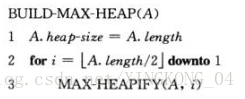本帖中讲述的是堆数据结构,而不是垃圾收集存储
什么是堆
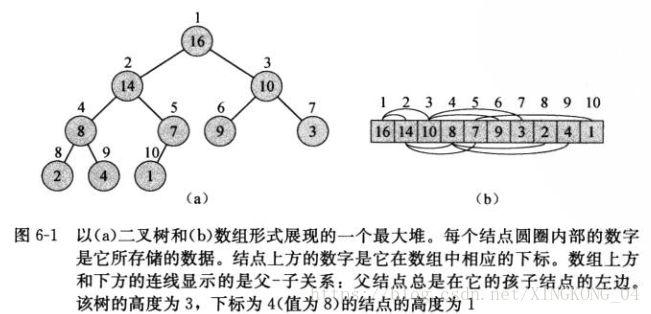
堆,这里指二叉堆,是一个数组,可以被看成一个近似的完全二叉树。
树上的每一个结点代表数组中的一个元素。
除最底层外,该树是完全充满的,而且是从左向右填充。(根据堆的填充顺序,只有将上一层填满,才能在下一层出现数据,因此对重除最底层的其他层中都已经被完全充满了)
堆的一些属性
两个参数属性:现有数组A,A.length表示数组的长度,A.heapsize表示数组中在堆中的元素数量。
现有下标为i的结点,父结点的下标为i/2;左子结点为2i;右子结点为2i+1。
堆中任意结点的高度为该结点到叶结点的最长简单路径上边的数目。
包含n个元素的堆的高度为lgn。
当用数组表示存储n个元素的堆时,叶结点下标分别是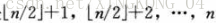
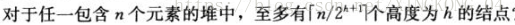
最大堆和最小堆
最大堆:除了根以外的所有结点i都满足: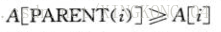
最小堆:除了根以外的所有结点i都满足: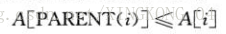
维护堆的性质
MAX-HEAPIFY维护最大堆的性质。
输入为一个数组A和一个下标i,假定i结点的左右子树都已经是最大堆。A[i]的值可能小于其孩子的值,违背最大堆的性质。
MAX-HEAPIFY采用让A[i]的值在最大堆中“逐级下降”的方式,使得以下标i为根结点的子树重新遵循最大堆性质。
(理解:下标为i的结点A[i]与其左右子结点的值比较大小,找到其中最大的值,在largest中记录下标,将最大的值存放在i位置上,使用递归的思想,将largest记录的下标作为新的输入参数)。


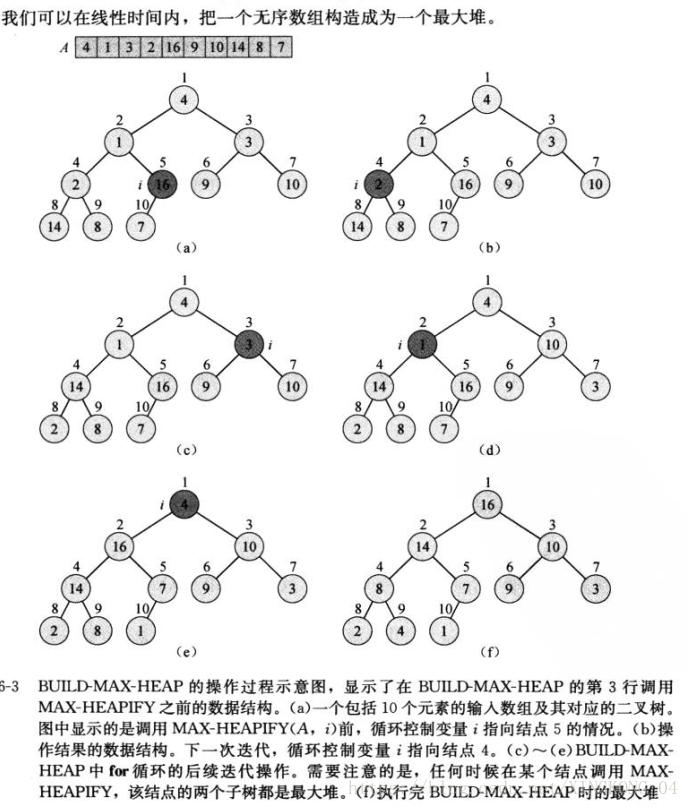
建堆
思想:使用自底向上的方法利用MAX-HEAPIFY把一个大小为n=A.length的数组A[1..0]转换为最大堆。