MapReduce框架原理
1.MapReduce的数据流
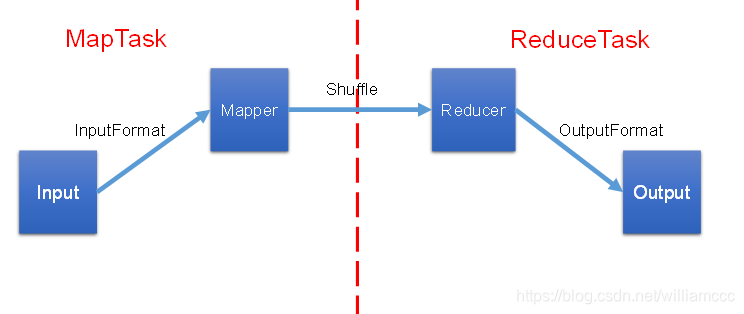
在了解File再如何进入到Mapper之前,我们首先需要了解一个概念:切片。因为切片的数量决定了MapTask的并行度,简单的说就是切片的数量决定了MapTask的数量,一个MapTask会对应一个切片。
2.切片与MapTask并行度决定机制
首先切片是什么呢?
**数据块:**Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
**数据切片:**数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
现在我们了解到,切片是逻辑上的,实际并不会真的把数据块切片。
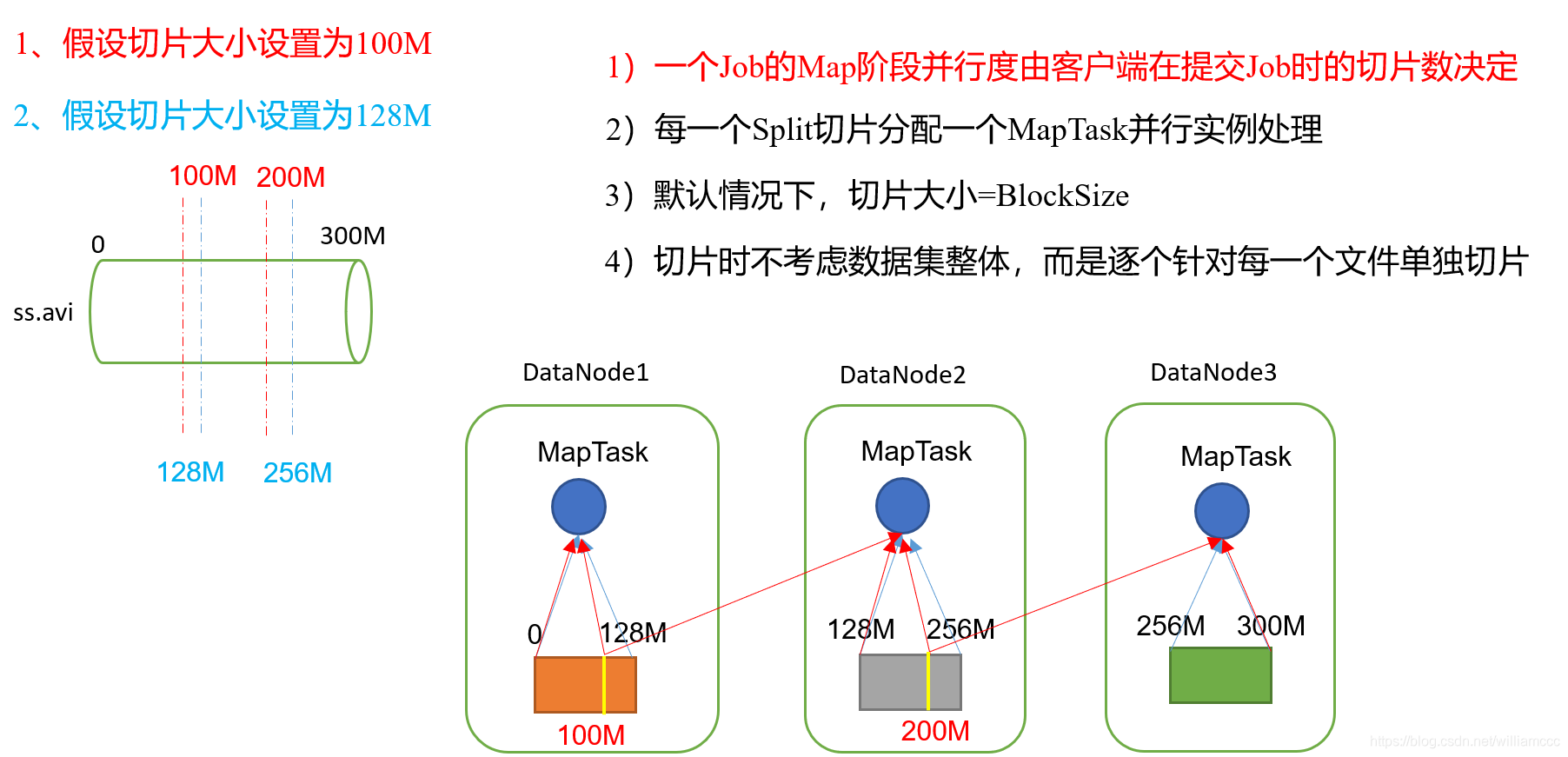
首先我们假设,如果切片大小默认的值为100M,但是我们的实际数据块大小是128M,这样会导致MapTask频繁的访问不同的DataNode,去获取超出100M部分的数据块内容。这会严重到降低MapReduce的计算速度。所以如果 :切片大小 = BlockSize 的话,那么MapTask的启动数量和运行速度都会合理,实际上MapReduce底层源码对于切片的大小也是有公式决定的。另外还需要注意的是,切片是根据文件的,也就是所对一个一个文件单独计算切片数, 各文件之间是独立的。列入File1 = 300M File2 = 1M, 那么300M = 128 + 128 + 44 1M = 1M, 仍然是切四片,不会合并去切。
3.源码中计算切片大小的公式
Math.max(minSize, Math.min(maxSize, blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
minSize: 默认值是1 maxSize: 默认值是long的最大值, 所以可以通过控制这两个参数修改切片大小 (一般blocksize是不建议修改的)
注意1:(Yarn集群模式 默认切片大小是128M,本地模式是32M, 建立连接时会判断运行环境)
因此,默认情况下,切片大小=blocksize
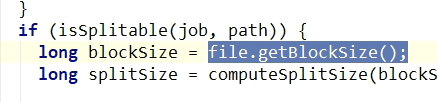
4.FileInputFormat切片源码解析

5.Job提交流程源码详解
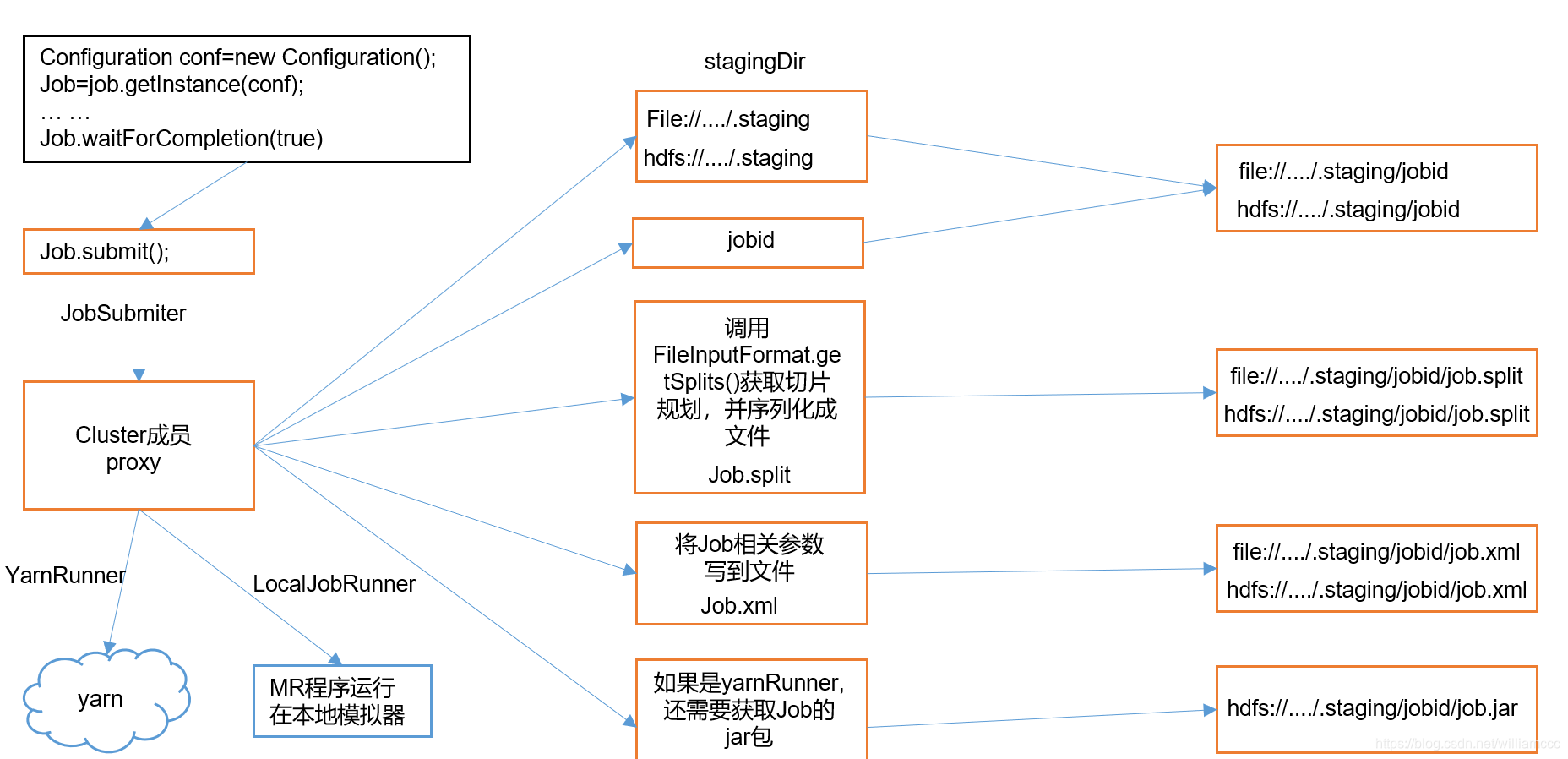
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地运行环境还是yarn集群运行环境
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
//本地模式最终提交的文件有: 切片信息 + .xml 配置信息
//Yarn集群模式最终提交的文件有: 切片信息 + .xml 配置信息 + jar包
6.CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
切片机制
extInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。