一、项目简介
1.1 项目博客地址
https://www.cnblogs.com/venus-ping/
1.2 项目完成的功能与特色
利用爬虫对豆瓣评分top250的电影进行爬取,获取电影相关信息,并对获取到的数据进行数据可视化。获取到的数据信息分别为:抓取top250电影的上映时间、国家、评分、类型、评价人数、导演、参演演员;实现上映国家分布、影片类型比重、前10导演作品数以及优秀演员参演作品数量的数据可视化。
1.3 项目采用的技术栈
使用软件:Visual Studio Code、JetBrains PyCharm
采用技术:pyecharts、MongoDB、python第三方库
1.4 项目借鉴源代码的地址
python爬虫—豆瓣电影top250及数据可视化 https://www.jianshu.com/p/deaf10d4fd9b
1.5团队成员任务分配表
陈佳萍 对爬取到的top250影片信息,实现top10导演作品数量、电影类别比重和数据可视化
吴琳琳 设计实现top250影片信息爬取、上映国家分布的数据可视化
肖茹云 对爬取到的top250影片信息,实现评论人数、优秀演员参演作品数量的数据可视化
二、项目的需求分析
针对影视作品越来越多,层次不穷,通过对豆瓣top250影片爬取和分析,更加直观选择观看影片。
三、项目功能架构图、主要功能流程图
1.1 功能架构图

图1 功能架构图
1.2 主要功能流程图
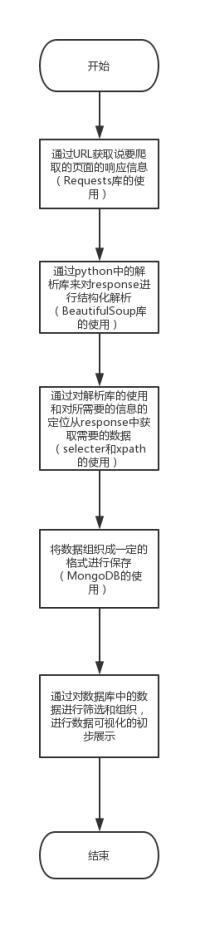
图2 爬虫爬取

图3 country信息分析
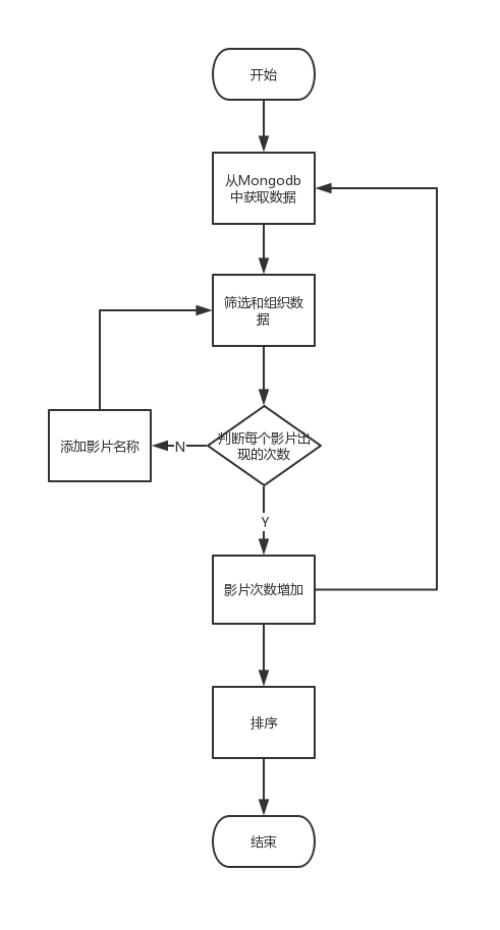
图4 mvtop250影片信息

图5 top10导演
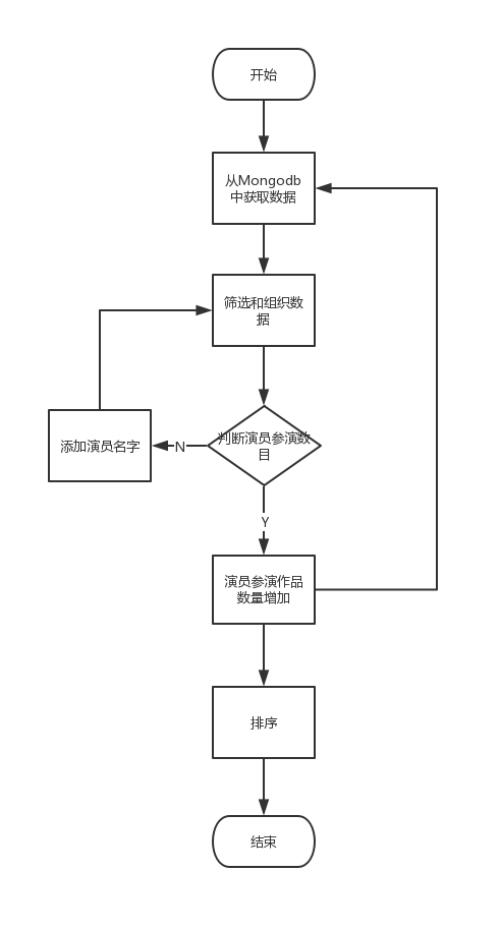
图6 yanyuan
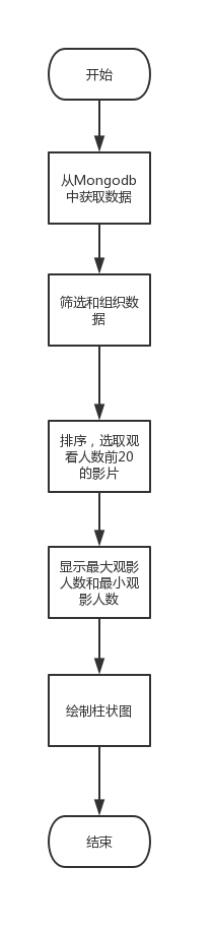
图7 category
四、系统模块说明
1.1 系统模块列表
图8 项目结构图
1.2 各模块详细描述(名称,功能,运行截图,关键源代码)
1、mvtop250.py :实现对豆瓣top250的影片信息爬取
1) 构建递归循环,逐页爬取

2) 建立Mongodb连接,用于数据保存
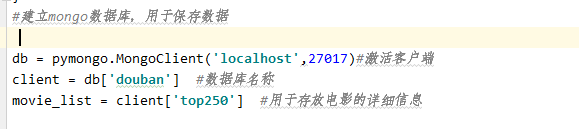
3) 抓取top250电影的上映时间、国家、评分、类型、评价人数
def get_movie_list(url,headers):
# 实例化soup对象, 便于处理
soup = requests.get(url,headers=headers) #向网站发起请求,并获取响应对象
response = BeautifulSoup(soup.text,'lxml')#利用xml html解析器,具有容错功能
lists = response.select('div.info')
#循环获取信息
for list in lists:
#获取链接, 也就是获取a链接中href对应的值;
sing_url =list.select('a')[0].get('href')
#获取影片名称
name =list.select('div.hd .title')[0].text
#导演及主演
type_list = list.select('div.bd p')[0].text.strip('').split('...')[-1].replace(' ','').split('/')
#上映时间
year =type_list[0]
#国家
country = type_list[1]
#影片所属类别
category = type_list[2]
#获取影片评分
star = list.select('div.bd .star .rating_num')[0].text.replace(' ','')
#获取引述
quote =list.select('div.bd .quote')[0].text
#获取评论人数
people_num = list.select('div.bd .star span:nth-of-type(4)')[0].text.split('人')[0]
get_detail_movie(sing_url,name,year,country,category,star,quote,people_num,headers)
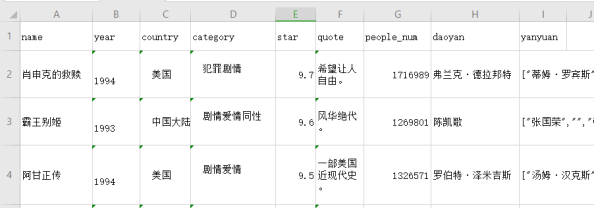
4) 抓取top250电影的执导导演、参演演员,并保存数据到mongodb中

我们将获取到影片信息数据保存到数据库中,以便后面对数据的分析,效果如下:
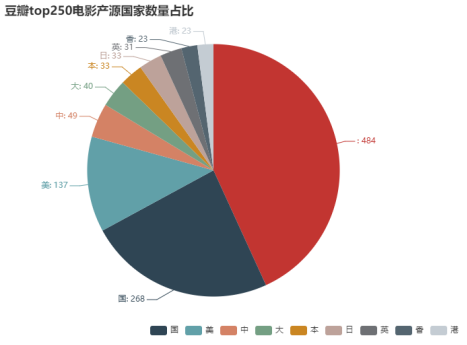
2、country.py :构建top250电影中出自国家最多的20个国家的列表
1)构建top250电影中出自国家最多的20个国家的列表
#建立国家列表
country_list =[]
#循环查找国家名
for i in item_info.find():
if '导' not in i['country']:
for j in i['country']:
if j !='':
#插入获得信息,放入列表
country_list.append(str(j).strip('\xa0'))
country_list1 = list(set(country_list))
append_list=[]
for i in country_list1:
list11 =[]
list11.append(str(i))
list11.append(country_list.count(i))
append_list.append(list11)
#排序
list22 = sorted(append_list,key =lambda d:d[1],reverse=True)[:10]
2) 绘制饼状图
c = (Pie().add("",
[list(z) for z in zip(list(a[0] for a in list22),list(a[1] for a in list22) )],
center=["35%", "50%"])
.set_global_opts(
title_opts=opts.TitleOpts(title="豆瓣top250电影产源国家数量占比"),
legend_opts=opts.LegendOpts(pos_bottom='0'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))
c.render('country.html')# 使用 render() 渲染生成 .html 文件
效果如下:
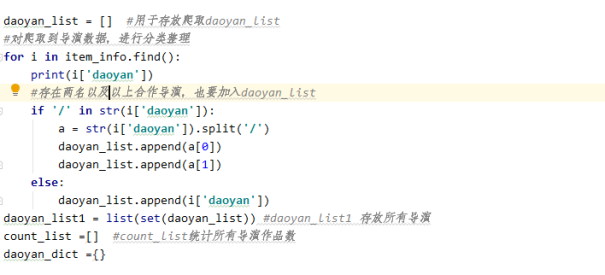
3、top10导演.py :对爬取到的信息进行分类整理,统计作品数前10的导演,以及数据可视化
1)统计所有导演数量
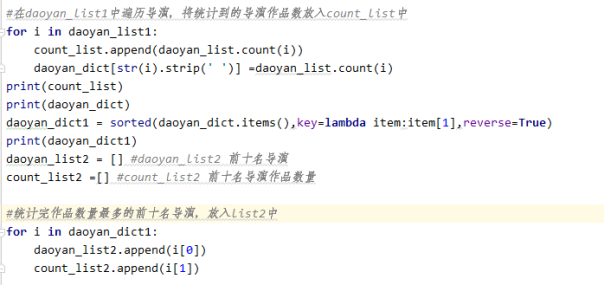
2)统计作品数前10导演
3)绘制柱状图
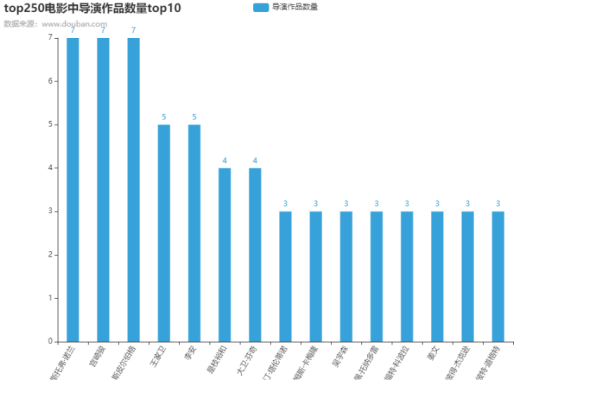
4)效果如下

4、category.py:影片类型比重
1)对爬取到影片进行分类整理,放入list列表中

2)针对分类列表进行递归循环,相同类型的影片数量count+1
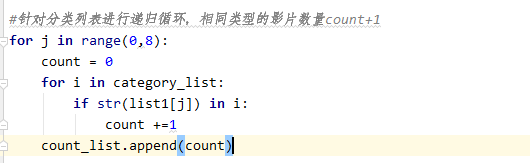
3) 绘制饼状图
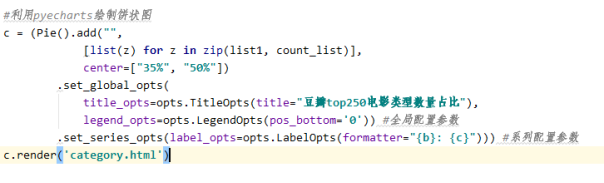
效果如下:
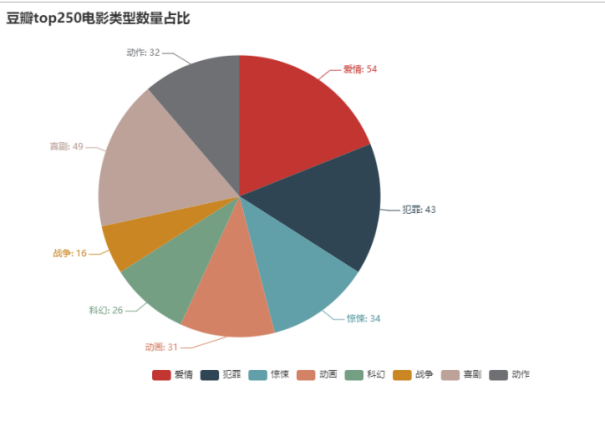
由饼状图可知,爱情类的影片更受观众喜欢。
5、people.py:评论人数分析
1)对爬取的影片评论人数进行分析
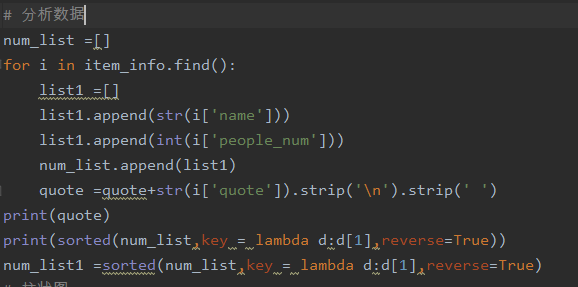
2)绘制柱状图
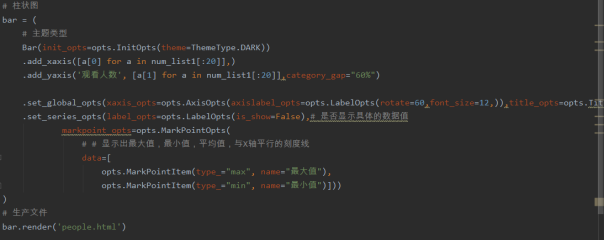
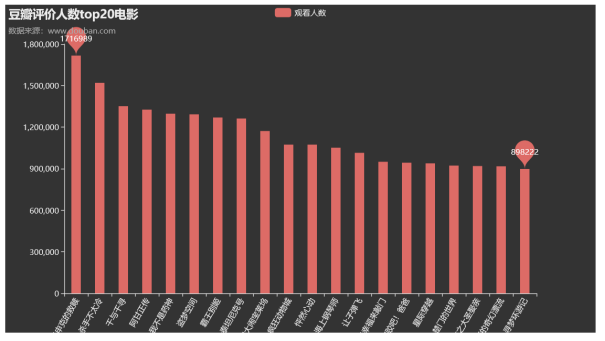
效果如下:

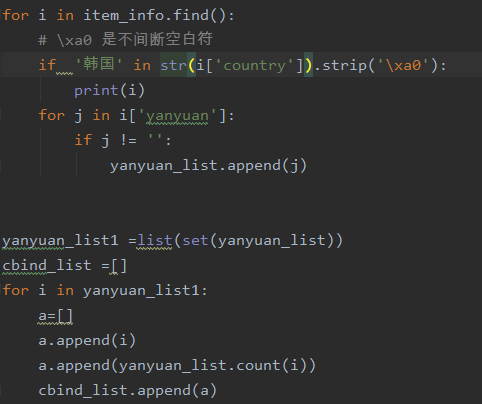
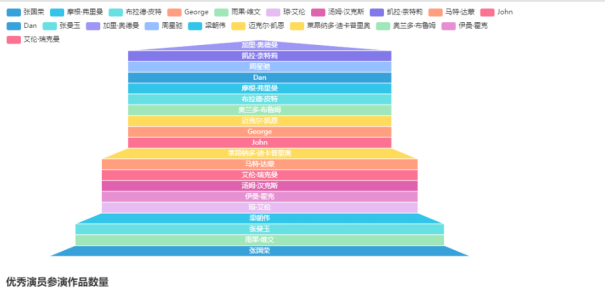
6、yanyuan.py:分析优秀演员参演作品数量
1)对获取到的演员列表进行分析
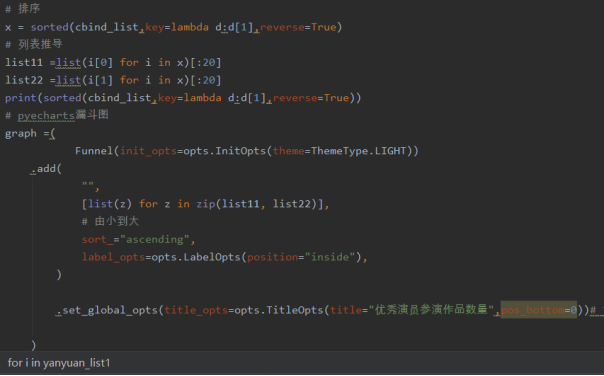
2)绘制漏斗图
效果如下:
五、项目总结
5.1 特点
利用不同的技术,实现爬取,数据保存,数据可视化。使用mongodb存放数据,利用pyecharts包实现数据可视化。使用 render() 渲染生成html文件后,创建index文件将所有渲染的html文件进行连接。
5.2 不足之处
1.爬取数据数量有限。
2.数据量大,爬取速度慢。
3.无法识别链接重要程度,不能判断网页数据的价值程度。
4.使用Mongodb作为数据存储,而不是用MySQL