PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
PaddleOCR是一个图像识别库,我只是用到了它的OCR功能,就是识别图片中的文字。其他的功能也很强大,我没用到。
安装
更新:截止到2022年12月21日,paddlepaddle是2.4.1,paddleocr是2.6.1.2,numpy是1.24.0,numpy是自动安装的。识别时若报错AttributeError: module 'numpy' has no attribute 'int',则numpy安装1.23.4就行,因服务器(线上正式环境)上paddlepaddle是2.3.2,paddleocr是2.6.1.0,numpy是1.23.4,服务器上正常。
更新:截止到2022年11月28日,paddlepaddle是2.4.0,paddleocr是2.6.1.1,在linux安装时,不用手动安装shapely,而安装paddleocr时会自动装上shapely。另外,CentOS上运行代码若是报错ImportErrer: libpython3.8. s0.1.0: cammot open shared object file: No such file or directory,这篇文章可以解决,以前没这个问题,可能是因版本更新才出的这个问题。
linux
- pip install paddlepaddle
- pip install shapely
- pip install paddleocr
windows
- pip install paddlepaddle
- 在这里手动下载shapely whl文件安装(安装命令是pip install xxx.whl,whl文件路径最好是绝对路径,或者cmd提前进入whl文件所在目录),不能直接pip install shapely,会有问题,具体下载哪个文件?cmd中执行pip debug --verbose,我是python 3.8,实际根据你的python版本选择。
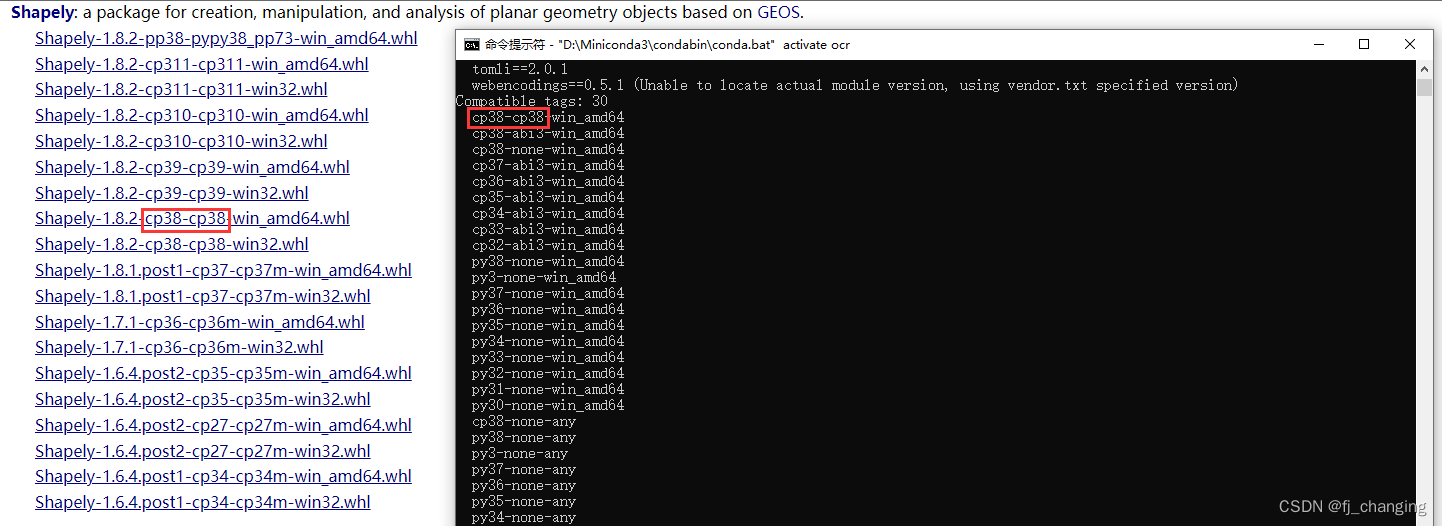
- pip install paddleocr,装的时候可能报错ERROR: Failed building wheel for python_Levenshtein,同样在这里手动下载whl文件安装,然后再安装paddleocr
使用
下面的代码,比官方示例代码(2.6版)1、官方示例代码(2.6版,含参数说明)2多了一些内容,比如导包、关闭日志的打印、加快识别速度(加快前我这识别一张图需要3.1秒,加快后需要1.5秒,我没用GPU,具体耗时看机器性能)。
PaddleOCR()的参数说明,在官方示例代码页最下面。
from paddleocr import PaddleOCR, draw_ocr, paddleocr
import logging
# paddleocr.logging.disable(logging.DEBUG) # 关闭DEBUG日志的打印,用PaddleOCR(enable_mkldnn=True, use_tensorrt=True, use_angle_cls=False, lang="ch")时生效
# 还有关闭日志打印的方法https://github.com/PaddlePaddle/PaddleOCR/issues/2467,未测试
# paddleocr.logging.disable(logging.WARNING) # 关闭WARNING日志的打印
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
# ocr = PaddleOCR(enable_mkldnn=True, use_tensorrt=True, use_angle_cls=False, lang="ch") # enable_mkldnn是Intel芯片的加速库,识别一张身份证大约需1.5秒 from https://www.cnblogs.com/newmiracle/p/15358230.html和https://www.cnblogs.com/newmiracle/p/15346284.html和https://github.com/PaddlePaddle/PaddleOCR/issues/1500,官方文档对enable_mkldnn参数的介绍https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.5/doc/doc_ch/FAQ.md#qpaddleocr%E4%B8%AD%E5%AF%B9%E4%BA%8E%E6%A8%A1%E5%9E%8B%E9%A2%84%E6%B5%8B%E5%8A%A0%E9%80%9Fcpu%E5%8A%A0%E9%80%9F%E7%9A%84%E9%80%94%E5%BE%84%E6%9C%89%E5%93%AA%E4%BA%9B%E5%9F%BA%E4%BA%8Etenorrt%E5%8A%A0%E9%80%9Fgpu%E5%AF%B9%E8%BE%93%E5%85%A5%E6%9C%89%E4%BB%80%E4%B9%88%E8%A6%81%E6%B1%82
# 输入待识别图片路径
img_path = r"d:\Desktop\4A34A16F-6B12-4ffc-88C6-FC86E4DF6912.png"
# 输出结果保存路径
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.show()效果图就看参考链接吧(官方示例代码中也有效果图),我也是看他们的步骤学的,只不过在windows中安装时遇到了问题,记录一下。
如果加速后你还嫌识别速度慢,可以直接买百度或阿里云或腾讯云的识别接口,或者买带GPU的服务器。如果你有其他免费提速的方法请告诉我,谢谢。
再放一个文本方向分类器(2.6版)的介绍,不知道在代码里怎么用,可能是use_angle_cls参数,前面放的含参数说明的链接里有介绍,但看不懂。比如拍的身份证是竖着的,需要向左或向右旋转90度才能使文字水平,我不知道PaddleOCR如何让图片先旋转再识别,或者PaddleOCR是否会自动旋转图片再识别。我实际用的时候将use_angle_cls设为False了,因为True时识别速度慢,我只有CPU。而且2.6版介绍中说:
文本方向分类器主要用于图片非0度的场景下,在这种场景下需要对图片里检测到的文本行进行一个转正的操作。在PaddleOCR系统内, 文字检测之后得到的文本行图片经过仿射变换之后送入识别模型,此时只需要对文字进行一个0和180度的角度分类,因此PaddleOCR内置的 文本方向分类器只支持了0和180度的分类。如果想支持更多角度,可以自己修改算法进行支持。
参考链接
适合小白的几个入门级Python ocr识别库_起不好名字就不起了的博客-CSDN博客_ocr库
百度OCR(文字识别)服务使用入坑指南_起不好名字就不起了的博客-CSDN博客_百度ocr试用
python,使用(pip install .) Failed building wheel for python_Levenshtein解决方法_A吴广智的博客-CSDN博客
python paddleocr 增加识别速度的方法 - newmiracle宇宙 - 博客园 (cnblogs.com)
paddleocr提高识别的方法 - newmiracle宇宙 - 博客园 (cnblogs.com)
如果你有其他问题,也可以看官方FAQ