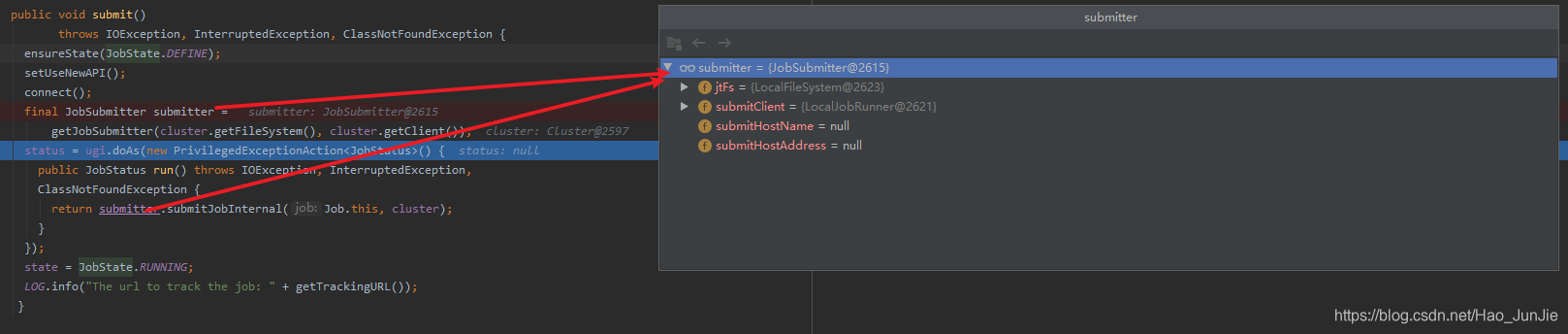
下图是wordCount驱动类,从源码方式看它是如何进行提交的

进入waitForCompletion 方法之后
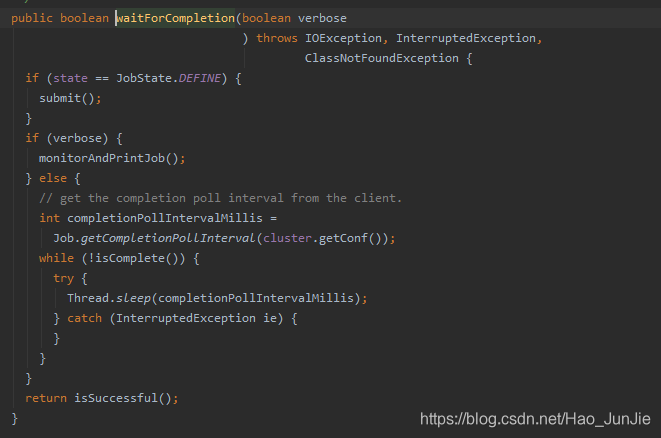
当state为DEFINE 进行submit() 进行提交
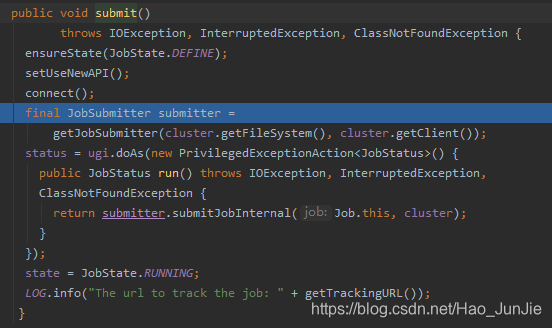
ensureState(JobState.DEFINE):确保job的状态为DEFINE
setUSerNewAPI(); 使用新的API
connect() 建立连接:是提交到YARN集群还是Local 如下图:
进入connect() 方法
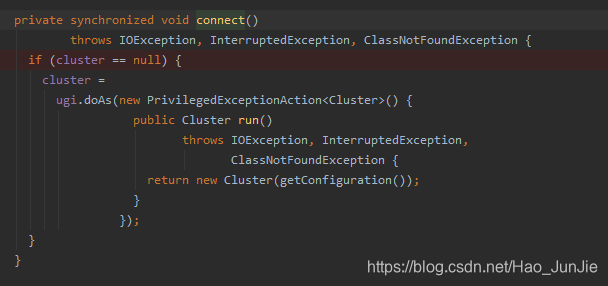
返回Cluster对象:return new Cluster(getConfiguration())

Cluster 调用initialize(jobTrackAddr,conf)
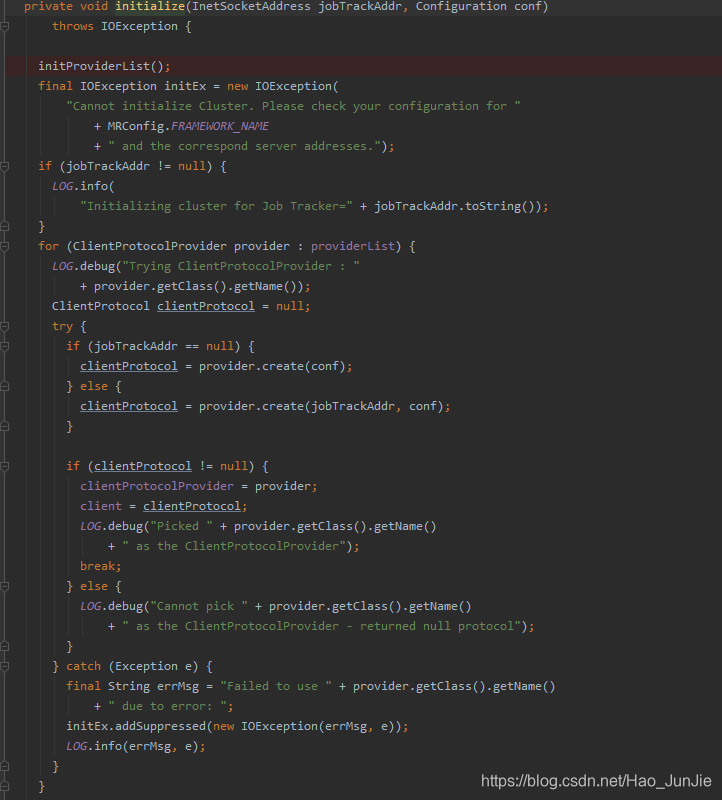
调用 initProviderList(); 初始化提交者
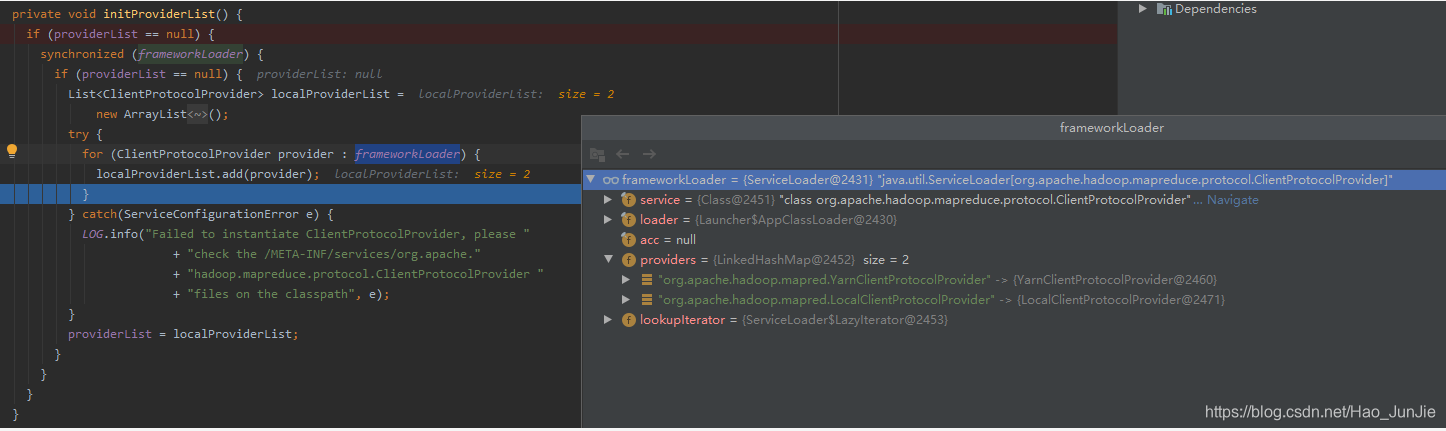
providerList 值为:YarnClientProtocolProvider 和 LocalClientProtocolProvider
继续图六:

进入create(conf)方法 (是个抽象方法)
Yarn的实现:

本地的实现:

如果连接的是Yarn集群 clientProtocol就是 YARNRunner 如果连接的是local clientProtocol就是LocalJobRunner
connect() 方法结束后
进行提交 submitJobInternal(Job.this,cluster):如下代码:截图放不下,改成代码段
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}上述代码段
JobID jobId = submitClient.getNewJobID():获取Jobid ,并创建Job 路径
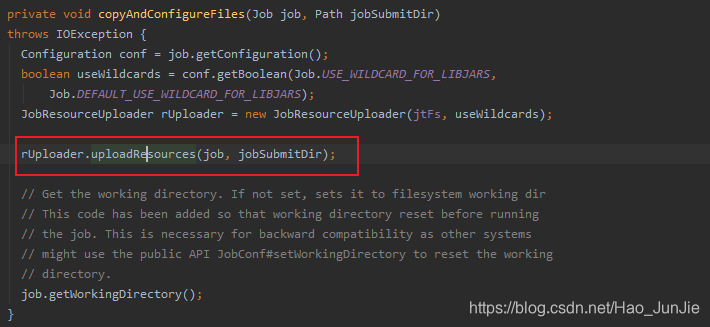
copyAndConfigureFiles(job, submitJobDir):拷贝jar包和配置文件到集群;代码如下图:

由于截图放不下,所以展示代码段:
private void uploadResourcesInternal(Job job, Path submitJobDir)
throws IOException {
Configuration conf = job.getConfiguration();
short replication =
(short) conf.getInt(Job.SUBMIT_REPLICATION,
Job.DEFAULT_SUBMIT_REPLICATION);
if (!(conf.getBoolean(Job.USED_GENERIC_PARSER, false))) {
LOG.warn("Hadoop command-line option parsing not performed. "
+ "Implement the Tool interface and execute your application "
+ "with ToolRunner to remedy this.");
}
//
// Figure out what fs the JobTracker is using. Copy the
// job to it, under a temporary name. This allows DFS to work,
// and under the local fs also provides UNIX-like object loading
// semantics. (that is, if the job file is deleted right after
// submission, we can still run the submission to completion)
//
// Create a number of filenames in the JobTracker's fs namespace
LOG.debug("default FileSystem: " + jtFs.getUri());
if (jtFs.exists(submitJobDir)) {
throw new IOException("Not submitting job. Job directory " + submitJobDir
+ " already exists!! This is unexpected.Please check what's there in"
+ " that directory");
}
// Create the submission directory for the MapReduce job.
submitJobDir = jtFs.makeQualified(submitJobDir);
submitJobDir = new Path(submitJobDir.toUri().getPath());
FsPermission mapredSysPerms =
new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
mkdirs(jtFs, submitJobDir, mapredSysPerms);
if (!conf.getBoolean(MRJobConfig.MR_AM_STAGING_DIR_ERASURECODING_ENABLED,
MRJobConfig.DEFAULT_MR_AM_STAGING_ERASURECODING_ENABLED)) {
disableErasureCodingForPath(submitJobDir);
}
// Get the resources that have been added via command line arguments in the
// GenericOptionsParser (i.e. files, libjars, archives).
Collection<String> files = conf.getStringCollection("tmpfiles");
Collection<String> libjars = conf.getStringCollection("tmpjars");
Collection<String> archives = conf.getStringCollection("tmparchives");
String jobJar = job.getJar();
// Merge resources that have been programmatically specified for the shared
// cache via the Job API.
files.addAll(conf.getStringCollection(MRJobConfig.FILES_FOR_SHARED_CACHE));
libjars.addAll(conf.getStringCollection(
MRJobConfig.FILES_FOR_CLASSPATH_AND_SHARED_CACHE));
archives.addAll(conf
.getStringCollection(MRJobConfig.ARCHIVES_FOR_SHARED_CACHE));
Map<URI, FileStatus> statCache = new HashMap<URI, FileStatus>();
checkLocalizationLimits(conf, files, libjars, archives, jobJar, statCache);
Map<String, Boolean> fileSCUploadPolicies =
new LinkedHashMap<String, Boolean>();
Map<String, Boolean> archiveSCUploadPolicies =
new LinkedHashMap<String, Boolean>();
uploadFiles(job, files, submitJobDir, mapredSysPerms, replication,
fileSCUploadPolicies, statCache);
uploadLibJars(job, libjars, submitJobDir, mapredSysPerms, replication,
fileSCUploadPolicies, statCache);
uploadArchives(job, archives, submitJobDir, mapredSysPerms, replication,
archiveSCUploadPolicies, statCache);
uploadJobJar(job, jobJar, submitJobDir, replication, statCache);
addLog4jToDistributedCache(job, submitJobDir);
// Note, we do not consider resources in the distributed cache for the
// shared cache at this time. Only resources specified via the
// GenericOptionsParser or the jobjar.
Job.setFileSharedCacheUploadPolicies(conf, fileSCUploadPolicies);
Job.setArchiveSharedCacheUploadPolicies(conf, archiveSCUploadPolicies);
// set the timestamps of the archives and files
// set the public/private visibility of the archives and files
ClientDistributedCacheManager.determineTimestampsAndCacheVisibilities(conf,
statCache);
// get DelegationToken for cached file
ClientDistributedCacheManager.getDelegationTokens(conf,
job.getCredentials());
}-------------------------------------复制jar包到集群代码结束--------------------------------

下面开始分析切片源码:
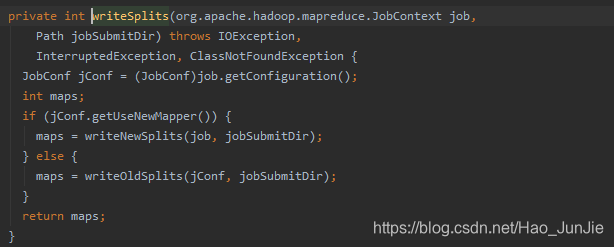
进入writeNewSplit(job,jobSubmitDir)
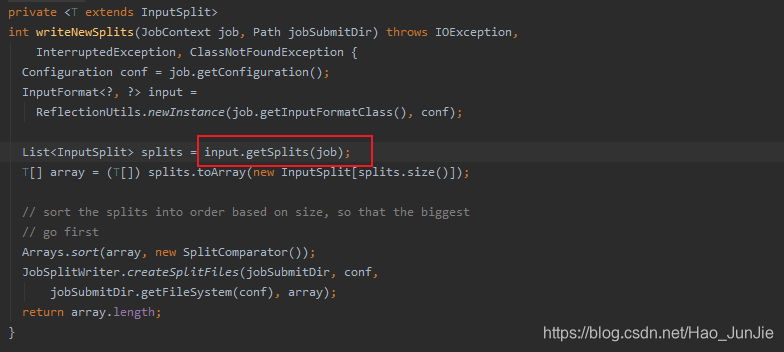
通过反射调用Job的InputFormat,InputFormat是抽象类,它的派生子类图如下:
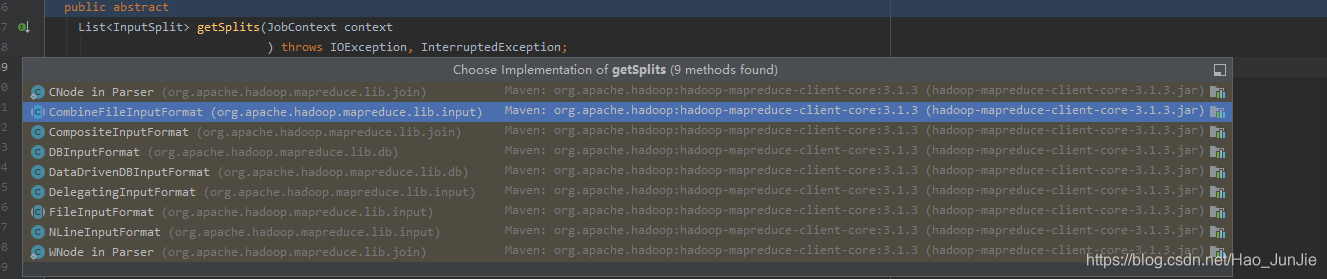
实现类默认是FileInputFormat :代码如下:
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
for (FileStatus file: files) {
if (ignoreDirs && file.isDirectory()) {
continue;
}
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); 对应下面代码:
long maxSize = getMaxSplitSize(job);对应下面代码:
切片大小:
long splitSize = computeSplitSize(blockSize, minSize, maxSize); 对应下面代码:进入computerSplitSize(blocksize,minSize,maxSize);对应下面代码:

切片大小就是blockSize (本地blockSize是32M,hadoop1.x blockSize是64M,hadoop2.x以后blockSize是128M)
具体的切分代码:如下图:
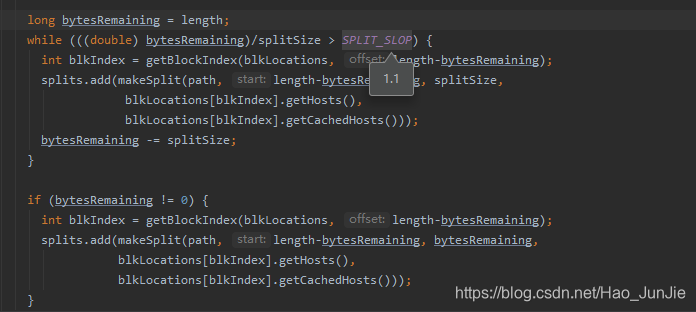
-------------------------------------------------------------------------------------------切片代码结束--------------------------------------------------------------------------------------------
切片规划完了之后,继续回到第一个代码段(回到submitJobInternal()这个方法)

会在conf设置需要启动的MapTask

并向提交jar包的路径写入配置文件。
地址如下:(我是本地提交)


可以看到有一些job的配置信息,和job的切片信息。
提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials()); 如下代码:
status 信息包括job_id,用户名,调度队列,用户名,配置文件位置 等。 如下图:
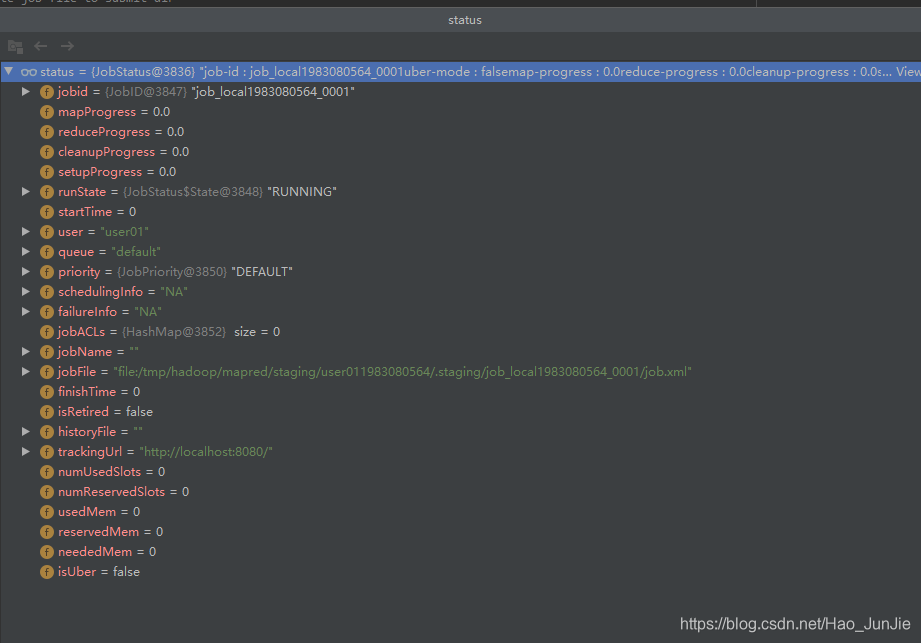
可以结合此图来看: