默认情况下TextInputformat对任务的切片机制是按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个maptask,这样如果有大量小文件,就会产生大量的maptask,处理效率极其低下.
优化策略
1.最好的办法,在数据处理系统的最前端,将小文件先合并成大文件,再传到HDFS做后续分析.
2.补救措施:如果已经是大量小文件再HDFS中了,可以使用另一种InputFormat来做切片也就是
CombineTextInputFormat,它的切片逻辑跟TextInputFormat不同,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个maptask.
实际操作:
MapReduce概述和编写简单案例-01
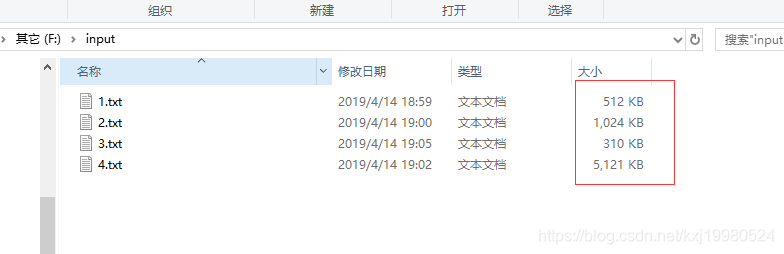
以上面案例为例,初始文件有四个,如果不指定分片直接运行的话,它会分为4片,因为默认是以文件来分片,如果文件大于128兆再按照大小进行分片.
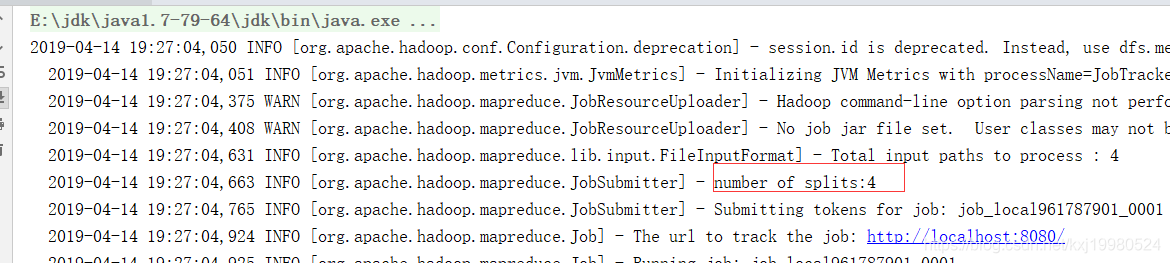
设置自定义分片大小,设置完后分为了两片
上面四个文件大小分别为0.5Mb,1Mb,0.3Mb,5Mb加一块为6.8Mb,下面方法中设置了最大值为4Mb最小值为2Mb,它会安最大值先算,能凑够4Mb算一片,剩下的为1片,设置最小值好像没什么用,反正我测试没啥用,也可以把最大值设置成128Mb,里面的值为long值,1Mb=1*1024*1024,设置成128的时候,输出出来的就是1片了.

import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
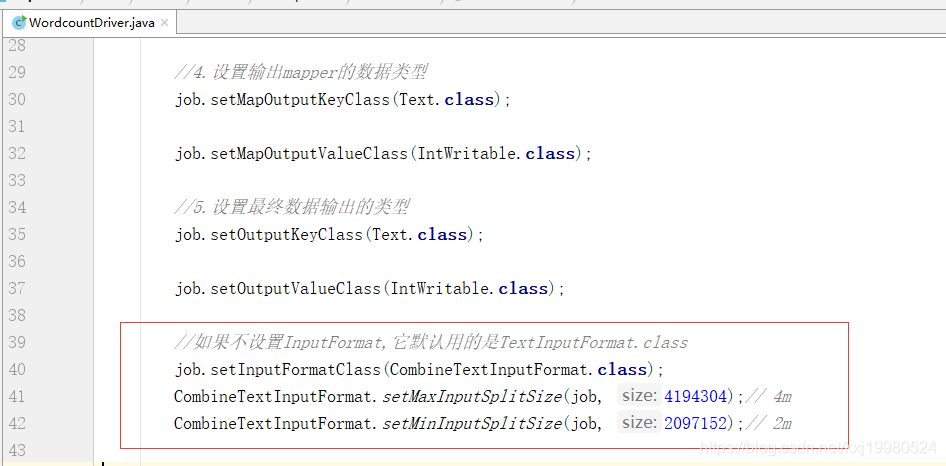
//如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m