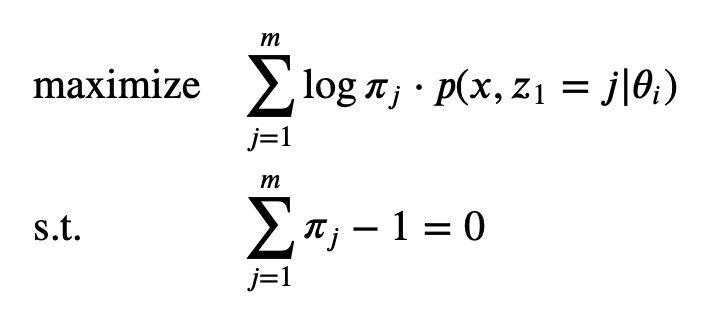Before reading this post, make sure you are familiar with the EM Algorithm and decent among of knowledge of convex optimization. If not, please check out my previous post
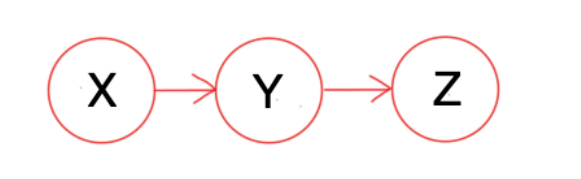
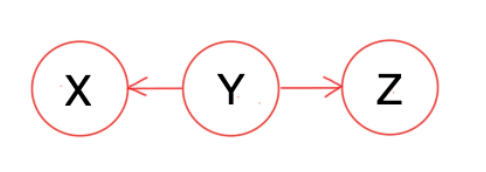
A and B are conditionally independent given C if and only if, given knowledge that C occurs, knowledge of whether A occurs provides no information on the likelihood of B occurring, and knowledge of whether B occurs provides no information on the likelihood of A occurring.
Formally, if we denote conditional independence of A and B given C by (A⊥⊥B)∣C, then by definition, we have
(A⊥⊥B)∣C⟺P(A,B∣C)=P(A∣C)⋅P(B∣C)
Given the knowledge that C occurs, to show the knowledge of whether B occurs provides no information on the likelihood of A occurring, we have
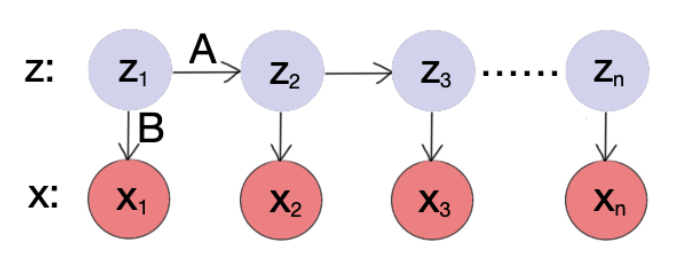
The HMM is based on augmenting the Markov chain. A Markov chain is a model that tells us something about the probabilities of sequences of random variables, states, each of which can take on values from some set. A Markov chain makes a very strong assumption that if we want to predict the future in the sequence, all that matters is the current state.
To put it formally, suppose we have a sequence of state variables z1,z2,...,zn. Then the Markov assumption is
p(zn∣z1z2...zn−1)=p(zn∣zn−1)
A Markov chain is useful when we need to compute a probability for a sequence of observable events. However, in many cases the events we are interested in are hidden. For example we don’t normally observe part-of-speech (POS) tags in a text. Rather, we see words, and must infer the tags from the word sequence. We call the tags hidden because they are not observed.
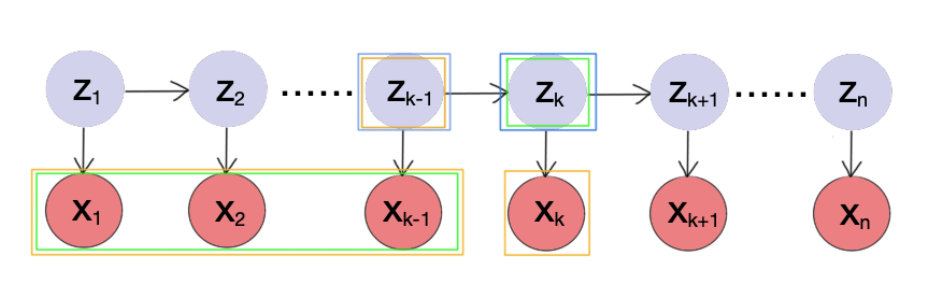
A hidden Markov model (HMM) allows us to talk about both observed events (like words that we see in the input) and hidden events (like part-of-speech tags) that we think of as causal factors in our probabilistic model. An HMM is specified by the following components:
A sequence of hidden states z, where zk takes values from all possible hidden states Z={1,2,..,m}.
A sequence of observations x, where x=(x1,x2,...,xn). Each one is drawn from a vocabulary V.
A transition probability matrix A, where A is an m×m matrix. Aij represents the probability of moving from state i to state j: Aij=p(zt+1=j∣zt=i), and ∑j=1mAij=1 for all i.
An emission probability matrix B, where B is an m×∣V∣ matrix. Bij represents the probability of an observation xj being generated from a state i: Bij=P(xt=Vj∣zt=i)
An initial probability distribution π over states, where π=(π1,π2,...,πm). πi is the probability that the Markov chain will start in state i. ∑i=1mπi=1.
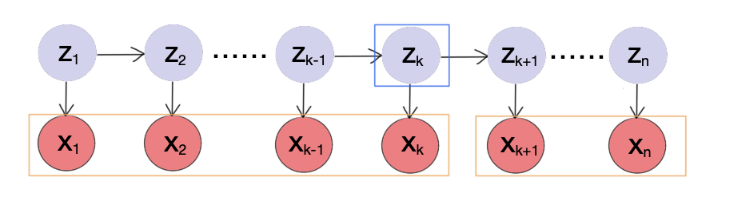
Given a sequence x and the corresponding hidden states z (like one in the picture above), we have
We get p(z1) from π, p(zk+1∣zk) from A, and p(xk∣zk) from B.
Useful probabilities p(zk∣x) and p(zk+1,zk∣x)
p(zk∣x) and p(zk+1,zk∣x) are useful probabilities and we are going to use them later.
Intuition: Once we have a sequence x, we might be interested in find the probability of any hidden state zk, i.e., find probabilities p(zk=1∣x),p(zk=2∣x),...,p(zk=m∣x). we have the following
p(zk∣x)=p(x)p(zk,x)∝p(zk,x)(1)(2)
Note that from (1) to (2), since p(x) doesn’t change for all values of zk, p(zk∣x) is proportional to p(zk,x).
From the above graph, we see that the second term (3) is the 2nd classical cases. So xk+1:n and x1:k are conditionally independent. This is why we can go from (3) to (4.1). We are going to use the Forward Algorithm to compute p(zk,x1:k), and Backward Algorithm to compute p(xk+1:n∣zk) later.
We denote p(zk,x1:k) by αk(zk) and p(xk+1:n∣zk) by βk(zk).
After we know how to calculate these two terms separately, we can calculate p(zk∣x) easily by introducing a normalization term. That is,
Note that we can find the third and the forth term from the transition probability matrix and the emission probability matrix. Again, we can calculate p(zk+1,zk∣x) simply by introducing a normalization term. That is,
Problem 1 (Likelihood): Given an observation sequence x and parameters θ=(A,B,π), determine the likelihood p(x∣θ).
Problem 2 (Learning): Given an observation sequence x, learn the parameters θ=(A,B,π).
Problem 3 (Inference): Given an observation sequence x and parameters θ=(A,B,π), discover the best hidden state sequence z.
Problem 1 (Likelihood)
Goal: Given an observation sequence x and parameters θ=(A,B,π), determine the likelihood p(x∣θ).
Naive Way:
From (0), we have already know how to compute P(x,z∣θ), so we can compute p(x∣θ) by summing all possible sequence z:
p(x∣θ)=z∑P(x,z∣θ)⋅p(z∣θ)
This method is not applicable since there are mn ways of combinations of sequence z. So we introduce the following two algorithm: Forward Algorithm and Backward Algorithm.
Forward Algorithm
Goal: Compute p(zk,x1:k), given θ=(A,B,π).
From the picture above, it’s natural to compute p(zk,x1:k) by dynamic programming (DP). That is, to calculate it in terms of p(zk−1,x1:k−1):
In equation (9), the term p(zk∣zk−1) is the transition probability from state zk−1 to state zk; the term p(xk∣zk) is the emission probability of observing xk given state zk.
α1(z1=q)=p(z1=q,x1)=πq⋅p(x1∣z1=q), where p(x1∣z1=q) is an emmission probability.
Knowing how to compute p(zk,x1:k) recurssively, we have
In equation (12), the term p(zk+1∣zk) is the transition probability from state zk to state zk+1; the term p(xk+1∣zk+1) is the emission probability of observing xk+1 given state zk+1.
βn(zn)=1.
Knowing how to compute p(xk+1:n∣zk) recursively, we have
From (13) to (14), we use the conditional independence. To make it clean, I didn’t include θ in the above derivation, but keep in mind x is conditioned on θ.
Problem 2 (Learning)
Goal: Given an observation sequence x, learn the parameters θ=(A,B,π).
Given that the hidden states are unknown, it’s natural to use the EM Algorithm to solve parameters. Remind that the EM Algorithm consists of two steps:
An expectation (E) step, which creates a function Q(θ,θi) for the expectation of the log-likelihood logp(x,z∣θ) evaluated using the current conditional distribution of z given x and the current estimate of the parameters θi, where
A maximization (M) step, which computes parameters maximizing the expected log-likelihood Q(θ,θi) found on the E step and then update parameters to θi+1.
Since we know x and θi, p(x∣θi) is a constant and therefore we can write from (15) to (16). In the earlier section “Settings of the Hidden Markov Model” of the post, we deduce that
We are going to maximize Q(θ,θi) and update θi+1.
Note that we write Q(θ,θi) as the sum of three terms. The first therm is related to π, the second term is related to A, and the third term is related to B. Therefore we can maximize each term separately.
Note that any pair of primal and dual optimal points must satisfy the KKT conditions. So we use one KKT property that the gradient must vanish at the optimal point to find π. This might not be the optimal π since “any pair of primal and dual optimal points must satisfy the KKT conditions” doesn’t imply that a point satisfying the KKT conditions is the optimal.
Remark: I(xt=Vk) is an indicator function. If xt=Vk, then I(xt=Vk)=1, and 0 otherwise. We get the results (19) and (20) from (4.43) and (4.44).
We also call this algorithm Baum-Welch algorithm.
Problem 3 (Inference)
Goal: Given an observation sequence x and parameters θ=(A,B,π), discover the best hidden state sequence z.
Method 1:Brute force.
This is not applicable. Every hidden state has m choices and the sequence has length n. So there are mn possible combinations.
Method 2: Use Forward/ Backward Algorithm. Given a sequence x, we know how to compute p(zk∣x) from the top of the post. Therefore, at each time k, we can compute p(zk=i∣x) for all i∈{1,2,...,m} and choose the one with the highest probability. In the way, at every time, we chose the most possible hidden state. However, there is still a problem. It only finds the most possible hidden state locally and doesn’t take the whole sequence into account. Even if we chose the most possible hidden state at each time k. The combination of them might not be the best one and even doesn’t make sense. Foe example, if Aij=0, then if zk=i, zk+1 cannot take state j. But the Forward/ Backward Algorithm doesn’t take it into account. We can think of it as a greedy approach to approximate the best result.
Method 3: Viterbi algorithm:
The Viterbi algorithm is a dynamic programming algorithm for finding the most likely sequence of hidden states that results in a sequence of observed events in HMM.
We define δk(i) to be the maximum probability among all paths which are at state i at time k. That is,
by recursion. During the process of finding the highest probability of a path, we keep recording the hidden states associate with the path. So after we find the the highest probability, we also record the path associated with it and therefore the best sequence z.