一.网页分析
首先打开歌曲评论首页,右键查看源码后没有发现评论数据且点击下一页后网页URL并没有发生变化,由此可以断定评论数据是通过动态方式来进行加载的。于是我又打开了开发者工具,点击评论第2页的按钮,结果在下图所示的返回文件中我发现了评论数据:

点击该文件,即可提取到请求URL如下:
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=268352018&cmd=8&needmusiccrit=0&pagenum=1&pagesize=25&lasthotcommentid=song_268352018_3266388437_1596118940&domain=qq.com&ct=24&cv=10101010
我们可以复制该URL到浏览器进行搜索,可以看到一个JSON对象,其中所有的数据都在commentlist中:
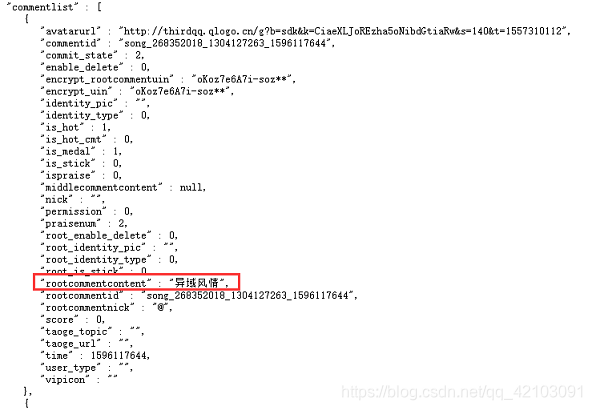
因此,我们只需要请求该文件不断获取评论所在的JSON对象即可,然后我又点击了几个评论页按钮,下面截取其中两个对比如下:
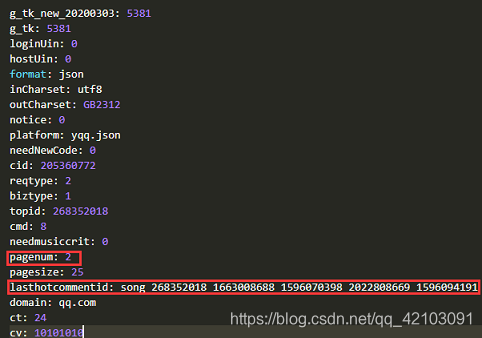
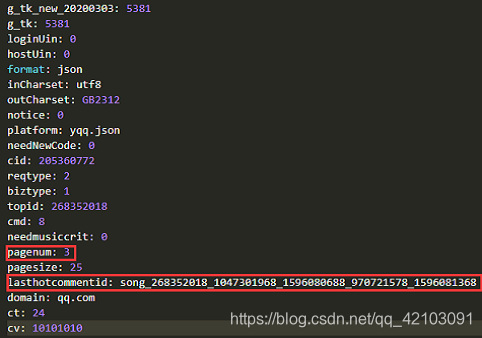
可以发现querystring中变化的只有pagenum和lasthotcommentid,其中pagenum是页码,lasthotcommentid是最后一条评论的id。对于pagenum只需要加1即可,但对于lasthotcommentid可以通过评论所在的json对象中commentlist的最后一条评论的id——commentid获取。
二.评论数据获取
在获取到json数据后,我们可以如下代码获取到评论列表:
#response.text为请求响应的数据
commentlist = json.loads(response.text)["comment"]["commentlist"]
可知commentlist列表中每个元素都包含一条评论,又因为该元素的数据类型是字典,我们可以通过如下方式获取评论数据:
#chinese = '[\u4e00-\u9fa5]+' #提取中文汉字的pattern
for item in commentlist:
c_org = item.get("rootcommentcontent")
if c_org == "该评论已经被删除":
continue
#只提取中文
comment = "".join(regex.findall(chinese,c_org)) if c_org != None else ""
注:在爬取的过程中我发现部分评论数据被删除,原来的评论被官方的字符串"该评论已经被删除"替代,因此我在这里加上了条件语句筛选该结果。
三.词云生成
对于评论数据的可视化,我采用的是wordcloud模块来生成词云图,但在生成词云图之前我们需要对中文评论进行分词和删除停用词。其中分词采用jieba分词,而停用词列表可以通过链接获取,然后将该txt文件读取加载为停用词列表stop_words,对应功能的部分示例代码如下:
def DeleteStopWrods(g_list,stop_words):
"""
功能:删除中文停词
g_lst:分词结果
stop_words:分词结果
"""
outcome = []
for term in g_list:
if term not in stop_words:
outcome.append(term)
return outcome
seg_list = jieba.cut(comment) #jieba分词
comment = " ".join(DeleteStopWrods(seg_list,stop_words)) #删除停用词
在进行上述处理后,就可以调用wordcloud模块生成词云图,示例代码如下:
def WordCloudImage(file_path='mojito.txt'):
"""
功能:生成词云图
file_path:评论文件路径
"""
wc = WordCloud(font_path="E:\WordCloud_Font\simhei.ttf",background_color='white',collocations=False,
width=600,height=300,max_words=100)
with open(file_path,'r',encoding='UTF-8') as f:
string = f.read()
wc.generate(string)
wc.to_file('wc_mojito.png')
需要注意的是wordcloud默认的字体是英文,因此在生成中文词云前需要先去下载一种中文字体,然后指定参数font_path为自己下载字体所在路径,中文字体下载地址如下:
四.完整示例程序
from wordcloud import WordCloud
import requests
import json
import regex
import jieba
import traceback
chinese = '[\u4e00-\u9fa5]+' #提取中文汉字的pattern
root_url = "https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg"
querystring = {
"g_tk_new_20200303": "5381",
"g_tk": "5381",
"loginUin": "0",
"hostUin": "0",
"format": "json",
"inCharset": "utf8",
"outCharset": "GB2312",
"notice": "0",
"platform": "yqq.json",
"needNewCode": "0",
"cid": "205360772",
"reqtype": "2",
"biztype": "1",
"topid": "268352018",
"cmd": "8",
"needmusiccrit": "0",
"pagenum": "0",
"pagesize": "25",
"lasthotcommentid": "song_268352018_1663008688_1596070398_1335842063_1596080731",
"domain": "qq.com",
"ct": "24",
"cv": "10101010"
}
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/84.0.4147.105 Safari/537.36"
}
proxies = {
'http':'116.12.74.81:8080'
}
def LoadStopWords(file_path = '中文停用词词表.txt'):
"""
功能:加载中文停用词列表
file_path:停用词表所在路径
"""
stopwords = []
with open(file_path,'r') as f:
text = f.readlines()
for line in text:
stopwords.append(line[:-2])#去换行符
return stopwords
def DeleteStopWrods(g_list,stop_words):
"""
功能:删除中文停词
g_lst:分词结果
stop_words:分词结果
"""
outcome = []
for term in g_list:
if term not in stop_words:
outcome.append(term)
return outcome
def Spider(stop_words,nums = 5118):
"""
功能:爬虫主程序
stop_words:中文停用词表
nums:评论占用的页数
返回值:clist,即评论列表
"""
pagenum,lasthotcommentid = 0,"song_268352018_1663008688_1596070398_1335842063_1596080731" #初始化参数
clist = [] #保存评论的列表
while pagenum < nums:
try:
print("正在爬取第{}页".format(pagenum + 1))
querystring["pagenum"] = str(pagenum)
querystring["lasthotcommentid"] = lasthotcommentid
response = requests.get(url=root_url,headers=headers,params=querystring,proxies=proxies)
commentlist = json.loads(response.text)["comment"]["commentlist"]
if response.status_code == 200:#成功响应
pagenum += 1
lasthotcommentid = commentlist[-1]["commentid"]
for item in commentlist:
c_org = item.get("rootcommentcontent")
if c_org == "该评论已经被删除":
continue
#只提取中文
comment = "".join(regex.findall(chinese,c_org)) if c_org != None else ""
seg_list = jieba.cut(comment) #jieba分词
comment = " ".join(DeleteStopWrods(seg_list,stop_words))
#print(comment)
clist.append(comment + " ")
except Exception:
print("第{}页爬取失败!!!".format(pagenum))
traceback.print_exc()
return clist
def Saver(clist,save_path = "mojito.txt"):
"""
功能:评论为txt文件
clist:评论列表
save_path:保存文件路径
"""
with open(save_path,'w',encoding="UTF-8") as f:
f.writelines(clist)
def WordCloudImage(file_path='mojito.txt'):
"""
功能:生成词云图
file_path:评论文件路径
"""
wc = WordCloud(font_path="E:\WordCloud_Font\simhei.ttf",background_color='white',collocations=False,
width=600,height=300,max_words=100)
with open(file_path,'r',encoding='UTF-8') as f:
string = f.read()
wc.generate(string)
wc.to_file('wc_mojito.png')
if __name__ == "__main__":
stop_words = LoadStopWords()
clist = Spider(stop_words)
Saver(clist)
WordCloudImage()
上述的代理ip可能无效了,可以自己去想办法获取,在经过上述结果后获取到的词云图如下所示:

可以看出在评论中"周杰伦",“好听”,“啊啊啊”,"音乐"等评价出现的频率最高,全部代码及数据获取可见mojito_demo(求star)。
以上便是本文的全部内容,如果觉得不错可以支持一下博主,你们的支持是我创作下去的不竭动力!!!