MapReduce执行流程中Shuffle机制和Split机制:
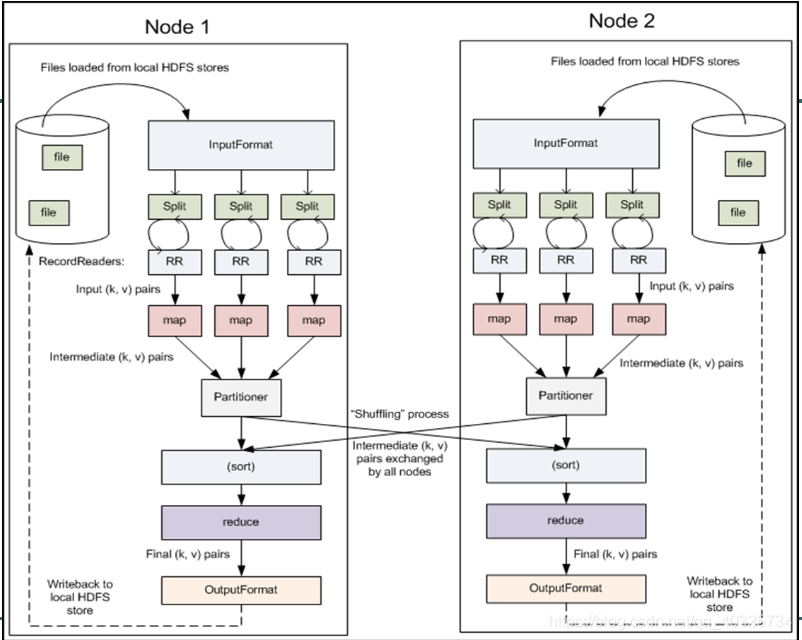
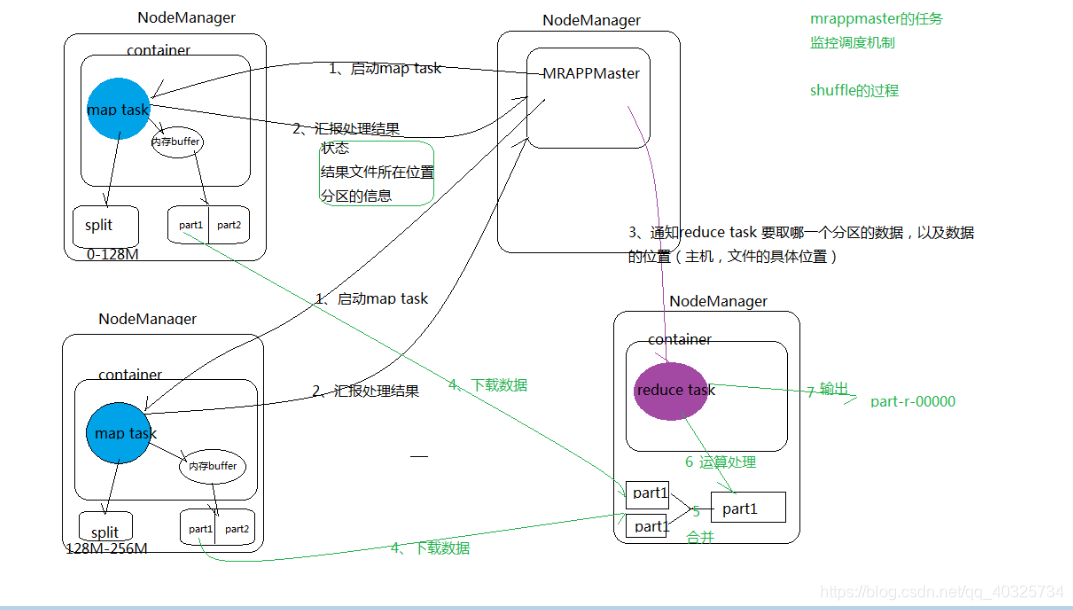
1.MrAppMaster(任务监控调度机制) 向ResourceManager领取任务
2.MrAppMaster分配一些NodeManager节点运行map task任务
3.map task通过 inputFormat的子类FileInputFormat(默认这里可以自义定比如读取图片)遍历所有文件得到blogsize,将多个blogsize的和进行分片后交给map处理(也就是说这里不会管文件有多大,这里是按照配置的每个split大小进行分片)
Split分片参考LINK:https://www.cnblogs.com/wangrd/p/6155313.html
4.RecordReaders的子类(默认,可以自定义在map前对数据进行处理)LineRecordReaders读取split数据输出key,value格式到map
5.map task每个key,value数据经过map业务处理后将结果向缓冲区输出也就是 map shuffle

6.首先对结果进行分组Partitioner(默认按照key分组 key,values([val1,val2]))和写入缓存区,如果缓存区大小到达闸值,将开启一个线程向磁盘中写
7.然后对map的结果在进行排序 默认是字符串key 字典顺序 数字自然顺序
Map-Shuffle:
写入之前先进行分区Partition,用户可以自定义分区(就是继承Partitioner类),然后定制到job上,如果没有进行分区,框架会使用 默认的分区(HashPartitioner)对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理。
将分完区的结果<key,value,partition>开始序列化成字节数组,开始写入缓冲区。
随着map端的结果不端的输入缓冲区,缓冲区里的数据越来越多,缓冲区的默认大小是100M,当缓冲区大小达到阀值时 默认是0.8【spill.percent】(也就是80M),开始启动溢写线程,锁定这80M的内存执行溢写过程,内存—>磁盘,此时map输出的结果继续由另一个线程往剩余的20M里写,两个线程相互独立,彼此互不干扰。
溢写spill线程启动后,开始对key进行排序(Sort)默认的是自然排序,也是对序列化的字节数组进行排序(先对分区号排序,然后在对key进行排序)。
如果客户端自定义了Combiner之后(相当于map阶段的reduce),将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量(Combiner使用一定得慎重,适用于输入key/value和输出key/value类型完全一致,而且不影响最终的结果)
每次溢写都会在磁盘上生成一个一个的小文件,因为最终的结果文件只有一个,所以需要将这些溢写文件归并到一起,这个过程叫做Merge,最终结果就是一个group({“aaa”,[5,8,3]})
集合里面的值是从不同的溢写文件中读取来的。这时候Map-Shuffle就算是完成了。
一个MapTask端生成一个结果文件。8.map task汇报结果给MrAppMaster(状态,结果文件存放位置,分区信息)
9.MrAppMaster 通知reduce task拿map结果数据(那个分区,数据位置等等)
10.reduce task对数据进行排序和分组
Reduce-Shuffle:
接下来开始进行Reduce-Shuffle 阶段。当MapTask完成任务数超过总数的5%后,开始调度执行ReduceTask任务,然后ReduceTask默认启动5个copy线程到完成的MapTask任务节点上分别copy一份属于自己的数据(使用Http的方式)。
这些拷贝的数据会首先保存到内存缓冲区中,当达到一定的阀值的时候,开始启动内存到磁盘的Merge,也就是溢写过程,一致运行直到map端没有数据生成,最后启动磁盘到磁盘的Merge方式生成最终的那个文件。在溢写过程中,然后锁定80M的数据,然后在延续Sort过程,然后记性group(分组)将相同的key放到一个集合中,然后在进行Merge
然后就开始reduceTask就会将这个文件交给reduced()方法进行处理,执行相应的业务逻辑11.reduce task调用OutputFormat(默认是输出到HDFS,这里可以自定义输出到数据库等)将结果进行输出
MapReduce自定义排序:
MR:
package com.sy.hadoop.maperduceFlowSort.sort;
import com.sy.hadoop.maperduceFlowSort.FlowBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.StringUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class SortMR extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("","");
Job job = Job.getInstance(conf);
//设置运行类
job.setJarByClass(SortMR.class);
//设置mapper
job.setMapperClass(SortMapper.class);
//设置reducer
job.setReducerClass(SortReducer.class);
//设置输出key类型
job.setOutputKeyClass(FlowBean.class);
//设置输出value类型
job.setOutputValueClass(NullWritable.class);
//
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
return job.waitForCompletion(true)?0:1;
}
//拿到一行数据,切分出个字段,封装成一个flowbean,作为key输出到缓存,缓存中根据流量最大的key进行排序后顺序输出到reduce中
public static class SortMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = StringUtils.split(value.toString());
String phone = split[0];
long u_flow = Long.parseLong(split[1]);
long d_flow = Long.parseLong(split[2]);
context.write(new FlowBean(phone,u_flow,d_flow),NullWritable.get());
}
}
//排序在map中做,reduce直接输出
public static class SortReducer extends Reducer<FlowBean,NullWritable,FlowBean,NullWritable>{
@Override
protected void reduce(FlowBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new Configuration(),new SortMR(),args));
}
}
FlowBean:
package com.sy.hadoop.maperduceFlowSort;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* map将对象作为key时,实现Comparable接口或者WritableComparable接口重写compareTo方法实现自定义排序方式
*/
public class FlowBean implements Writable,Comparable<FlowBean> {
private String phone;
private Long upFlow;
private Long belowFlow;
private Long flowSum;
public FlowBean(){}
public FlowBean(String phone, Long upFlow, Long belowFlow) {
this.phone = phone;
this.upFlow = upFlow;
this.belowFlow = belowFlow;
this.flowSum = upFlow+belowFlow;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Long getUpFlow() {
return upFlow;
}
public void setUpFlow(Long upFlow) {
this.upFlow = upFlow;
}
public Long getBelowFlow() {
return belowFlow;
}
public void setBelowFlow(Long belowFlow) {
this.belowFlow = belowFlow;
}
public Long getFlowSum() {
return flowSum;
}
public void setFlowSum(Long flowSum) {
this.flowSum = flowSum;
}
/**
* 将本类对象数据序列化到流中
* 此流操作类似一个map数组将数据,自动帮我们划分好顺序
* 反序列化时只需要按照顺序从流中读数据重新赋值即可,不需要我们自己去给他编写具体的序列化和反序列化代码
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeLong(upFlow);
out.writeLong(belowFlow);
out.writeLong(flowSum);
}
/**
* 将流中对象反序列化到对象中
* 此流操作类似一个map数组将数据,自动帮我们划分好顺序
* 反序列化时只需要按照顺序从流中读数据重新赋值即可,不需要我们自己去给他编写具体的序列化和反序列化代码
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.setPhone(in.readUTF());
this.setBelowFlow(in.readLong());
this.setFlowSum(in.readLong());
this.setUpFlow(in.readLong());
}
/**
* 默认是大的排前面
* this.flowSum > o.flowSum ? 1:-1;
* 但是我们这里是小的排前面
* this.flowSum > o.flowSum ? -1:1;
* @param o
* @return
*/
@Override
public int compareTo(FlowBean o) {
return this.flowSum > o.flowSum ? -1:1;
}
}
自定义分组:
MR:
package com.sy.hadoop.ii;
import com.sy.hadoop.maperduceFlowSort.sort.SortMR;
import com.sy.hadoop.mrAreaPartition.AreaPartitioner;
import com.sy.hadoop.mrAreaPartition.FlowBean;
import com.sy.hadoop.mrAreaPartition.FlowSumArea;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class InverseIndexStepOne extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.job.jar","wc.jar");
Job job = Job.getInstance(conf);
//配置jar运行类
job.setJarByClass(InverseIndexStepOne.class);
//配置map类
job.setMapperClass(StepOneMapper.class);
//配置reduce类
job.setReducerClass(StepOneReducer.class);
//设置我们自定义的map分组策略类
job.setPartitionerClass(AreaPartitioner.class);
//自定义reducer并发任务数,和分组数量保持一致,如果reducer任务设置比分组数量小且不等于1那么会报错,
// 如果reducer任务设置等于1(默认)那么还是全部走一个reduce,如果大于那么会输出空结果文件
job.setNumReduceTasks(6);
//配置map输出key类型
job.setMapOutputKeyClass(Text.class);
//配置map输出value类型
job.setMapOutputValueClass(LongWritable.class);
//通用配置如果map输出key和输出value和reduce一样那么就不用配置上面的,如果不一样就需要使用它单独配置reduce配置
//配置reduce输出key类型
job.setOutputKeyClass(Text.class);
//配置reduce输出value类型
job.setOutputValueClass(LongWritable.class);
//配置log输入文件目录(map读取文件)
FileInputFormat.setInputPaths(job, new Path(args[0]));
//输出文件目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//启动job
return job.waitForCompletion(true)?0:1;
}
public static class StepOneMapper extends Mapper<LongWritable, Text,Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] splits = StringUtils.split(line, "\t");
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String name = fileSplit.getPath().getName();
for (String s : splits) {
context.write(new Text(s + "->" + name), new LongWritable(1));
}
}
}
public static class StepOneReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value:values){
count+=value.get();
}
context.write(key,new LongWritable(count));
}
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new Configuration(),new SortMR(),args));
}
}
自定义分组Partitioner实现类AreaPartitioner:
package com.sy.hadoop.mrAreaPartition;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
/**
* 自定义mapper分组
* @param <KEY>
* @param <VALUE>
*/
public class AreaPartitioner<KEY,VALUE> extends Partitioner {
private static HashMap<String,Integer> hashMap = new HashMap<>();
static{
loadAreaHashMap(hashMap);
}
@Override
public int getPartition(Object key, Object value, int numPartitions) {
//从key中拿到手机号,查询手机号归属地字典,不同省份返回不同组号
//这里需要我们先把分组表加载到内存中,然后每次从内存中去对应组号(每一个key会取一次,如果不在初始化时加载到内存中对数据库压力过大)
Integer i = hashMap.get(key.toString().substring(0, 3));
return i==null?5:i;
}
/**
* 初始化时调用一次
* 在这里可以假设分组表在数据库中,可以在此方法读出来放置到hashMap变量中
* @param hashMap
*/
public static void loadAreaHashMap(HashMap<String,Integer> hashMap){
hashMap.put("135",0);
hashMap.put("136",1);
hashMap.put("137",2);
hashMap.put("138",3);
hashMap.put("139",4);
}
}
参考:
