前言
本节学习卷积神经网络,然后使用经典的LENET-5神经网络训练手势识别。
教程地址:视屏地址
课程笔记
深度学习模型:
建模——>损失函数——>参数学习
全连接神经网络的不足:
- 模型不够灵活,输入图片尺寸变换时网络需要修改
- 模型参数太多
卷积神经网络特点:
- 局部连接
- 权值共享
- 降采样
LENET-5网络模型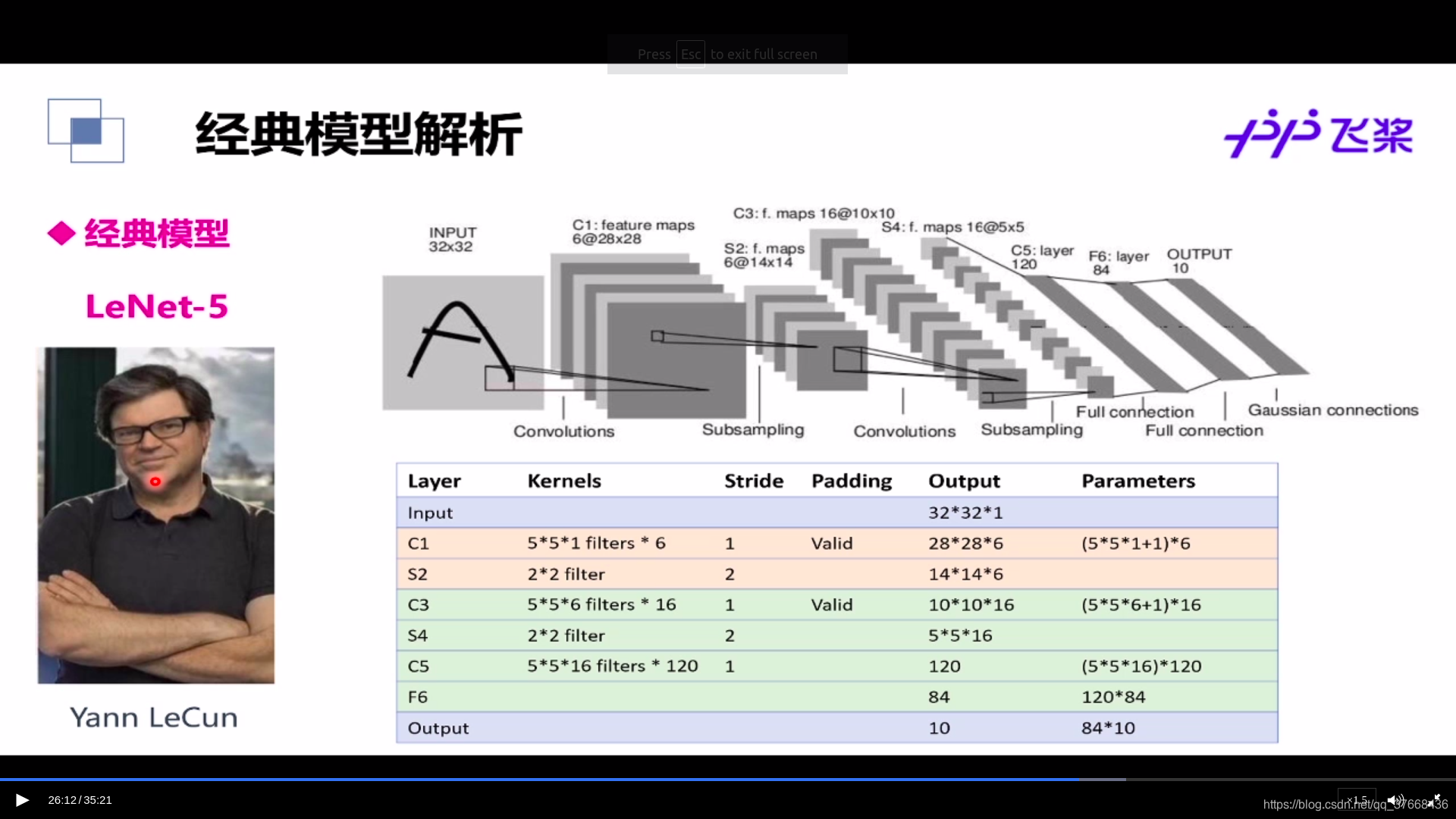
本节主要根据这张图设计LENET5模型并编写paddle代码。
首先看下卷积函数的定义源码:
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
padding=0,
dilation=1,
groups=None,
param_attr=None,
bias_attr=None,
use_cudnn=True,
act=None,
dtype='float32'):
- num_channels:通道数
- num_filters:卷积核数
- filter_size:卷积核大小,卷积核一般是正方形的所以就一个边长参数
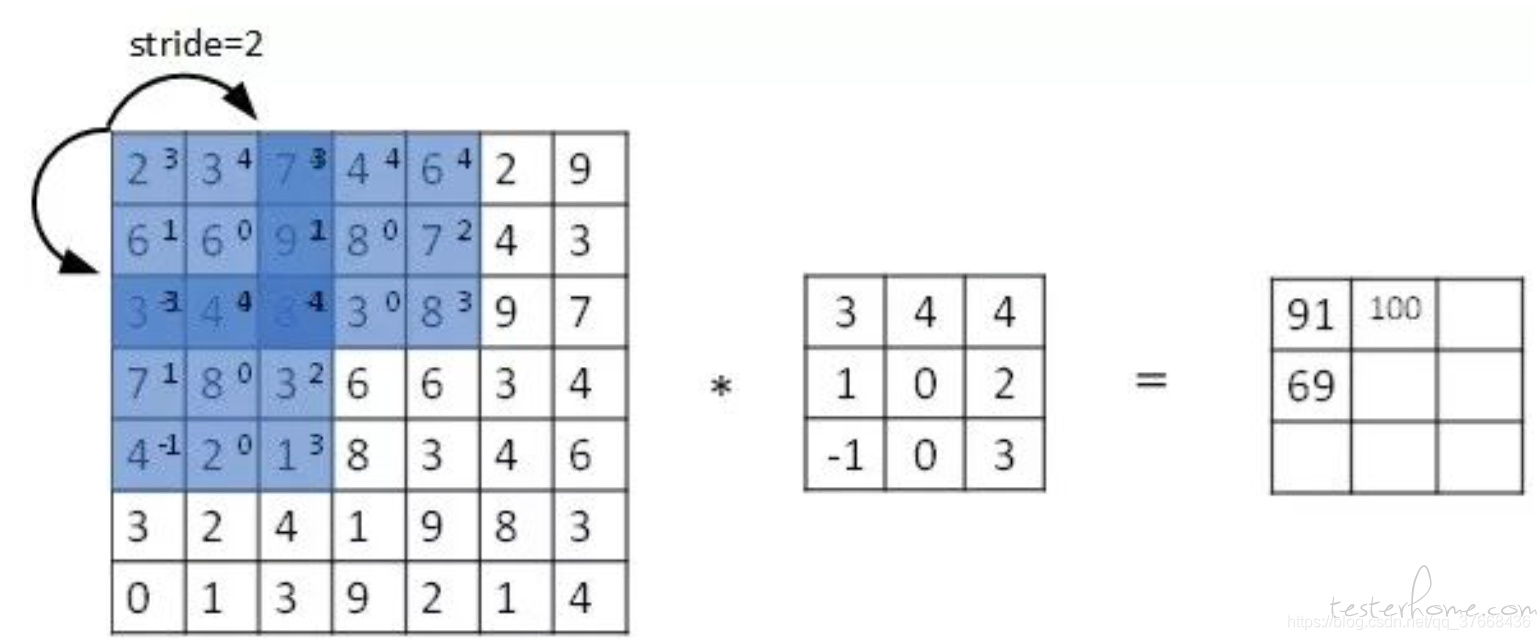
- stride:卷积步长
卷积步长参照下图,蓝色方格每次向右移动两列或向下移动两行表示步长为2:
分析LENET-5网络的input层
Yann LeCun教授的输入是灰度的图片单通道的,大小32 × 32。所以他的输入是32 × 32 × 1,但是我们用的手势数据是彩色的三通道的,所以我们需要做一点修改并且把输入的图片resize成32 × 32 × 3,resize代码:
images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)
分析LENET-5网络的C1层
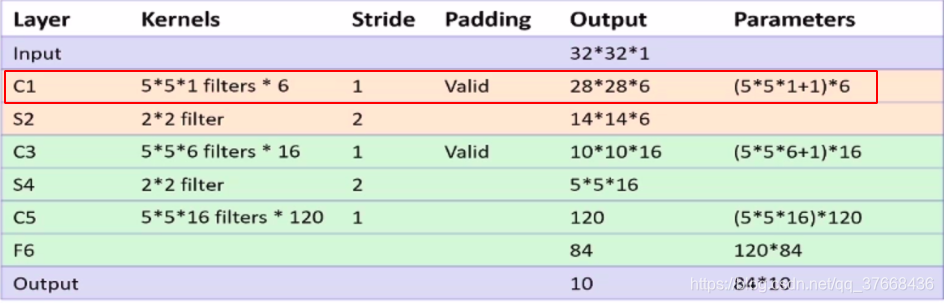
- 卷积核大小:5 * 5
- 卷积核数目:6
- 卷积步长:1
- 输入通道数: 3
这里要注意的就是卷积核数目,一个卷积核会对应图片的一种特征,n个卷积核就能得出n个特征,n个输出的特征就是下一层的通道个数。
这里我们说了采用的是彩色图片所以我们的input是32 * 32 * 3的,也就是C1层的输入是3通道的,C1层卷积核个数是6个,卷积核尺寸是5,步长是1所以得出paddle源码:
self.c1 = Conv2D(3, 6, 5, 1)
分析LENET-5网络的S2层池化层
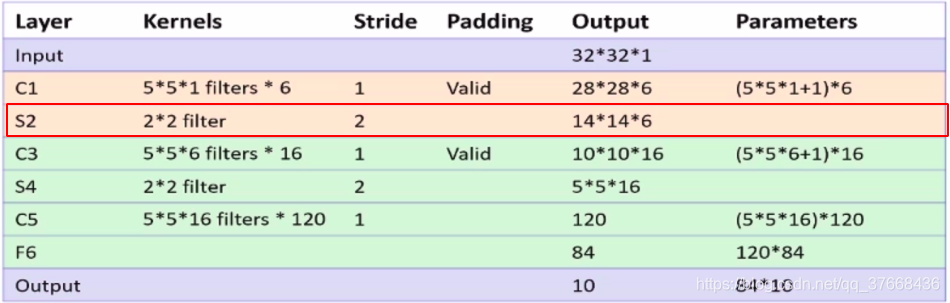
- 池化大小:2 × 2
- 池化步长:2
paddle源码:
self.s2 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)
分析LENET-5网络的C3层
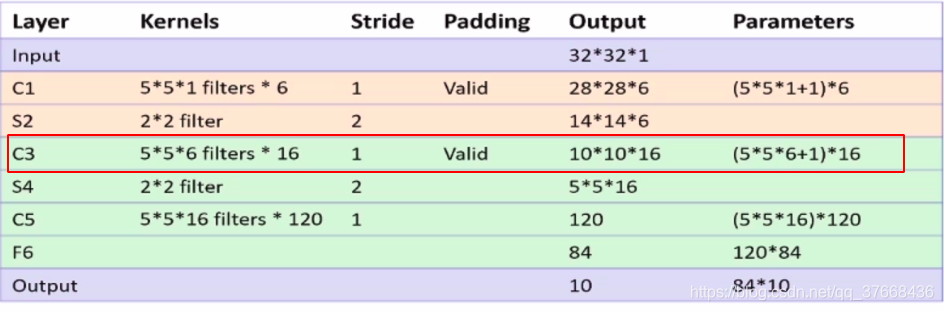
- 卷积核大小:5 * 5
- 卷积核数目:16
- 卷积步长:1
- 输入通道数:6
paddle源码:
self.c3 = Conv2D(6, 16, 5, 1)
分析LENET-5网络的S4层池化层
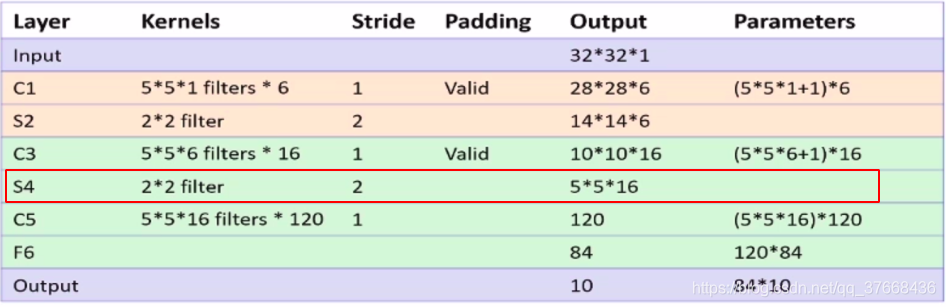
- 池化大小:2 × 2
- 池化步长:2
paddle源码:
self.s4 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)
分析LENET-5网络的C5层
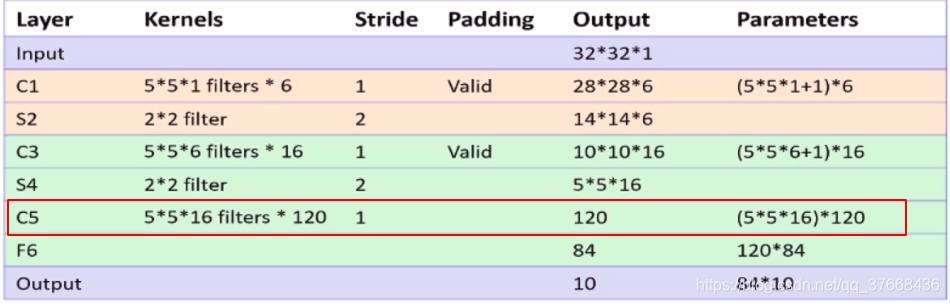
- 卷积核大小:5 * 5
- 卷积核数目:120
- 卷积步长:1
- 输入通道数:16
paddle源码:
self.c5 = Conv2D(16, 120, 5, 1)
分析LENET-5网络的F6层
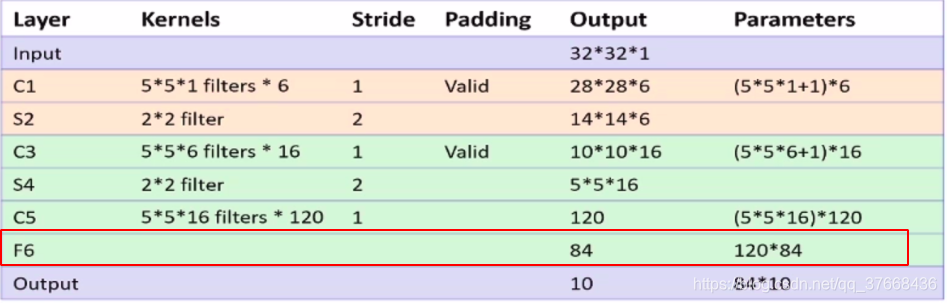
- 全连接层输入:120
- 全连接层输出:84
paddle源码:
self.f6 = Linear(120, 84, act='relu')
分析LENET-5网络的OUTPUT层
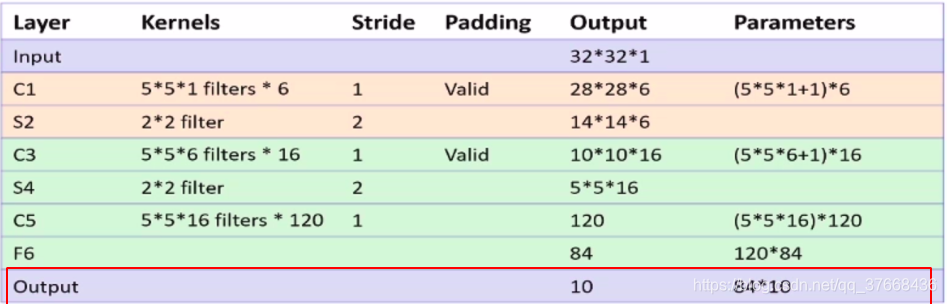
- 全连接层输入:84
- 全连接层输出:0
paddle源码:
self.f7 = Linear(84, 10, act='softmax')
前向传播模型构建
def forward(self, input):
print("input shape : " + str(input.shape))
x = self.c1(input)
print("C1 : " + str(x.shape))
x = self.s2(x)
print("S2 : " + str(x.shape))
x = self.c3(x)
print("C3 : " + str(x.shape))
x = self.s4(x)
print("S4 : " + str(x.shape))
x = self.c5(x)
print("C5 : " + str(x.shape))
x = fluid.layers.reshape(x, shape=[-1, 120])
x = self.f6(x)
y = self.f7(x)
return y
重点在这里:
x = fluid.layers.reshape(x, shape=[-1, 120])
在卷积层和全连接层间有一个过度,C5层的输出是120 × 1 × 1的,相当于是一维的,所以这里做了一个reshape,reshape中的-1参数表示设置为一维,120就是输入的通道数。
训练结果
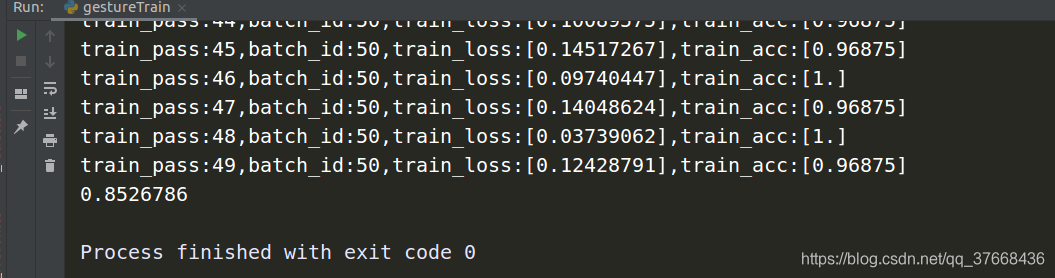
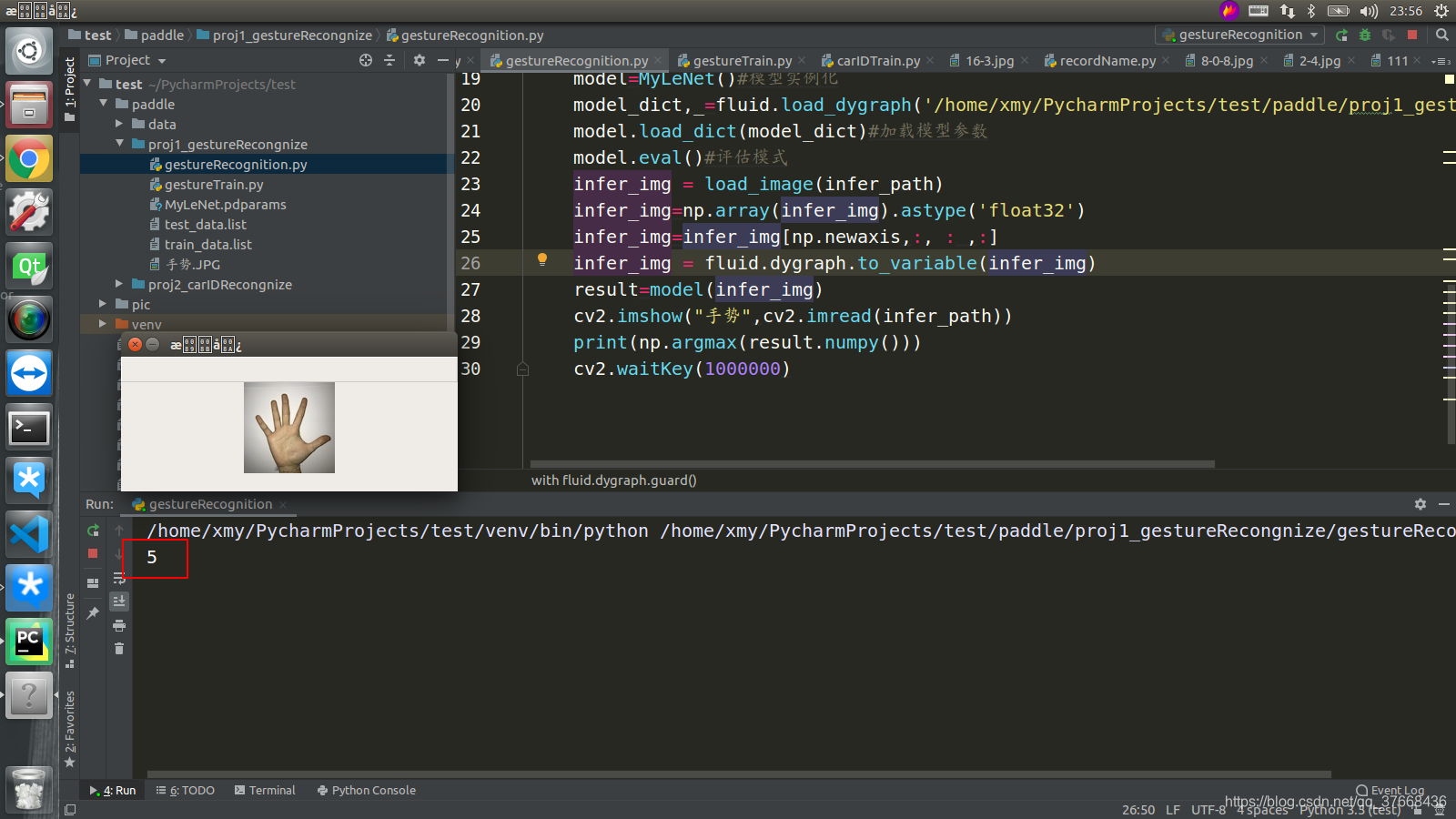
识别结果
完整训练代码
gestureTrain.py代码:
import os
import time
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
def makeListFile(data_path):
# 生成图像列表
#data_path = '/home/xmy/PycharmProjects/test/paddle/data/gesture'
# 返回指定的文件夹包含的文件或文件夹的名字的列表。
character_folders = os.listdir(data_path)
# 删除存在的train_data.list和test_data.list
if (os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if (os.path.exists('./test_data.list')):
os.remove('./test_data.list')
# 遍历所有的folder
for character_folder in character_folders:
# 写入train_data
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
# 遍历目录下的所有图片文件
character_imgs = os.listdir(os.path.join(data_path, character_folder))
# 用count图片分类
count = 0
for img in character_imgs:
# 这里是9:1的设置为训练集和测试集
if count % 10 == 0:
f_test.write(os.path.join(data_path, character_folder, img) + '\t' + character_folder + '\n')
else:
f_train.write(os.path.join(data_path, character_folder, img) + '\t' + character_folder + '\n')
count += 1
print('列表已生成')
# 对图片进行预处理
def data_mapper(sample):
img, label = sample
img = Image.open(img)
img = img.resize((32, 32), Image.ANTIALIAS)
img = np.array(img).astype('float32')
# 将读出来的rgb,rgb,rgb......转换成rrr......ggg......bbb
img = img.transpose((2, 0, 1))
# 对图片归一化
img = img / 255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 512)
#定义DNN网络
# class MyDNN(fluid.dygraph.Layer):
# def __init__(self):
# super(MyDNN,self).__init__()
# self.hidden1 = Linear(100,100,act='tanh')
# self.hidden2 = Linear(100,100,act='tanh')
# self.hidden3 = Linear(100,100,act='tanh')
# # 10是输出10类,3 × 100 × 100是做了个拉伸但是这样会跟hidden3的输出不匹配所以在前向传播的时候做了reshape
# self.hidden4 = Linear(3*100*100,10,act='softmax')
# def forward(self,input):
# x = self.hidden1(input)
# x = self.hidden2(x)
# x = self.hidden3(x)
# # 拉伸变换。这里搞不明白为什么要拉伸成3 × 100 × 100
# x = fluid.layers.reshape(x,shape=[-1,3*100*100])
# y = self.hidden4(x)
# return y
# 定义网络
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet, self).__init__()
self.c1 = Conv2D(3, 6, 5, 1)
self.s2 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)
self.c3 = Conv2D(6, 16, 5, 1)
self.s4 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)
self.c5 = Conv2D(16, 120, 5, 1)
self.f6 = Linear(120, 84, act='relu')
self.f7 = Linear(84, 10, act='softmax')
def forward(self, input):
print("input shape : " + str(input.shape))
x = self.c1(input)
print("C1 : " + str(x.shape))
x = self.s2(x)
print("S2 : " + str(x.shape))
x = self.c3(x)
print("C3 : " + str(x.shape))
x = self.s4(x)
print("S4 : " + str(x.shape))
x = self.c5(x)
print("C5 : " + str(x.shape))
x = fluid.layers.reshape(x, shape=[-1, 120])
# print(x.shape)
x = self.f6(x)
y = self.f7(x)
return y
if __name__ == '__main__':
data_path = '/home/xmy/PycharmProjects/test/paddle/data/gesture'
makeListFile(data_path)
# 用于训练的数据提供器,buf_size越大越乱序
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=256),
batch_size=32)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=32)
# 用动态图进行训练
with fluid.dygraph.guard():
model = MyLeNet() # 模型实例化
model.train() # 训练模式
opt = fluid.optimizer.SGDOptimizer(learning_rate=0.01,
parameter_list=model.parameters()) # 优化器选用SGD随机梯度下降,学习率为0.001.
epochs_num = 50 # 迭代次数
for pass_num in range(epochs_num):
for batch_id, data in enumerate(train_reader()):
# 将图片大小处理成3 * 32 × 32的为了与lenet相同
images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
# 给labels升维度
labels = labels[:, np.newaxis]
# print(images.shape)
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
predict = model(image) # 预测
# print(predict)
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss) # 获取loss值
acc = fluid.layers.accuracy(predict, label) # 计算精度
if batch_id != 0 and batch_id % 50 == 0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num, batch_id,
avg_loss.numpy(), acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(), 'MyLeNet') # 保存模型
# 模型校验
with fluid.dygraph.guard():
accs = []
model_dict, _ = fluid.load_dygraph('MyLeNet')
model = MyLeNet()
model.load_dict(model_dict) # 加载模型参数
model.eval() # 训练模式
for batch_id, data in enumerate(test_reader()): # 测试集
images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
predict = model(image)
acc = fluid.layers.accuracy(predict, label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
完整模型使用代码
gestureRecongnition.py
import numpy as np
from PIL import Image
import paddle.fluid as fluid
import cv2
from gestureTrain import MyLeNet
#读取预测图像,进行预测
def load_image(path):
img = Image.open(path)
img = img.resize((32, 32), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
print(img.shape)
return img
#构建预测动态图过程
with fluid.dygraph.guard():
infer_path = '/home/xmy/PycharmProjects/test/paddle/proj1_gestureRecongnize/手势.JPG'
model=MyLeNet()#模型实例化
model_dict,_=fluid.load_dygraph('/home/xmy/PycharmProjects/test/paddle/proj1_gestureRecongnize/MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
infer_img = load_image(infer_path)
infer_img=np.array(infer_img).astype('float32')
infer_img=infer_img[np.newaxis,:, : ,:]
infer_img = fluid.dygraph.to_variable(infer_img)
result=model(infer_img)
cv2.imshow("手势",cv2.imread(infer_path))
print(np.argmax(result.numpy()))
cv2.waitKey(1000)