1. 堆概念
二叉堆的性能有很大的问题,现实中很大高级的堆用的是斐波拉契堆和加的堆。
https://www.cnblogs.com/skywang12345/p/3610187.html#a1
https://en.wikipedia.org/wiki/Binary_heap
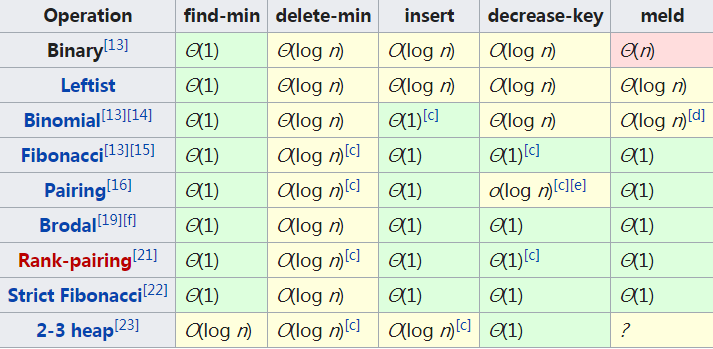
堆是一种特殊的树。只要满足这两点,它就是一个堆:
-
堆是一个完全二叉树;
-
堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
第一点,堆必须是一个完全二叉树。完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。

第二点,堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,还有换一种说法,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都大于等于子树中每个节点值的堆,叫作“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,叫作“小顶堆”。

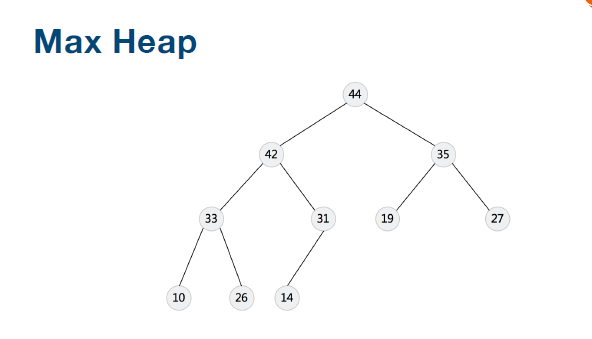
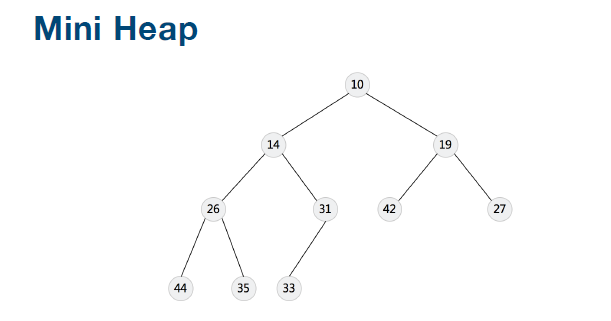
小顶堆--越小的越排到前边;每一个根节点都大于它的左右节点;最顶的节点最大;
从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。
Heap Wiki
https://en.wikipedia.org/wiki/Heap_(data_structure)
Google 搜索 heap 或者 堆

2. 堆的存储
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为不需存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
我画了一个用数组存储堆的例子,你可以先看下。

上图中i=1存储根节点,下标为 i 的节点的左子节点就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1 的节点,父节点就是下标为 i / 2 的节点;
如果i=0存储根节点,下标为 ii 的节点的左子节点就是下标为 i∗2+1 的节点,右子节点就是下标为 i∗2+2 的节点,但父节点的下标为 (i - 1) / 2 。
1. 往堆中插入一个元素
往堆中插入一个元素后,我们需要继续满足堆的两个特性。如果把新插入的元素放到堆的最后,就不符合堆的特性了。调整让它重新满足堆的特性,这个过程就叫作堆化(heapify)。
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。堆化方法有两种: 从下往上和从上往下。
从下往上

2. 删除堆顶元素
从堆的定义的第二条中,任何节点的值都大于等于(或小于等于)子树节点的值,堆顶元素存储的就是堆中数据的最大值或者最小值。
对于大顶堆,
堆顶元素就是最大的元素。当我们删除堆顶元素之后,就需要把第二大的元素放到堆顶,那第二大元素肯定会出现在左右子节点中。然后我们再迭代地删除第二大节点,以此类推,直到叶子节点被删除。(这种操作最后堆化出来的堆并不满足完全二叉树的特性,会出现数组空洞。)
把最后一个节点放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止。这就是从上往下的堆化方法。因为我们移除的是数组中的最后一个元素,而在堆化的过程中,都是交换操作,不会出现数组中的“空洞”,所以这种方法堆化之后的结果,肯定满足完全二叉树的特性。

一个包含 n 个节点的完全二叉树,树的高度小于 log2n,堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,为O(log n)。
插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 O(log n)。
3. 堆排序
借助堆这种数据结构实现的排序算法,就叫堆排序。这种排序方法的时间复杂度非常稳定,是 O(nlogn),并且它还是原地排序算法。如此优秀
堆排序大致分成两个大的步骤: 建堆和排序。
建堆
首先将数组原地建成一个堆。所谓“原地”就是,不借助另一个数组,就在原数组上操作。
建堆的过程,有两种思路:
第一种是借助前边所说的在堆中插入一个元素的思路。尽管数组中包含 n 个数据,但可以假设,起初堆中只包含一个数据,就是下标为 1 的数据。然后,调用插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样我们就将包含 n 个数据的数组,组织成了堆。
这种思路的处理过程是从前往后处理数组数据,并且每个数据插入堆中时,都是从下往上堆化。
第二种跟第一种截然相反,是从后往前处理数组,并且每个数据都是从上往下堆化。
因为叶子节点往下堆化只能自己跟自己比较,所以我们直接从第一个非叶子节点开始,依次堆化就行了。
