentiveReader。
给定一个由
个字符
组成的问题
和
个段落组成的单个文档或文档集合,其中每个段落
由
个字符
组成,我们提出一个RNN模型,依次将其应用于每个段落,然后最终汇总预测的答案。我们的方法如下:
(1)段落编码
我们首先将段落
中的所有字符
表示为特征向量
的序列,并将它们作为输入传递给循环神经网络,从而获得:
其中
被期望编码字符
周围有用的上下文信息。具体来说,我们选择使用多层双向长期短期记忆网络(LSTM),最后将
作为每层隐藏单元的串联。
特征向量
由以下部分组成:
a)词嵌入:
。我们使用从840B网络抓取数据中训练的300维Glove词嵌入。我们使大多数经过预训练的单词嵌入保持固定,并且仅微调1000个最常见的疑问词,因为某些关键字的表示形式(例如,
等)对于QA系统至关重要。
b)完全匹配:
。我们使用三个简单的二进制特征,表示
是否可以和问题
中的某个疑问词完全匹配,或与
原始形式匹配,或与
小写及引理形式匹配。正如我们将在第5节中展示的那样,这些简单的功能非常有用。
c)字符特征:
。我们还添加了一些人工特征,这些特征在其上下文中反映了字符
的某些属性,包括其词性(POS)和命名实体识别(NER)标签以及(标准化的)词频率(TF)。
d)对齐问题嵌入:继(Lee et al.,2016)和其他近期工作之后,我们纳入的最后一部分是对齐问题嵌入
,其中注意力得分
捕获了
与每个疑问词
之间的相似性 。具体而言,
由单词嵌入的非线性映射之间的点积计算:
其中,
是具有ReLU非线性的单个全连接层。与完全匹配特征相比,这些特征在相似但不相同的字词(例如,car和 vehicle)之间增加了软对齐。
(2)问题编码
问题编码更简单,因为我们仅在
词嵌入的顶部应用另一个循环神经网络,然后将生成的隐藏单元组合为一个向量:
。我们计算
,其中
编码每个疑问词的重要性:
其中,
是一个可学习的权重向量。
(3)预测
在段落级别,目标是预测最有可能是正确答案的字符范围。我们采用段落向量
和问题向量
作为输入,只需简单地训练两个分类器即可预测跨度的两端。具体而言,我们使用双线性项来捕获
和
之间的相似性,并计算每个字符作为起点和终点的概率为:
在预测期间,我们选择从开始字符
到结束字符
的最佳跨度,以使
并且
最大化。为了使分数在一个或多个检索到的文档中的各个段落之间兼容,我们使用未标准化指数,并在所有考虑的段落范围内采用argmax作为最终预测。
4.数据
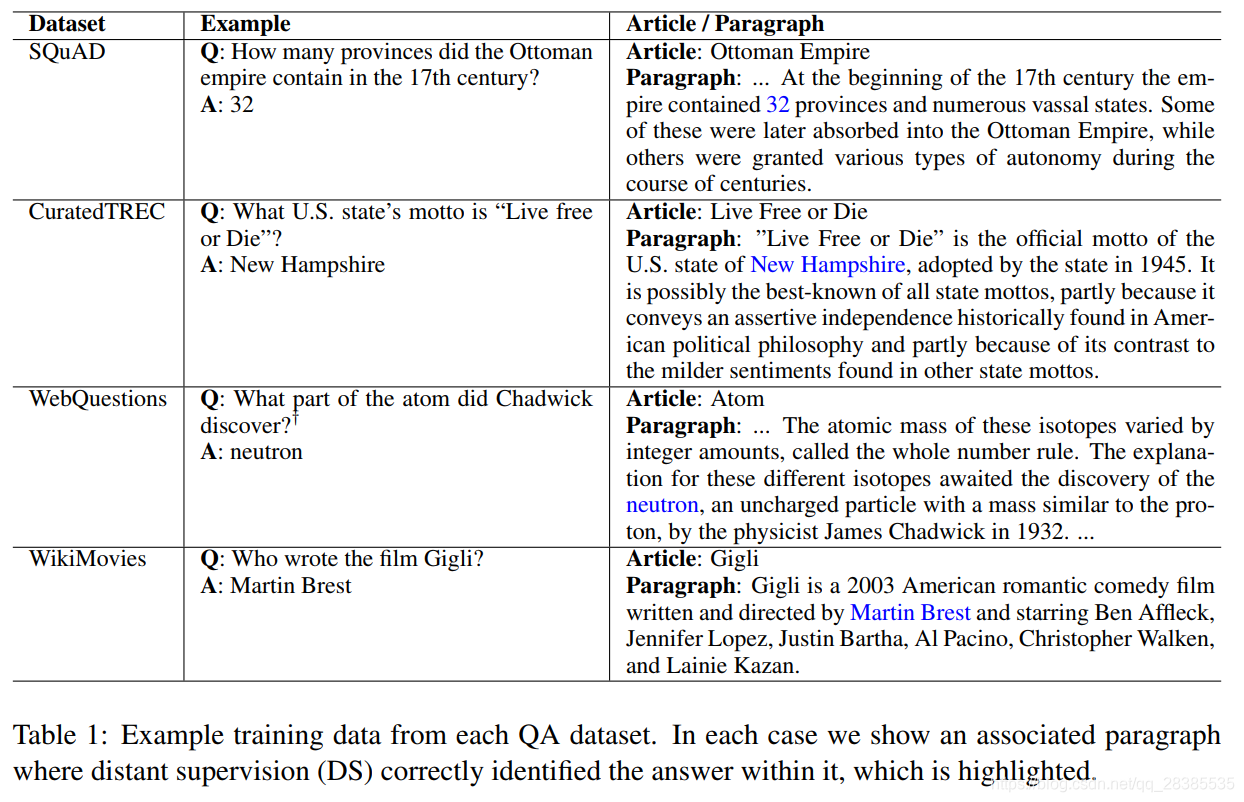
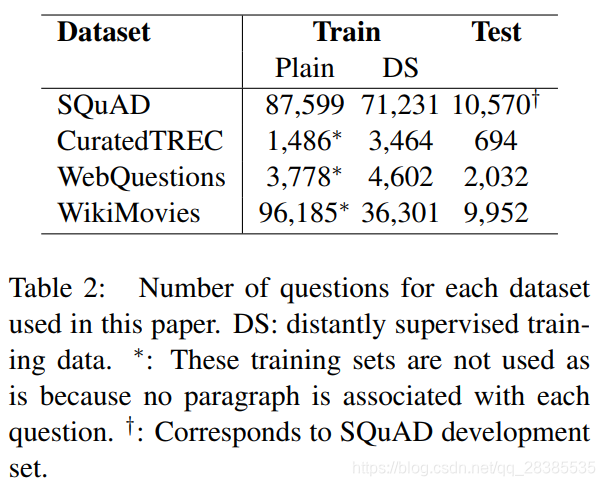
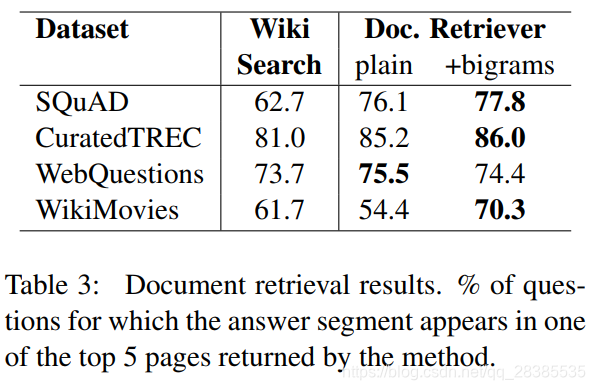
我们的工作依赖于三种类型的数据:(1)Wikipedia是我们寻找答案的知识源;(2)SQuAD数据集是我们训练Document Reader的主要资源;(3)另外三个QA数据集(CuratedTREC,WebQuestions 和WikiMovies),除了SQuAD之外,被用于测试我们整个系统的开放领域QA能力,并评估我们的模型从多任务学习和远程监督中学习的能力。表2给出了数据集的统计信息。
4.1 Wikipedia (Knowledge Source)
我们将英语维基百科的直到2016-12-21的数据转存(网址)用于我们的所有实验,作为用于问答的知识源。对于每一页,仅提取纯文本,并删除所有结构化数据部分,例如列表和图形(代码)。在丢弃内部歧义标签,列表,索引和大纲页面后,我们保留了5,075,182篇文章,其中包括9,008,962个唯一的无大小写字符类型。
4.2 SQuAD
斯坦福问答数据集(SQuAD)是基于Wikipedia的机器理解数据集。数据集包含用于训练的87k个样例和用于开发的10k个样例,以及大型隐藏测试集,只能由SQuAD创建者访问。每个样例都包含从Wikipedia文章中提取的段落以及相关的人工生成的问题。答案始终是本段的跨度,如果模型的预测答案与之匹配,则该模型将获得功劳。使用两个评估指标:精确字符串匹配(EM)和F1分数,该分数在字符级别上测量准确率和召回率的加权平均值。
接下来,对于给定(Rajpurkar et al.,2016)中定义的标准机器理解任务的相关段落,我们使用SQuAD进行训练和评估我们的Document Reader。对于评估通过Wikipedia进行的开放领域问答的任务,我们仅使用SQuAD开发集QA对,并且要求系统在不访问相关段落的情况下找出正确的答案范围。也就是说,在整个维基百科作为资源的条件下,都需要一个模型来回答问题。它没有提供与标准SQuAD设置中相同的段落。
4.3 开放领域QA验证资源
SQuAD是当前可用的最大的通用QA数据集之一。SQuAD问题是通过一个过程收集的,该过程包括向每个人工注释者显示一个段落并要求他们编写问题。结果,它们的分布是非常特定的。因此,我们建议在为开放领域开发的其他数据集上训练和评估我们的数据集,这些数据集已经以不同的方式构造(不一定要在Wikipedia答案的上下文中)。
(1)CuratedTREC
该数据集基于Baudis和Sediv策划的TREC QA任务benchmarks。我们使用大型版本,该版本包含从TREC 1999、2000、2001和2002的数据集中提取的总共2180个问题。
(2)WebQuestions
在(Berant et al.,2013)中引入,此数据集旨在回答Freebase KB中的问题。它是通过以下方式创建的:通过Google Suggest API抓取问题,然后使用Amazon Mechanical Turk获得答案。我们使用实体名称将每个答案转换为文本,以使数据集不引用Freebase ID,而仅由纯文本问题对组成。
(3)WikiMovies
在(Miller et al.,2016)中引入的该数据集在电影领域包含96k个问答对。这些示例最初是从OMDb和MovieLens数据库创建的,因此可以通过使用维基百科的子集作为知识源(电影领域的标题和文章的第一部分)来回答这些示例。
4.4 远程监督数据
上面介绍的所有QA数据集都包含训练部分,但是CuratedTREC,WebQuestions和WikiMovies仅包含问答对,而不是SQuAD中的关联文档或段落,因此不能直接用于训练Document Reader。在先前有关关系抽取的远程监管(DS)的工作之后,我们使用了一种自动将段落与此类训练样相关联的过程,然后将这些示例添加到我们的训练集中。
我们对每个问答对使用以下过程来构建训练集:首先,我们对问题运行文档检索器,以检索Wikipedia上的前5篇文章。这些文章中与已知答案不完全匹配的所有段落将被直接丢弃。短于25个字符或长于1500个字符的所有段落也会被过滤掉。如果在问题中检测到任何命名实体,我们将删除所有根本不包含这些实体的段落。对于每个检索到的页面中的每个其余段落,我们使用问题和20个字符窗口之间的unigram和bigram重叠对与答案匹配的所有位置进行评分,并保持重叠率最高的前5个段落。如果没有非零重叠的段落,则该样例将被丢弃;否则,我们将找到的每个对添加到我们的DS训练数据集中。表1给出了一些示例,表2给出了数据统计。
请注意,我们还可以通过尝试不仅在提供的段落中找到提及的答案,而且从其他页面或给定段落所在的同一页面中找到提及答案的信息,从而为SQuAD生成其他DS数据。我们观察到大约一半的DS样例来自SQuAD中使用的文章之外的页面。