Python爬虫:使用Selenium完整爬取京东每页数据
一、完整代码及注释分析
from selenium import webdriver
import time
import os
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
#初始化
def init():
# 实现无可视化界面得操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#设置chrome_options=chrome_options即可实现无界面
driver = webdriver.Chrome(chrome_options=chrome_options)
#把浏览器实现全屏
#driver.maximize_window()
#返回driver
return driver
#请求
def login(driver,url):
#发起请求
driver.get(url)
time.sleep(1)
#休息一秒然后操纵滚轮滑倒最底部,这时浏览器数据全部加载,返回的源码中是全部数据
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(1)
#得到代码
source = driver.page_source
#返回source源码以供解析
return source
#爬取
def download(source):
#使用lxml XML解析器
bs = BeautifulSoup(source, "lxml")
#根据class获取全部li标签,参考图1
ul_list = bs.find_all(class_="gl-item")
#遍历得到各个li
for li in ul_list:
#把li在进行解析
li_soup = BeautifulSoup(str(li),'lxml')
#拿到img标签的src属性即为图片url,参考图2
img_url = "http:" + li_soup.find("img")['src']
#参考图3,标题在em标签,但有的em标签内部有span标签,我们需要排除span标签
title = li_soup.find(class_="p-name p-name-type-2").find("em")
#排除span标签
info = [s.extract() for s in title('span')]
#拿到文本值并去除空白字段
title_name = title.text.strip()
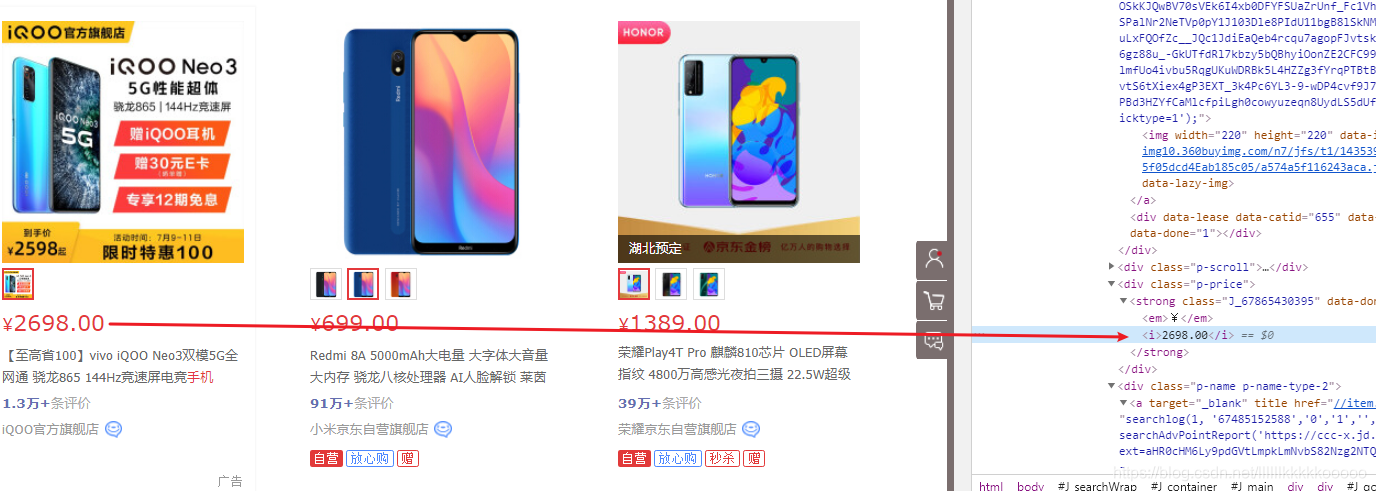
#根据标签查找加上.string拿到标签里的文本,参考图4
price = li_soup.find("i").string
print(img_url)
print(price)
print(title_name)
print("="*40)
if __name__ == "__main__":
s = 1
num = 1
#使用Selenium初始化Chrome浏览器
driver = init()
#爬取多页
for i in range(2):
start_url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&wq=%E6%89%8B%E6%9C%BA&page=" + str(num) + "&s=" + str(s) + "&click=0"
s += 50
num += 2
# print(start_url)
#发起请求
source = login(driver,start_url)
#爬取
download(source)
二、图片辅助分析
图1
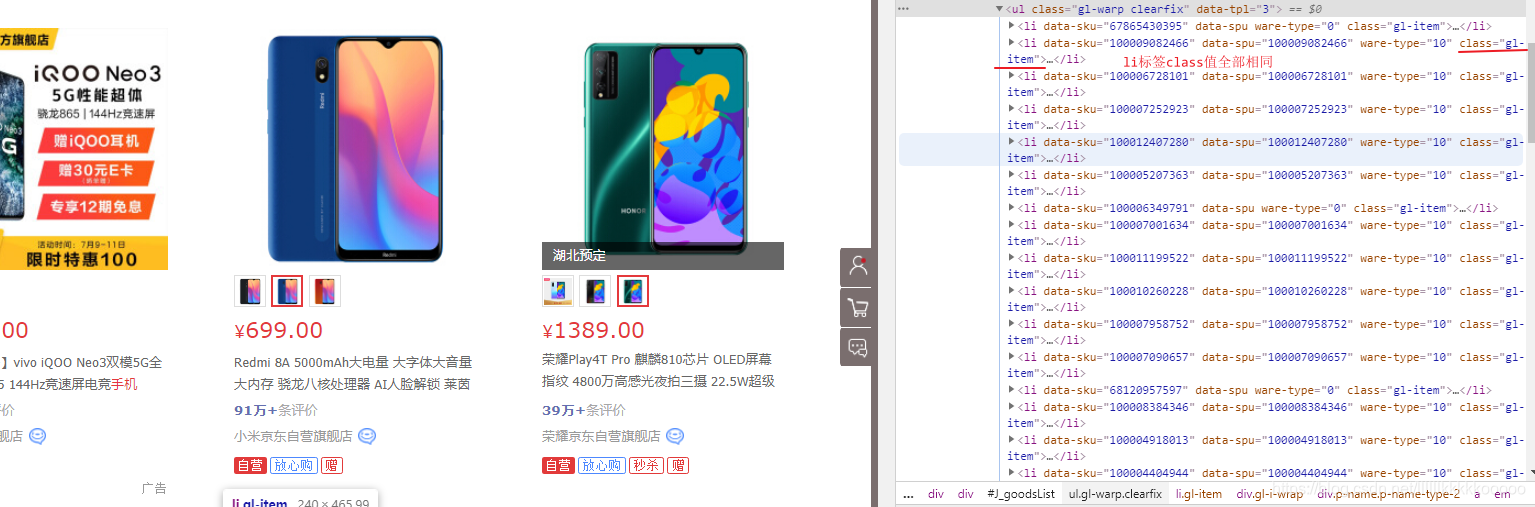
图2

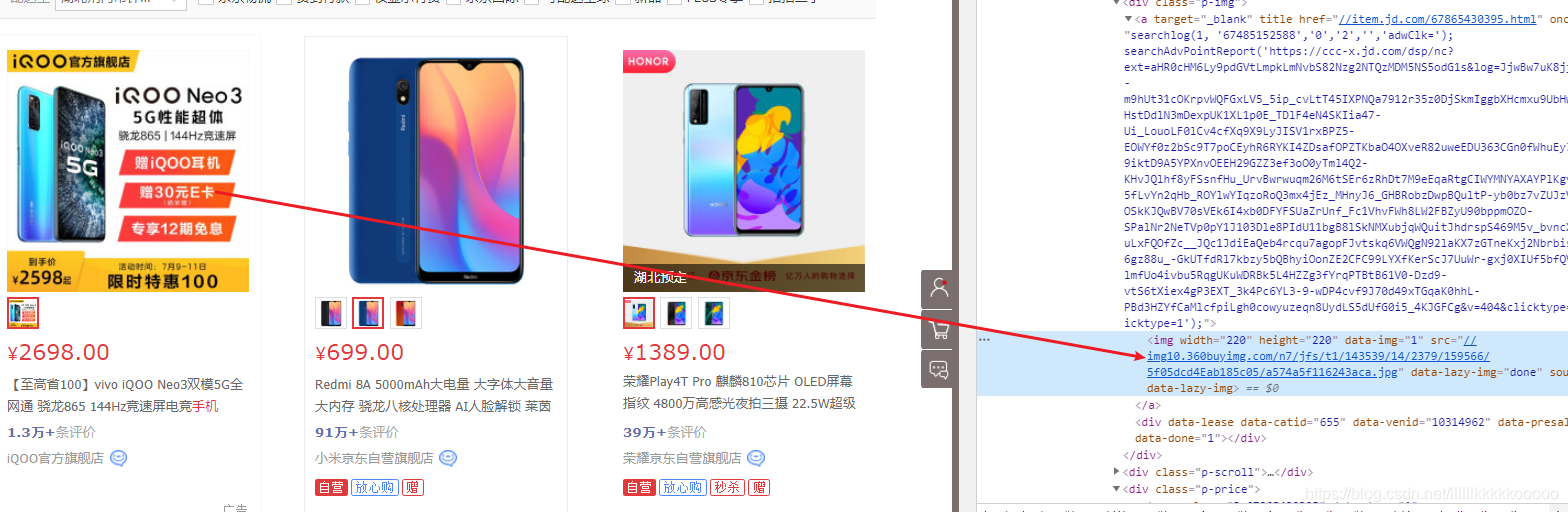
图3
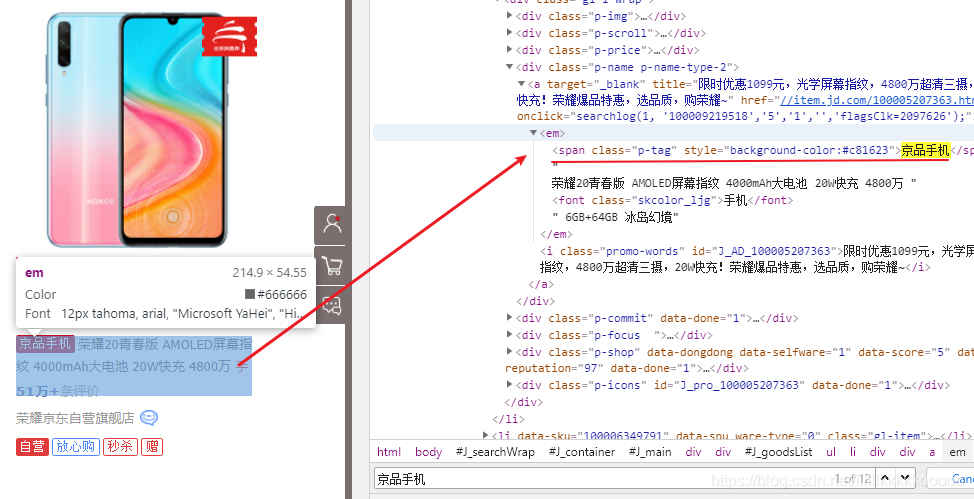
图4
三、运行结果



爬取2页一共480行除以2再除以4,则每页60条数据
觉得不错的读者大大可以点赞关注收藏哦,谢谢各位!,更多博客文章尽在下方链接。
博主更多博客文章