最近“青春有你2”持续霸占各大榜单,本文爬取爱奇艺“青春有你2”下的评论,利用paddlehub对评论进行内容审核,通过审核后的数据进行词频统计并绘制词云。
首先,去爱奇艺视频地址底下爬取评论并保存在本地。由于爱奇艺的评论是利用ajax异步加载的,通过观察找到发起ajax请求url的规律,每次把url中的last_id替换成前一次响应结果中的最后一个id即可。
#请求爱奇艺评论接口,把每句评论保存在本地comments.txt中
def get_comments():
url='https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&content_id=15535092800&hot_size=0&last_id={}&page=&page_size=20&types=time&callback=jsonp_1587910020368_5150'
id=15535092800
p1='"id":"(.*?)","content":"(.*?)"'
with open('comments.txt','w') as f:
for i in range(100):
response=requests.get(url.format(id))
res=re.findall(p1,response.text)
id=res[-1][0]
for _,content in res:
f.write(content+'\n')
get_comments()
接下去需要用到paddlehub,安装完后在终端执行两条命令:
hub install porn_detection_lstm==1.1.0
hub serving start -m porn_detection_lstm
第一条是安装内容审核的模型,第二条是把模型部署到http接口中方便调用。
def text_detection():
'''
使用hub对评论进行内容分析
概率大于90%的认为是正常评论
'''
threshold=0.9
text_list=open('comments.txt').readlines()
text = {"text": text_list}
url = "http://127.0.0.1:8866/predict/text/porn_detection_lstm"
r = requests.post(url=url, data=text)
r_json=r.json()
for i in r_json['results']:
if i["not_porn_probs"]>threshold:
print(i['text'])
text_detection()
好了,得到审核通过的评论后,接下去我们要做的就是统计词频并绘制词云。
在统计词频前先去除文本中特殊字符
#去除文本中特殊字符
def clear_special_char():
with open('comments_filtered.txt','w') as f2:
for sentence in open('comments.txt'):
result = re.sub('\W+', '', sentence).replace("_", '')
f2.write(result+'\n')
clear_special_char()
然后利用jieba这个第三方库进行分词,分词前记得把参赛小姐姐的姓名加入词库中。
from collections import defaultdict
count_dict=defaultdict(int)
def fenci():
'''
利用jieba进行分词
'''
name_list=['符佳', '胡馨尹', '魏奇奇', '陈昕葳', '阿依莎', '粟钦柔', '勾雪莹', '熊钰清', '周梓倩', '戴燕妮', '张洛菲', '左卓', '李依宸', '卓依娜姆', '七穗', '段艺璇', '费沁源', '马蜀君', '程曼鑫', '许馨文', '蔡卓宜', '乃万', '姚依凡', '申玉', '段小薇', '徐轸轸', '喻言', '许佳琪', '汪睿', '艾霖', '孙美楠', '秦牛正威', '张钰', '安崎', '王姝慧', '杜紫怡', '宋昕冉', '邹思扬', '刘令姿', '查祎琛', '孙芮', '谢可寅', '张楚寒', '林小宅', '李熙凝', '周琳聪', '林慧博', '虞书欣', '黄欣苑', '王瑶瑶', '沈莹', '夏研', '墨谣', '张天馨', '陈珏', '申清', '申洁', '艾依依', '冯若航', '赵小棠', '林凡', '王欣宇', '唐珂伊', '朱林雨', '刘亚楠', '米拉', '宋昭艺', '王婉辰', '权笑迎', '申冰', '郑玉歆', '徐百仪', '杨宇彤', '王思予', '苏杉杉', '林韦希', '戴萌', '莫寒', '王清', '上官喜爱', '傅如乔', '希娅', '许杨玉琢', '刘海涵', '文哲', '孔雪儿', '魏辰', '陆柯燃', '黄一鸣', '葛鑫怡', '黄小芸', '靳阳阳', '陈品瑄', '张梦露', '金吉雅', '曾可妮', '徐紫茵', '刘雨昕', '何美延', '陈艺文', '未书羽', '张语格', '王雅乐', '金子涵', '韩东', '王承渲', '符雅凝', '欧若拉', '王心茗']
with open('name.txt','w') as f:
for i in name_list:
f.write(i+'\n')
jieba.load_userdict("name.txt")
with open('comments_completed.txt','w') as f2:
for s in open('comments_filtered.txt'):
res=jieba.cut(s.rstrip('\n'))
for i in res:
f2.write(' '.join(res)+'\n')
count_dict[i]+=1
fenci()
print(count_dict)
分词完后发现有很多例如’我‘,’你‘这种没有意义的停用词也被统计进去了,从网上找一个中文的停用词表stopwords.txt,把统计结果中包含停用词的结果删除。
def movestopwords():
'''
去除停用词,统计词频
'''
file_path='stopwords.txt'
stoplist=[i.rstrip('\n') for i in open(file_path)]
key_set=set(count_dict.keys())
for key in key_set:
if key in stoplist:
count_dict.pop(key)
movestopwords()
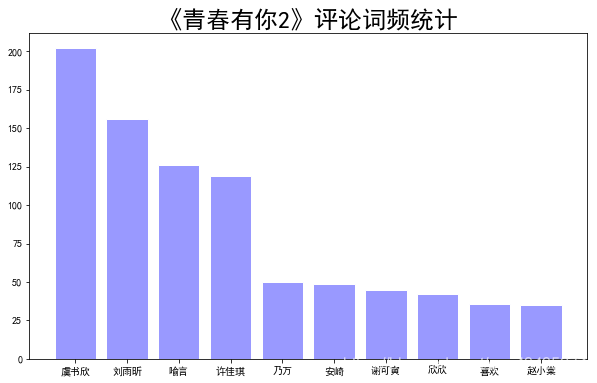
接下去利用matplotlib绘制top10词频统计表
def drawcounts():
'''
绘制词频统计表
'''
res=[(k,v) for k,v in count_dict.items()]
res.sort(key=lambda x:x[1],reverse=True)
print(res[:10])
top10=res[:10]
x,y=zip(*top10)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10,6))
plt.bar(x,y,facecolor='#9999ff',edgecolor='white')
plt.title('''《青春有你2》评论词频统计''',fontsize = 24)
plt.show()
drawcounts()
结果如下:
最后把所有词频利用WordCloud这个第三方库绘制出词云,这里我用的默认的矩形形状,大家可以选择自己喜欢的形状。
def drawcloud():
'''
根据词频绘制词云图
'''
# text = open('comments_completed.txt').read()
# wc = WordCloud(font_path='simhei.ttf',width=800, height=600, mode='RGBA', background_color=None,stopwords=stopwordslist(),collocations=False).generate(text)
wc = WordCloud(font_path='simhei.ttf',width=800, height=600, mode='RGBA', background_color=None,stopwords=stopwordslist(),collocations=False).generate_from_frequencies(count_dict)
# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
# 保存到文件
wc.to_file('wordcloud.png') # 生成图像是透明的
drawcloud()
好了,看一下最终的效果吧:(词语越大说明评论中出现次数越多)
