Python爬虫 目录导航
1、前言
目的
长文巨著,本文将手摸手交你零基础学会Python爬虫。
文章以爬取京东网上一款Nike鞋的商品信息为例。
关于爬虫
爬虫大致可以分为三个阶段
- 爬取网站信息
- 筛选出我们要的信息
- 持久化数据
现在很多网站也都会做一些反爬措施,比如很多网页需要登录才可以查看,拿不到授权,自然就访问不了页面了,当然这个只要我们把用户名、密码一起放到请求中,并且参数名和网站的一样就可以。所以为了防止这种机器操作,就有了验证码,验证码有很多中,反正越难用代码模拟,反爬的效果就越好。还有的请求过于频繁就禁止继续访问,这样也可以降低爬虫的速度。不过此文章要爬的JD并没有什么限制,我们使用浏览器即使不登录也是可以匿名访问(游客模式)的。接下来就按三个阶段分别开始讲述怎么爬虫吧。完整代码会放到码云上(地址在文末)。
关于Python
Python是一门高级语言,语法简洁,对于博主这种写习惯了Java这门啰嗦、严谨的人来说,使用python确实会有点不习惯。python在爬虫、人工智能、大数据等领域应用广泛,这有赖于python强大的第三方库。本此爬虫有使用到“lxml”这个第三方库,比起自己写正则表达式来过滤数据方便太多了,香!
2、准备
工具
- PyChram
- python 3.0+
安装第三方库和包
包
- BeautifulSoup
- xlwt
- requests
包的导入在PyChram里,只要光标移至红色波浪线上,然后点击图所示
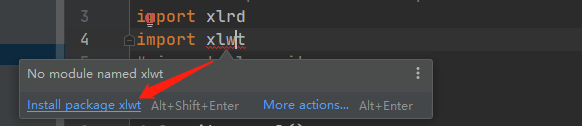
第三方库
可以使用pip工具安装第三方库,pip程序在python根目录下的Scripts文件夹下:%python%\Scripts
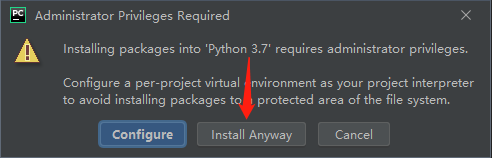
如果未将pip加入到环境中,在 Scripts运行cmd程序,执行以下命令即可(以管理员身份运行)

- cmd命令如下:pip install lxml
小学二年级学的知识点,这里就不赘述了。
3、敲代码
1、爬取网站信息
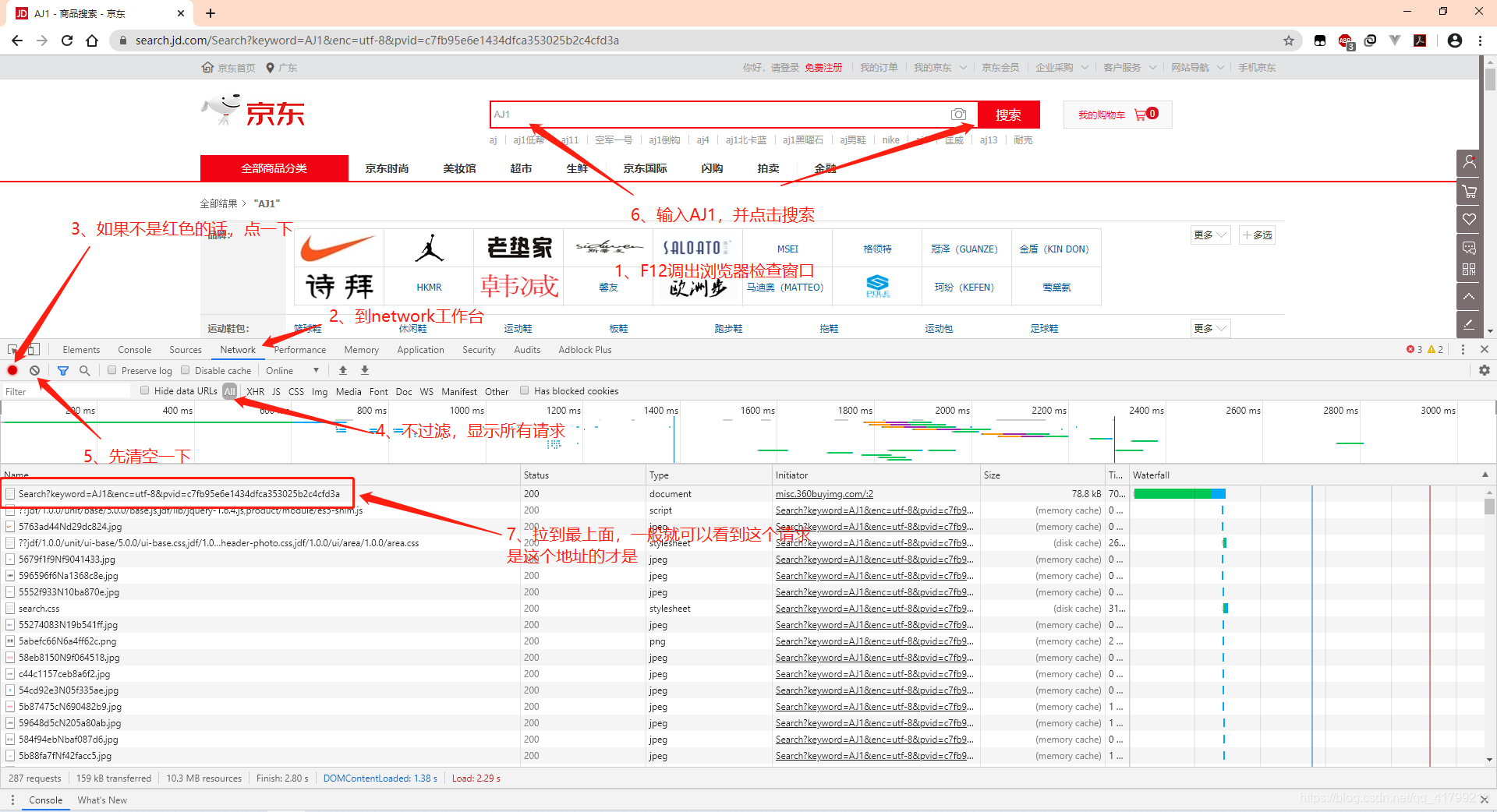
在爬取网站之前,我们需要先分析目标网站。以京东网站爬取Nike的A锥(AJ1)为例为例。首先我们需要爬到京东搜索AJ1的信息,即拿到它的HTML文本,所有我们得先知道它的url是啥。
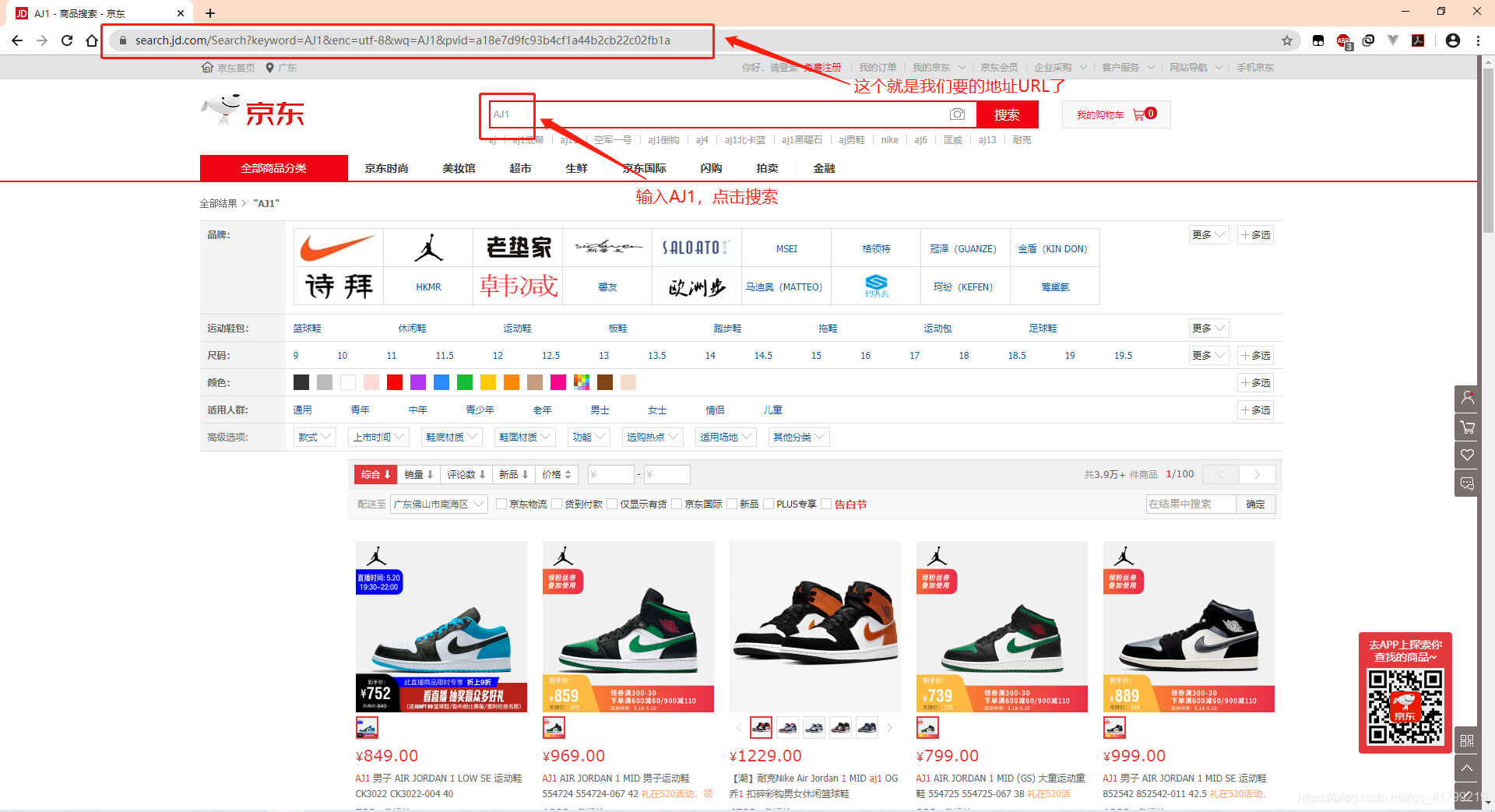
我们先来分析这个url是怎么发送请求,才可以搜索到我们要的关键字的
https://search.jd.com/Search?keyword=AJ1&enc=utf-8&wq=AJ1&pvid=a18e7d9fc93b4cf1a44b2cb22c02fb1a

通过上面分析,我们知道,至少我需要传keyword这个参数过去。编码最好还是带上
于是我们的url就是:https://search.jd.com/Search?keyword=AJ1&enc=utf-8
拿到地址后,我们就可以用python去扒它了!
import requests
if __name__ == '__main__':
url = 'https://search.jd.com/Search?keyword=aj1&enc=utf-8' # 目标网站地址
response = requests.get(url) # 请求访问网站
html = response.text # 获取网页源码
print(html) # 将源码打印到控制台
我们就以简单的方式请求,然后把整个页面的html打印到控制台上。


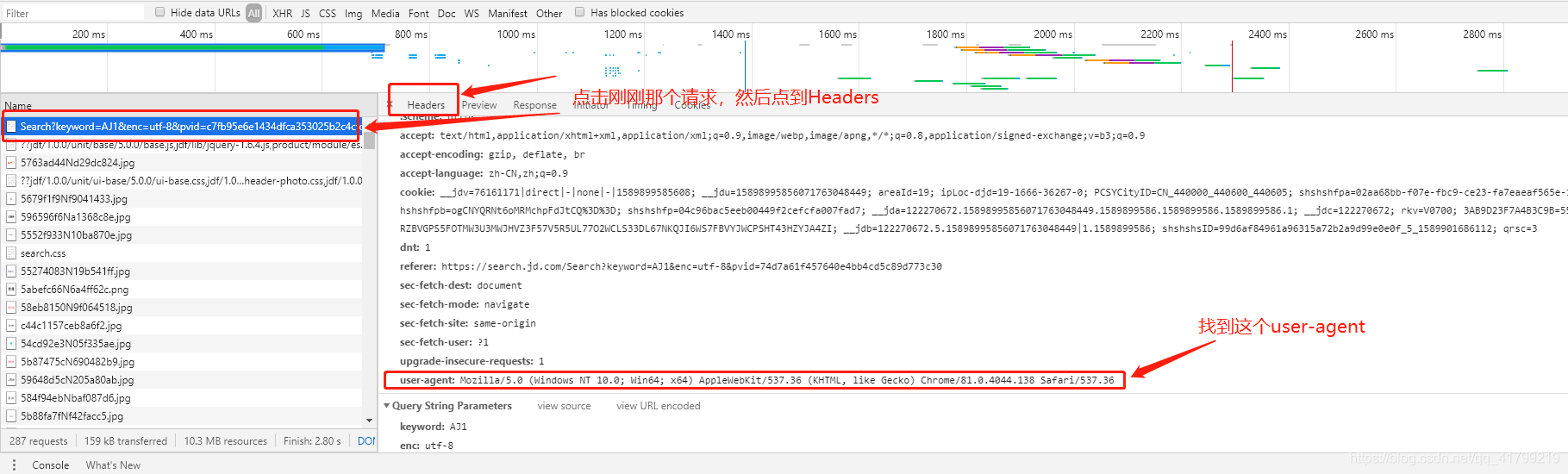
也就是说京东把我们的请求拦截了,但是我们在浏览器不用登录也是可以访问的,那为什么我们用代码去访问就会报错呢?
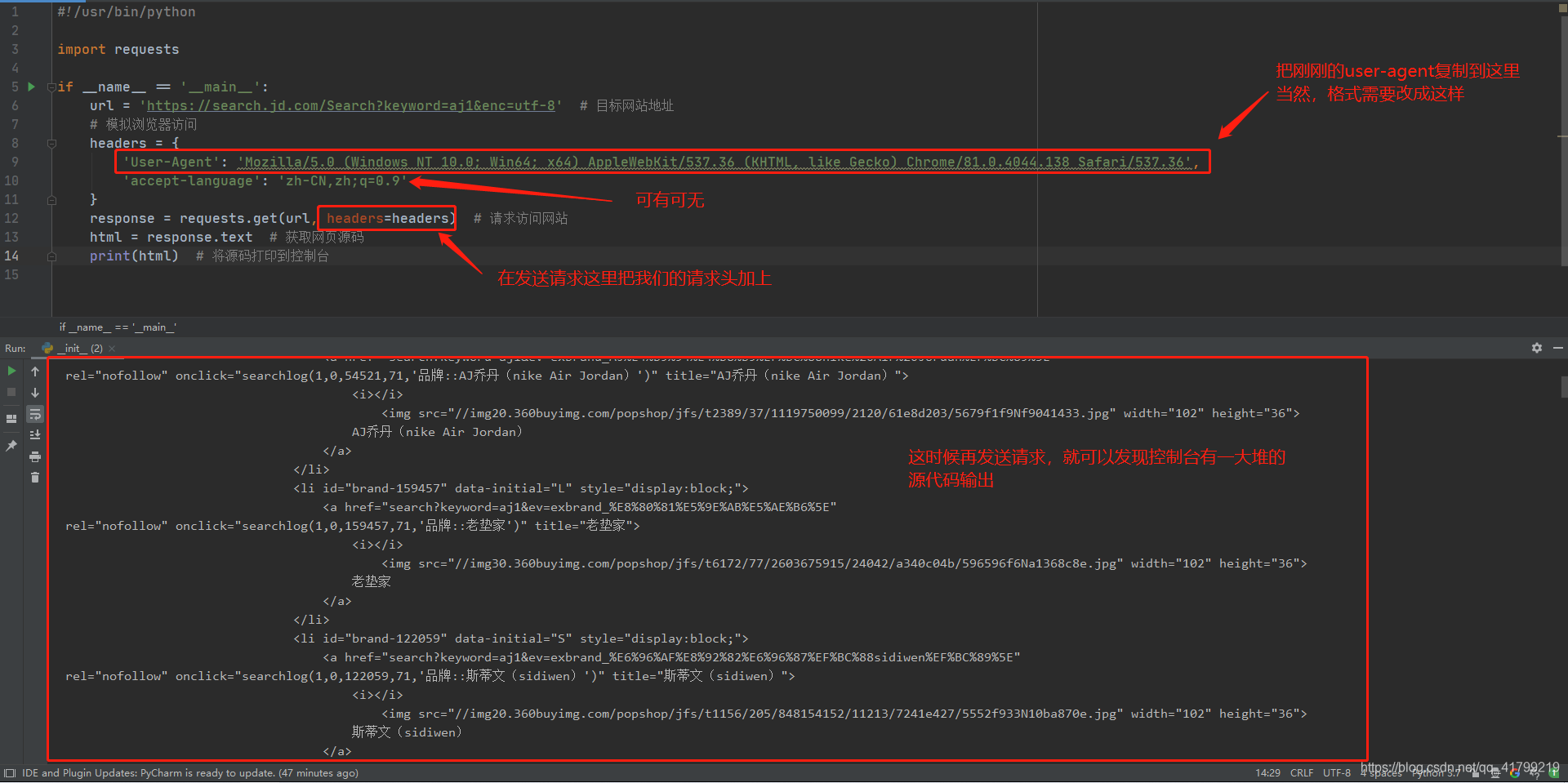
这个其实是因为我们使用浏览器方法网址,浏览器会自动在我们请求头带上一些标记。而上图访问网站的请求仅有请求地址。这时候聪明的读者就要问了,那我们能不能也带上浏览器的标识,从而让京东网站以为我们是通过浏览器访问的,从而骗过它呢? 当然是可以的
我们先要了解浏览器是怎么发送请求的:
import requests
if __name__ == '__main__':
url = 'https://search.jd.com/Search?keyword=aj1&enc=utf-8' # 目标网站地址
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
response = requests.get(url, headers=headers) # 请求访问网站
html = response.text # 获取网页源码
print(html) # 将源码打印到控制台
对代码稍作整理
import requests
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("--> 正在获取网站信息")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页源码
return html # 返回网页源码
else:
print("获取网站信息失败!")
if __name__ == '__main__':
# 搜索关键字
keyword = 'aj1'
# 搜索地址
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
print(get_html(search_url)) # 将源码打印到控制台
2、筛选需要的信息
筛选信息就要用上文中提到的强大的第三方库了 -> lxml,同时我们需要使用到bs4这个包。
但在这之前我们先要知道我们需要什么信息。
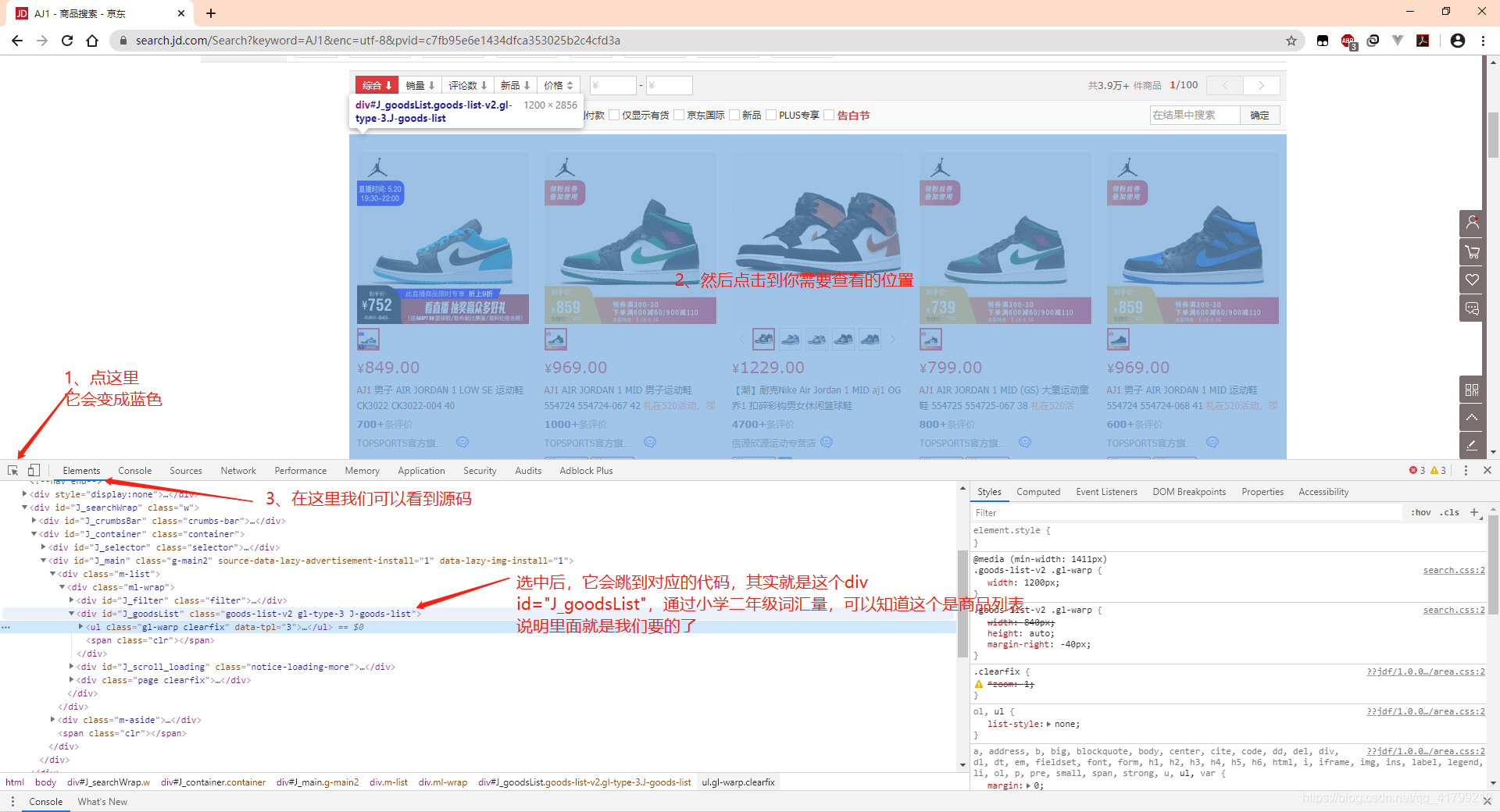
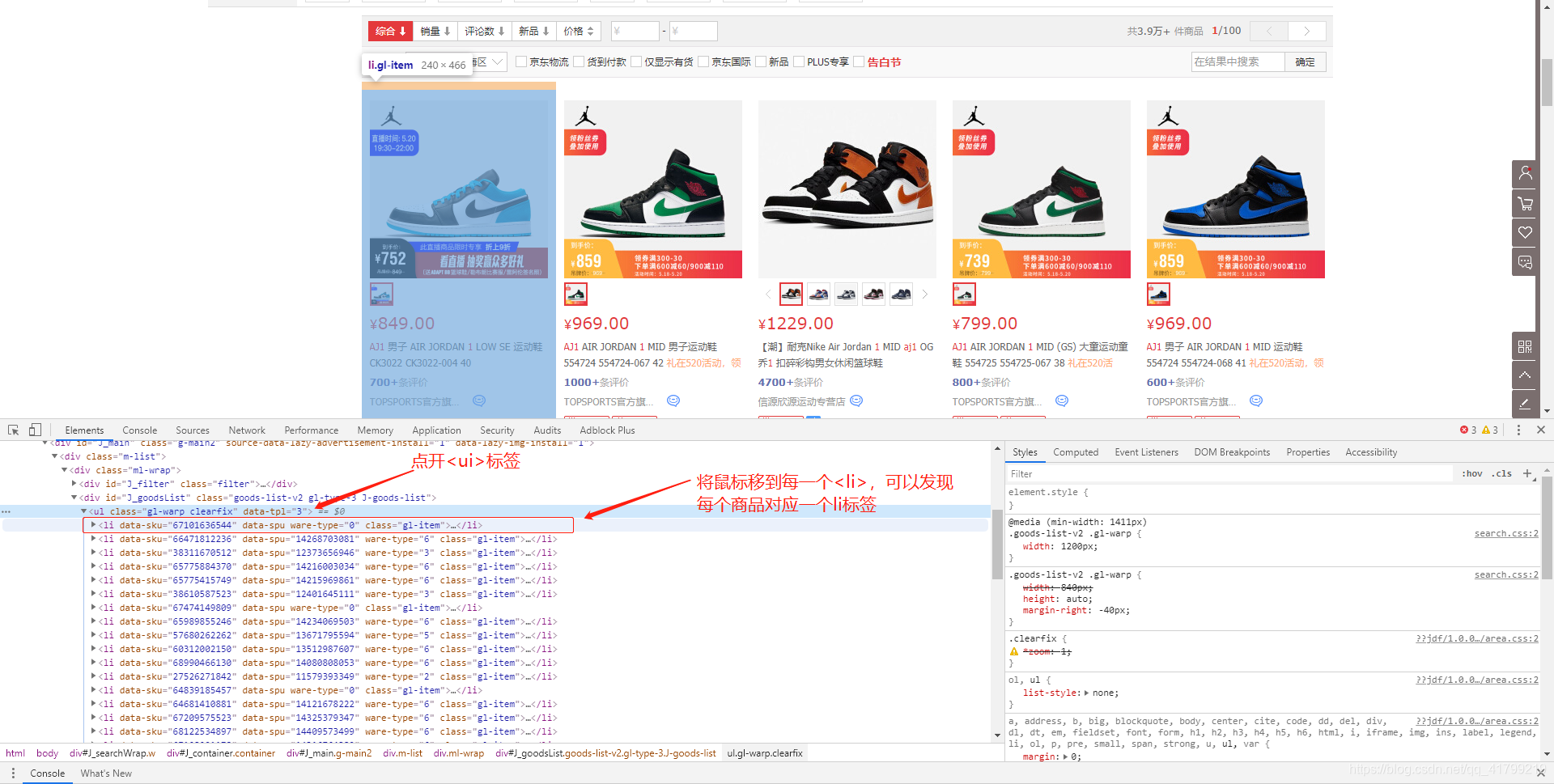
到这里我们就已经知道商品的信息在哪里了。所以我们可以排除其他干扰,<li>标签下的就是我们要的。ok,开始撸代码!
首先导入bs4包,然后就可以使用BeautifulSoup库了,先上代码
import requests
from bs4 import BeautifulSoup
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("--> 正在获取网站信息")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页源码
return html # 返回网页源码
else:
print("获取网站信息失败!")
if __name__ == '__main__':
# 搜索关键字
keyword = 'aj1'
# 搜索地址
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
html = get_html(search_url)
# 初始化BeautifulSoup库,并设置解析器
soup = BeautifulSoup(html, 'lxml')
# 商品列表
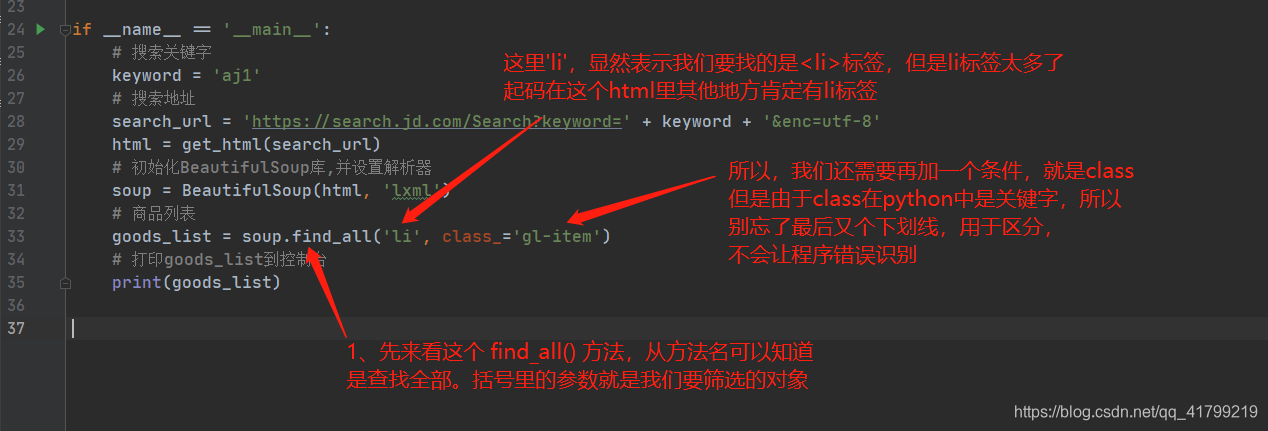
goods_list = soup.find_all('li', class_='gl-item')
# 打印goods_list到控制台
print(goods_list)
soup = BeautifulSoup(html, ‘lxml’) 语句执行后,将解析的结果给soup,这时候我们可以使用BeautifulSoup提供的强大的解析方法了。首先我们来解释一下为什么soup.find_all(‘li’, class_=‘gl-item’)可以获取到商品列表,也就是前文提到的全部<li>标签。
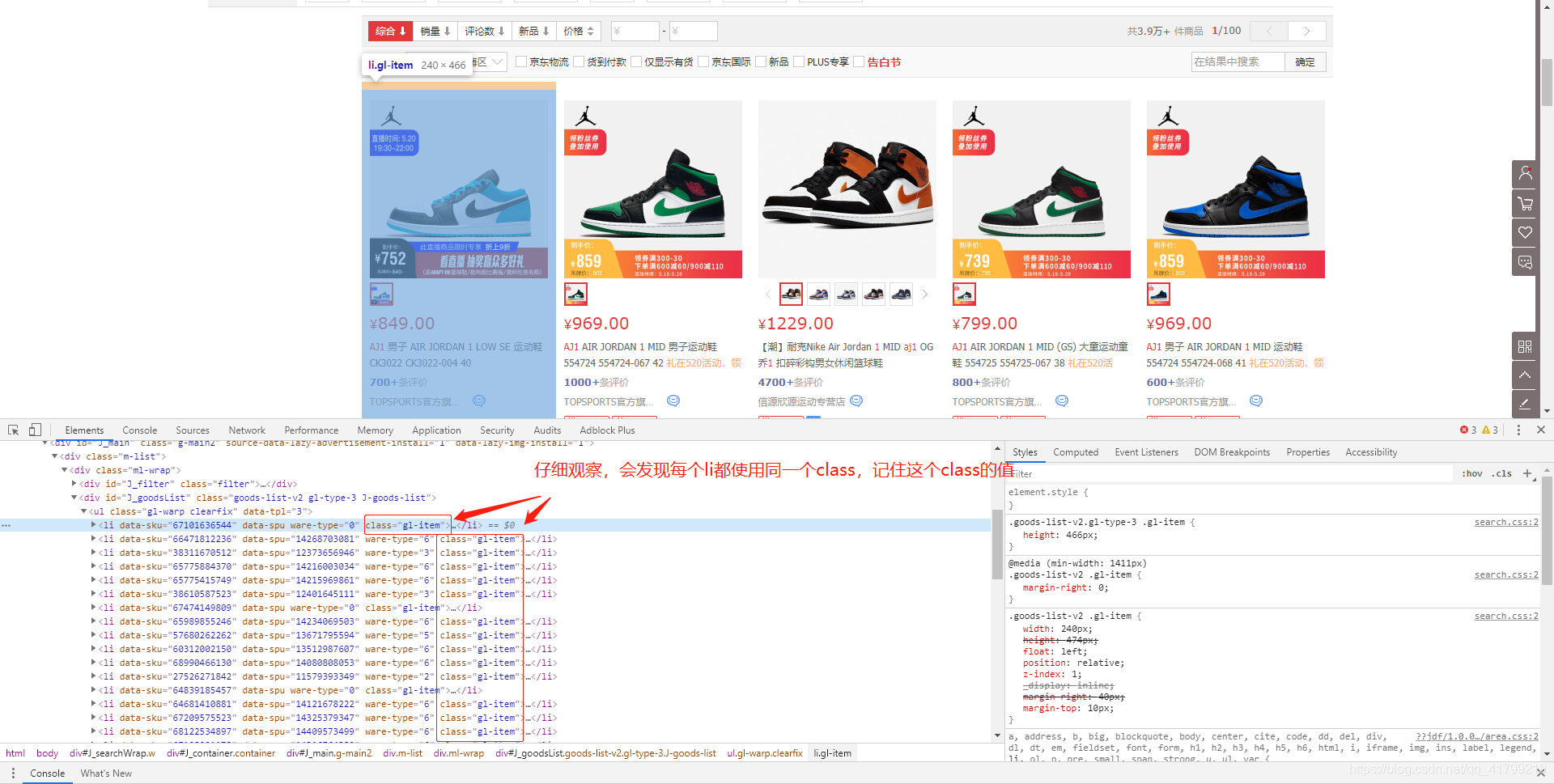
我们执行代码后,就可以获取到所有的<li>标签里的内容了。然后可以把控制台的输出 -> 全选 -> 复制
-> 粘贴 到文本编辑器中,最好是支持html格式的,这样可以格式化代码,排版看起来舒服多了。这里本人使用的是VS Code编辑器。这样可以检查一下爬取到是代码是否正确。接下来我们要找到每个信息存在li里的哪个标签里。大家可以在浏览器像刚刚找商品的li一样,找到其他商品名、价格等信息的位置。下图举个栗子
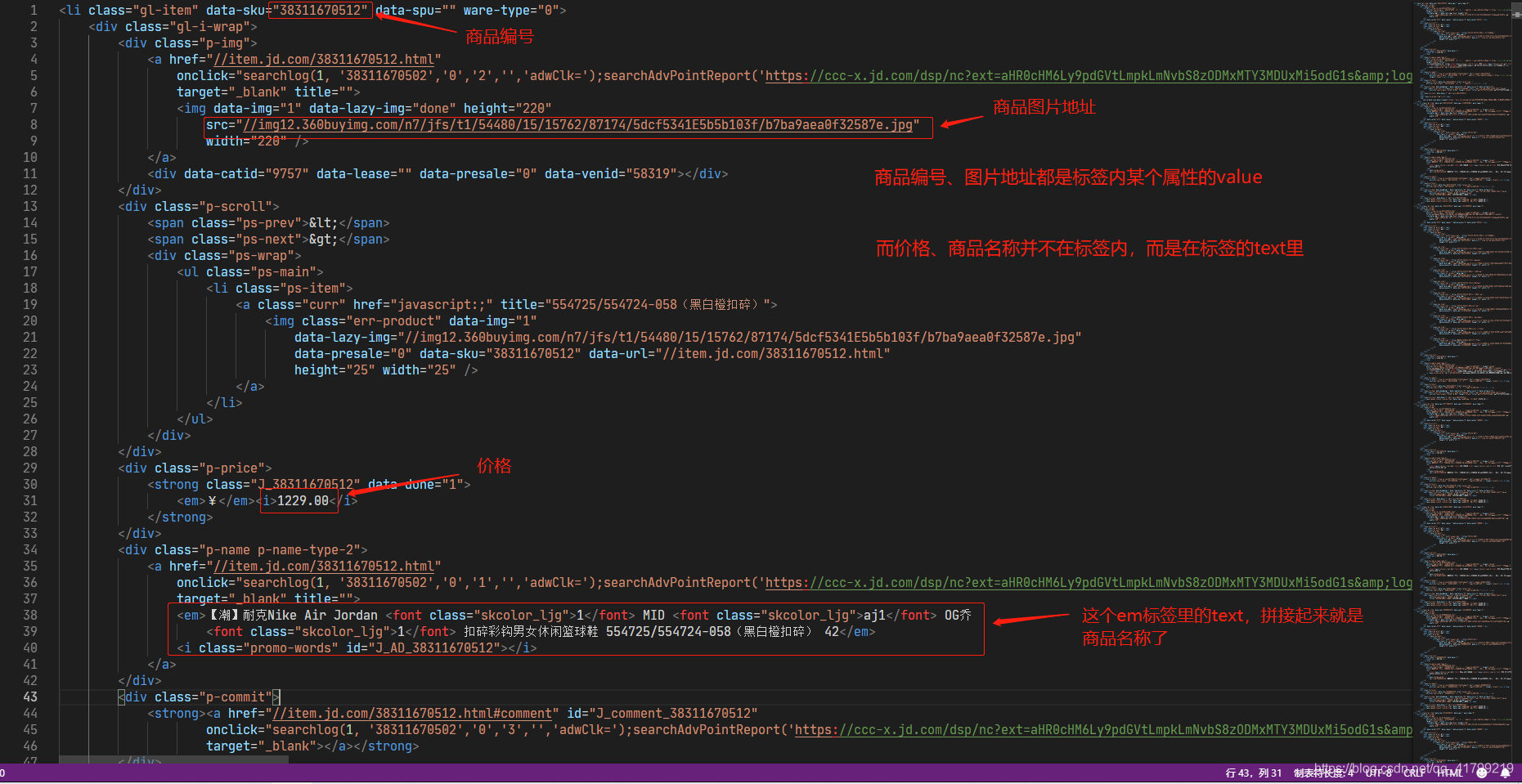
刚刚已经使用过find_all()方法了,如果是找一个而不是全部,那就可以使用find()方法,获取标签内属性的值:[属性名’],获取text:.get_text(),这两种都是返回字符串类型str。
我们可以用for来遍历goods_list,把值给li,这样就可以每次单独取一个li来操作了。
假如li是每个<li>标签,那么
- 获取商品编号就可以写成:li[‘data-sku’]
- 获取图片地址:li.find(class_=‘p-img’).find(‘img’)[‘src’]
- 获取价格:li.find(class_=‘p-price’).find(‘i’).get_text()
- 获取商品名称:li.find(class_=‘p-name p-name-type-2’).find(‘em’).get_text()
琢磨一下,如果还是不清楚,可以搜索一下BeautifulSoup的用法。
import requests
from bs4 import BeautifulSoup
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("--> 正在获取网站信息")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页源码
return html # 返回网页源码
else:
print("获取网站信息失败!")
if __name__ == '__main__':
# 搜索关键字
keyword = 'aj1'
# 搜索地址
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
html = get_html(search_url)
# 初始化BeautifulSoup库,并设置解析器
soup = BeautifulSoup(html, 'lxml')
# 商品列表
goods_list = soup.find_all('li', class_='gl-item')
# 打印goods_list到控制台
for li in goods_list: # 遍历父节点
# 商品编号
no = li['data-sku']
# 商品名称
name = li.find(class_='p-name p-name-type-2').find('em').get_text()
# 图片路径
img_url = li.find(class_='p-img').find('img')['src']
# 价格
price = li.find(class_='p-price').find('i').get_text()
# 商家
shop = li.find(class_='p-shop').find('a').get_text()
# 商品详情地址
detail_addr = li.find(class_='p-name p-name-type-2').find('a')['href']
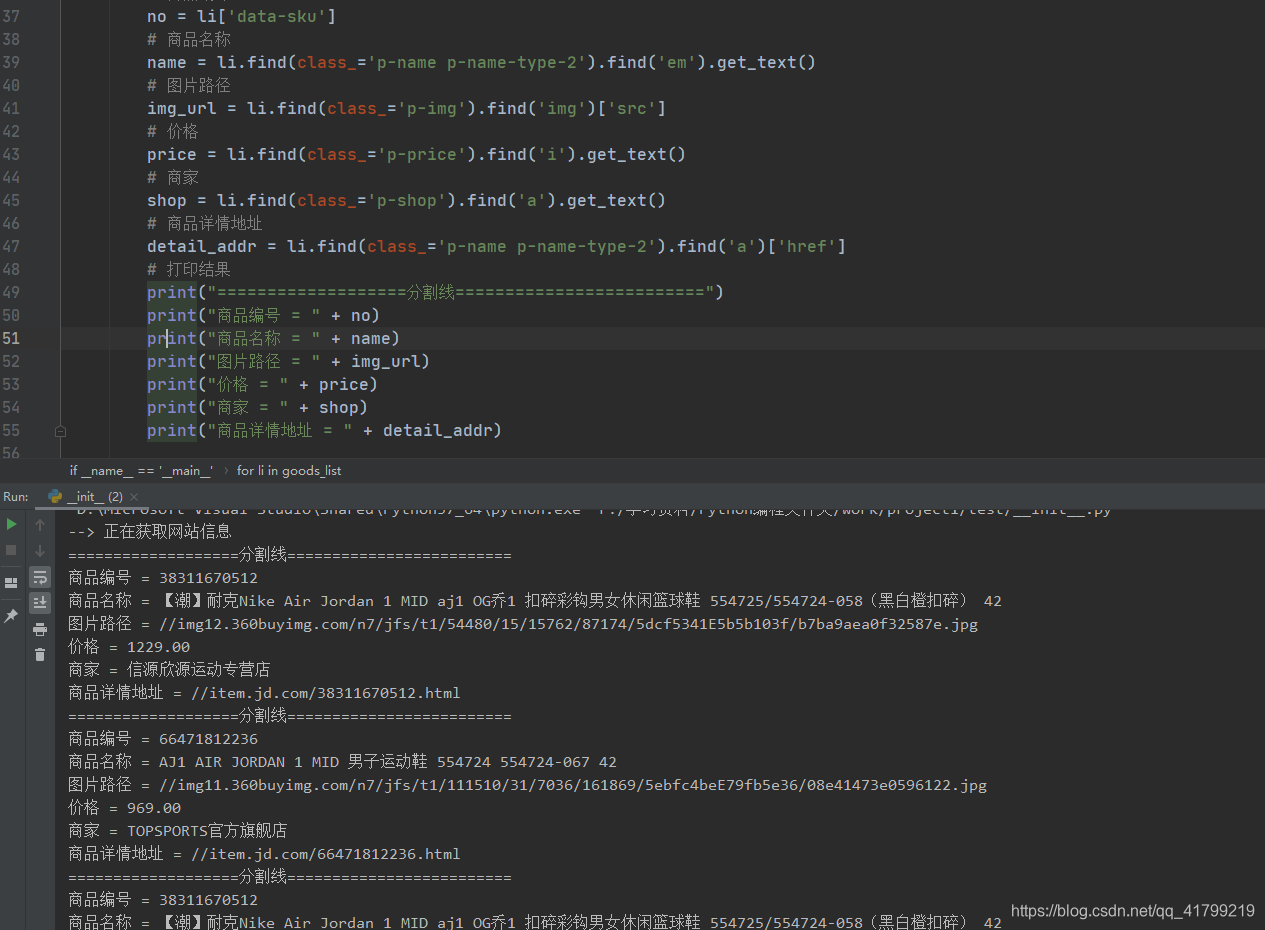
# 打印结果
print("===================分割线=========================")
print("商品编号 = " + no)
print("商品名称 = " + name)
print("图片路径 = " + img_url)
print("价格 = " + price)
print("商家 = " + shop)
print("商品详情地址 = " + detail_addr)
如下图,这样就爬取到了我们需要的内容了
3、持久化数据
通过第二步,我们已经取到我们的数据了,但是我们是数据是存在内存中的,程序运行结束了,数据也就丢失了,虽然打印到控制台了,但它并没有写到我们硬盘中,我关闭pycharm或者关闭电脑了也会丢失。所以要使我们爬取的数据持久化,我们就得把数据写入到磁盘中。可以写到数据库,这样方便对数据操作,也可以写到txt文本。本例是把数据写入到Excel文档中。
使用xlwt库,可以非常方便的把数据写入到Excel中。
首先要先导入库:import xlwt
创建Excle文件:xlwt.Workbook(encoding=‘ascii’)
添加一张单:write_work.add_sheet(“sheet1”)
我们新建Excel文档,都会自己创建一张单,这里的"sheet1",可以根据自己修改名字。
write_sheet = write_work.add_sheet(“sheet1”)。例如我们把新建的这个单返回后,赋值给write_sheet,那么write_sheet.write([行],[列],label=[填充文本])
保存:write_work.save([保存地址])
具体代码如下:
import requests
from bs4 import BeautifulSoup
import xlwt
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("--> 正在获取网站信息")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页源码
return html # 返回网页源码
else:
print("获取网站信息失败!")
if __name__ == '__main__':
# 创建workbook,就是创建一个Excel文档
write_work = xlwt.Workbook(encoding='ascii')
# 添加一张单
write_sheet = write_work.add_sheet("sheet1")
# 创建表头
write_sheet.write(0, 0, label='商品编号') # 第1行 第1列 写入内容'商品编号'
write_sheet.write(0, 1, label='商品名称') # 第1行 第2列 写入内容'商品名称'
write_sheet.write(0, 2, label='图片路径') # 第1行 第3列 写入内容'图片路径'
write_sheet.write(0, 3, label='价格') # 第1行 第4列 写入内容'价格'
write_sheet.write(0, 4, label='商家') # 第1行 第5列 写入内容'商家'
write_sheet.write(0, 5, label='商品详情地址') # 第1行 第6列 写入内容'商品详情地址'
# 记录当前行数
_current_row = 0
# 搜索关键字
keyword = 'aj1'
# 搜索地址
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
html = get_html(search_url)
# 初始化BeautifulSoup库,并设置解析器
soup = BeautifulSoup(html, 'lxml')
# 商品列表
goods_list = soup.find_all('li', class_='gl-item')
# 打印goods_list到控制台
for li in goods_list: # 遍历父节点
# 由于我们第一行已经写入了表头。所以这里0+1,就是从第1行开始,后面每次循环+1
_current_row += 1
# 商品编号
no = li['data-sku']
# 商品名称
name = li.find(class_='p-name p-name-type-2').find('em').get_text()
# 图片路径
img_url = li.find(class_='p-img').find('img')['src']
# 价格
price = li.find(class_='p-price').find('i').get_text()
# 商家
shop = li.find(class_='p-shop').find('a').get_text()
# 商品详情地址
detail_addr = li.find(class_='p-name p-name-type-2').find('a')['href']
# 写入Excel
write_sheet.write(_current_row, 0, label=no)
write_sheet.write(_current_row, 1, label=name)
write_sheet.write(_current_row, 2, label=img_url)
write_sheet.write(_current_row, 3, label=price)
write_sheet.write(_current_row, 4, label=shop)
write_sheet.write(_current_row, 5, label=detail_addr)
# 保存文件,使用的是相对目录(也可以使用绝对路径),会保存在当前文件的同目录下。文件名为dj_data.xls,必须是.xls后缀
write_work.save("./dj_data.xls")
执行代码,然后在同级目录下,就可以看到dj_data.xls文件,打开文件。可以看到已经爬取到了数据了。
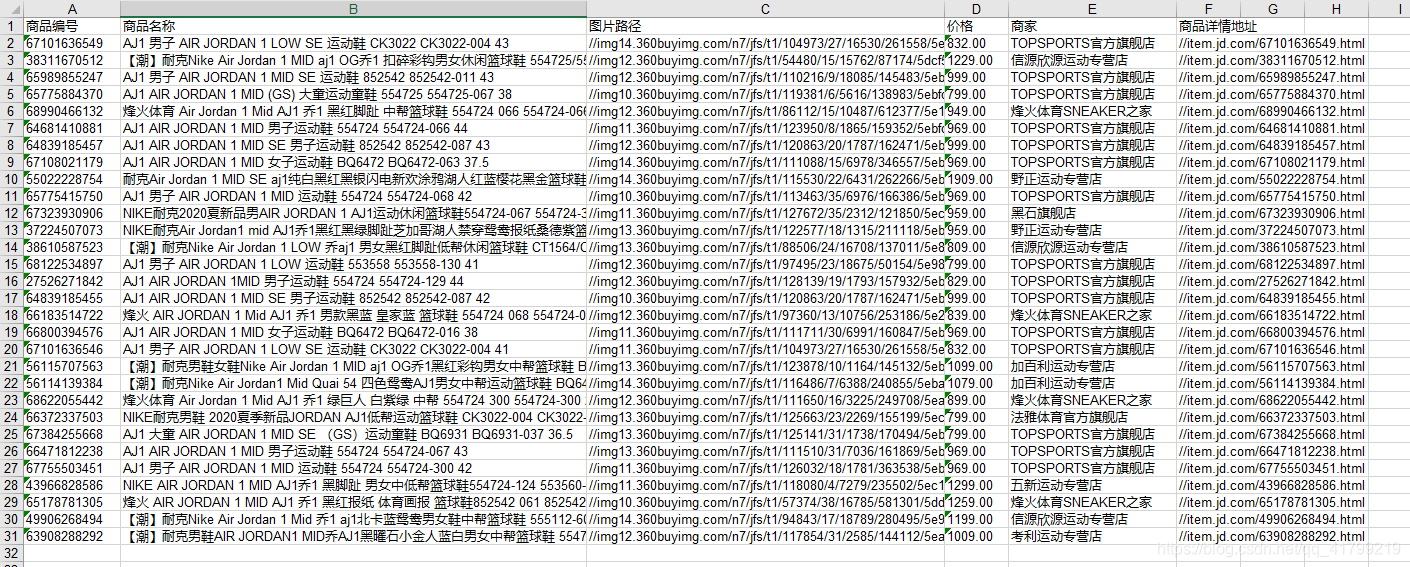
整理一下代码,把Excel操作部分提取到一个类中
#!/usr/bin/python
import requests
from bs4 import BeautifulSoup
import xlwt
class Excel:
# 当前行数
_current_row = 1
# 初始化,创建文件及写入title
def __init__(self, sheet_name='sheet1'):
# 表头,放到数组中
title_label = ['商品编号', '商品名称', '图片路径', '价格', '商家', '商品详情地址']
self.write_work = xlwt.Workbook(encoding='ascii')
self.write_sheet = self.write_work.add_sheet(sheet_name)
for item in range(len(title_label)):
self.write_sheet.write(0, item, label=title_label[item])
# 写入内容
def write_content(self, content):
for item in range(len(content)):
self.write_sheet.write(self._current_row, item, label=content[item])
# 插入完一条记录后,换行
self._current_row += 1
# 保存文件(这里的'./dj_data.xls'是默认路径,如果调用此函数,没有传file_url参数,则使用'./dj_data.xls')
def save_file(self, file_url='./dj_data.xls'):
try:
self.write_work.save(file_url)
print("文件保存成功!文件路径为:" + file_url)
except IOError:
print("文件保存失败!")
def get_html(url):
# 模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9'
}
print("--> 正在获取网站信息")
response = requests.get(url, headers=headers) # 请求访问网站
if response.status_code == 200:
html = response.text # 获取网页源码
return html # 返回网页源码
else:
print("获取网站信息失败!")
if __name__ == '__main__':
# 创建文件
excel = Excel()
# 搜索关键字
keyword = 'aj1'
# 搜索地址
search_url = 'https://search.jd.com/Search?keyword=' + keyword + '&enc=utf-8'
html = get_html(search_url)
# 初始化BeautifulSoup库,并设置解析器
soup = BeautifulSoup(html, 'lxml')
# 商品列表
goods_list = soup.find_all('li', class_='gl-item')
# 打印goods_list到控制台
for li in goods_list: # 遍历父节点
# 商品编号
no = li['data-sku']
# 商品名称
name = li.find(class_='p-name p-name-type-2').find('em').get_text()
# 图片路径
img_url = li.find(class_='p-img').find('img')['src']
# 价格
price = li.find(class_='p-price').find('i').get_text()
# 商家
shop = li.find(class_='p-shop').find('a').get_text()
# 商品详情地址
detail_addr = li.find(class_='p-name p-name-type-2').find('a')['href']
# 将商品信息放入数组中,再传到写入文件函数
goods = [no, name, img_url, price, shop, detail_addr]
# 写入文档
excel.write_content(goods)
# 保存文件,使用的是相对目录(也可以使用绝对路径),会保存在当前文件的同目录下。文件名为dj_data.xls,必须是.xls后缀
excel.write_work.save("./dj_data.xls")
4、扩展(分页爬取)
通过前面的步骤,我们已经可以把数据爬取到并提取出来,再写入文件了,但是聪明的读者又要问了,在京东上,搜索AJ1,有100页数据,每页有几十个商品,这爬虫怎么才爬了30+条。
di
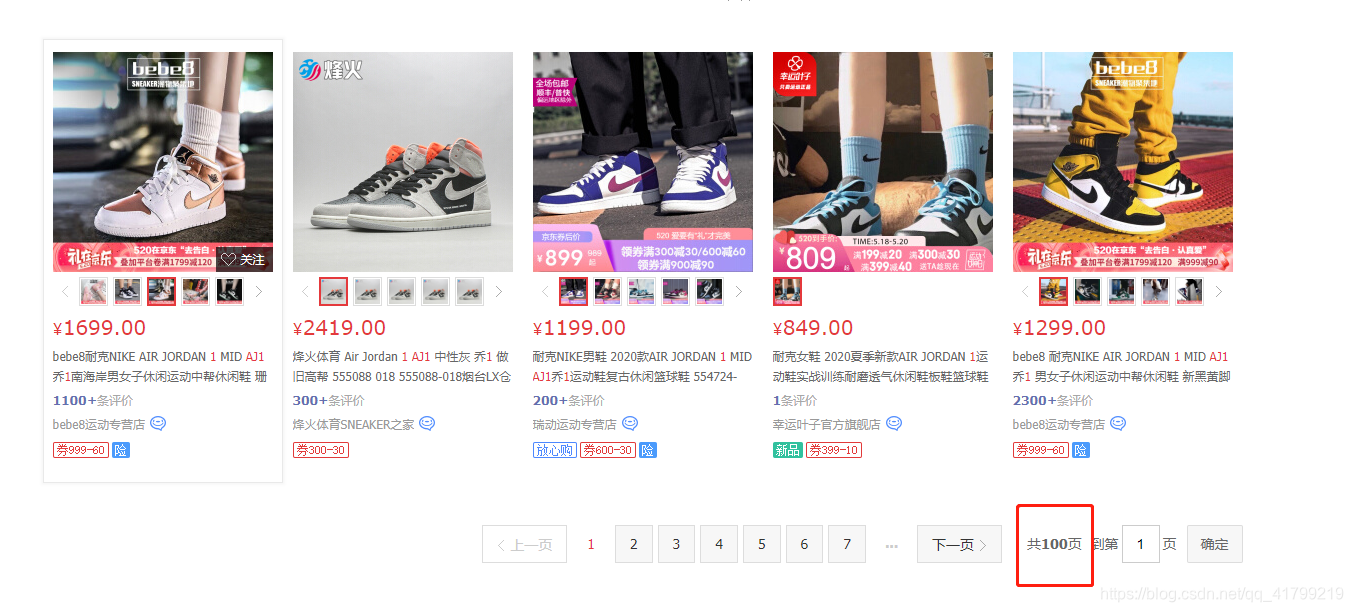
这是因为这些网站数据量太大,如果一次把所有的数据加载出来,可以我们打开一个页面要等上几分钟,所以这些网站是有分页的,也就是说你点第一页的时候,它不会把2、3的内容传输过来,点第二页的时候,才重新再发请求。那我们前面只发了一条请求,当然就只看到了第一页的信息了。
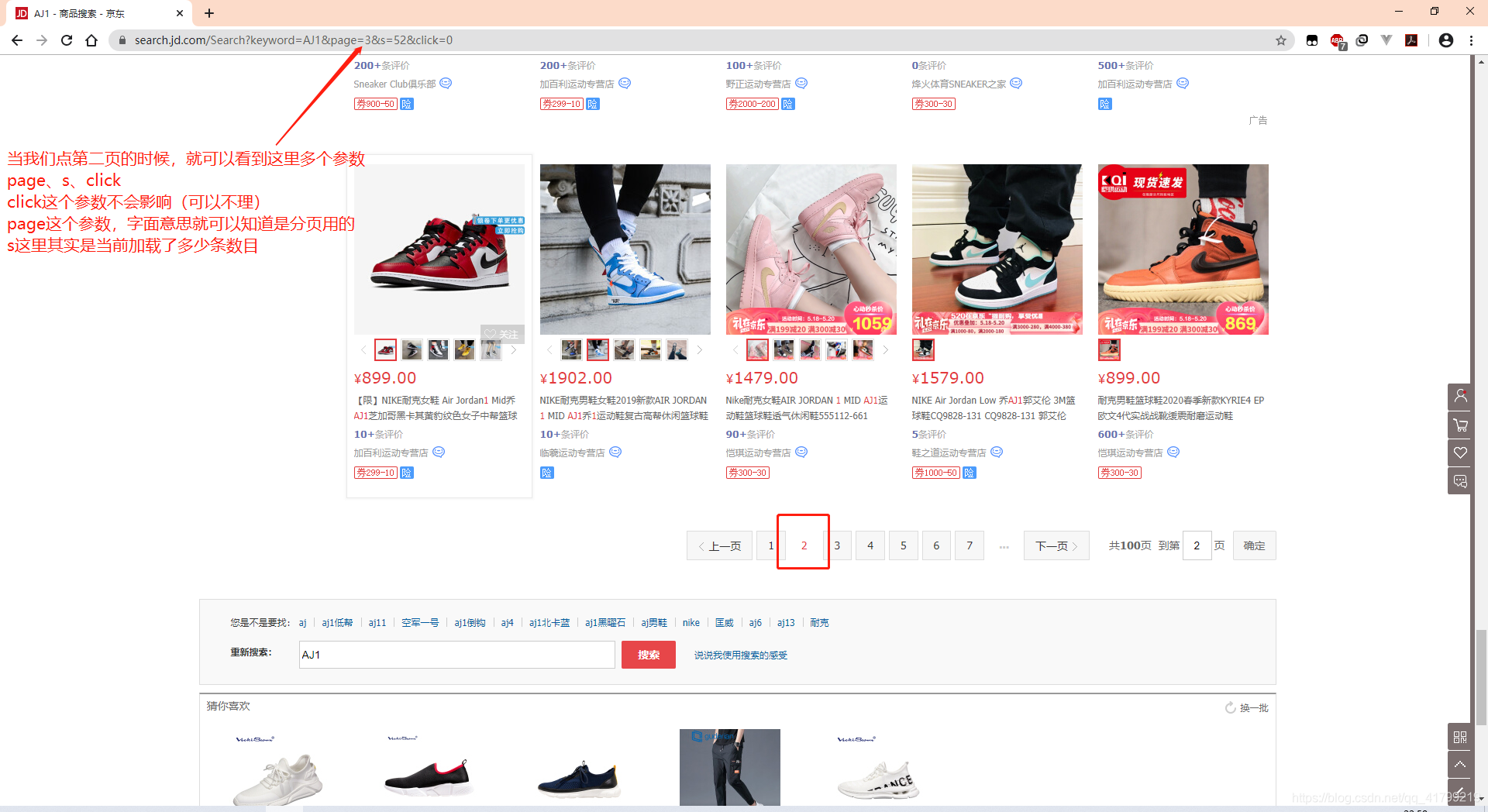 但是这里会绝得很奇怪,为什么第二页,但是page的参数是3而不是2呢,其实这个3对代码来说,确实的第三页,因为京东第一页翻到第二页是用流加载的。也就是说,当你页面滚到第第一页末尾的时候,它会发一次请求第二页,所以到你点第二页的时候,已经是第三次请求了(第一次请求是刚进来页面、第二次是滑倒底部流加载请求了一次,第三次是点第二页的时候又请求了一次)。
但是这里会绝得很奇怪,为什么第二页,但是page的参数是3而不是2呢,其实这个3对代码来说,确实的第三页,因为京东第一页翻到第二页是用流加载的。也就是说,当你页面滚到第第一页末尾的时候,它会发一次请求第二页,所以到你点第二页的时候,已经是第三次请求了(第一次请求是刚进来页面、第二次是滑倒底部流加载请求了一次,第三次是点第二页的时候又请求了一次)。
分析到这里那么我们要请求更多的数据就改变page的值和s(当然s也可以不要)的值就可以啦。
关于分页这部分代码本文就不在做详细解释了。具有分页功能的代码会放到码云上。
4、代码
码云地址:含分页功能