上一章:深度篇——实例分割(一) mask rcnn 论文 翻译 和 总结
下一章: 深度篇——实例分割(三) 细说 mask rcnn 实例分割代码 训练自己数据 之 相关网络,数据处理,工具等
论文地址:《Mask R-CNN》
作者代码地址:Mask R-CNN code
我优化的代码地址:mask_rcnn_pro (只需修改一下 config.py 配置,就可以直接跑的)
本小节,细说 mask rcnn 实例分割代码讲解,下一小节 细说 mask rcnn 实例分割代码 训练自己数据 相关网络,数据处理,工具等
在开始代码讲解前,先向 何恺明 大帝敬礼!
我的代码,是参考论文提供的代码来优化的。在对 mask rcnn 的学习中,我发现,作者提供的 mask_rcnn_coco.h5 模型非常强大(毕竟人家当初是用 8 个 GPU 训练出来的,而且经过不断调参验证得到的,而大帝在论文中,也把别人超得理所当然)。
作者提供的数据:
train2014 data:
http://images.cocodataset.org/zips/train2014.zip
http://images.cocodataset.org/annotations/annotations_trainval2014.zip

val2014 data(valminusminival):
http://images.cocodataset.org/zips/val2014.zip
https://dl.dropboxusercontent.com/s/s3tw5zcg7395368/instances_valminusminival2014.json.zip?dl=0
val2014 data(minival):
http://images.cocodataset.org/zips/val2014.zip
https://dl.dropboxusercontent.com/s/o43o90bna78omob/instances_minival2014.json.zip?dl=0
对于无法科学上网的朋友,提供如下百度云链接:
mask_rcnn_coco.h5 模型: 链接:https://pan.baidu.com/s/1-_zxnWCmE9Vea7UOsl0naQ 提取码:y7gr
coco data 链接:https://pan.baidu.com/s/1gYAR4cxp1femrh8YgB6R7A 提取码:8xkx
下面开始搬砖:

二. 制作 labelme 的 json 数据
跑别人的代码,别人的数据,不是目的。要做一个适合自己数据的代码,跑自己的数据,才是硬道理。
1. 首先,先安装 labelme,这个非常简单,下面讲解在 conda 环境下安装 labelme:
# 打开命令窗口
# 创建虚拟环境,并命名为 labelme,指定解释器为python3.6
conda create -n labelme python=3.6
# windows 进入conda 的虚拟环境:
activate labelme
# linux 下进入虚拟环境:
source activate labelme
# 第一次进入虚拟环境,先更新pip, 避免后面安装报版本错误:
python -m pip install --upgrade pip
# 接下来是重头戏, labelme 只需安装以下 3 个库 即可使用:
conda install pyqt
conda install pillow
pip install labelme
# 安装好后,直接输入命令: labelme 可以开启labelme 工具2. 使用 labelme 标记图像


3. 生成的数据如下:
4. 将数据放入到对应文件夹中:


三. 将我们的数据制作成 coco dataset。
在接触代码前,先看一下项目文件结构

README.md 文件信息如下:
# Mask R-CNN for Object Detection and Segmentation
# [mask_rcnn_pro](https://github.com/wandaoyi/mask_rcnn_pro)
- [论文地址](https://arxiv.org/abs/1703.06870)
- [我的 CSDN 博客](https://blog.csdn.net/qq_38299170/article/details/105233638)
本项目使用 python3, keras 和 tensorflow 相结合。本模型基于 FPN 网络 和 resNet101 背骨,对图像中的每个目标生成 bounding boxes 和 分割 masks。
The repository includes:
* Source code of Mask R-CNN built on FPN and ResNet101.
* Training code for MS COCO
* Pre-trained weights for MS COCO
* Jupyter notebooks to visualize the detection pipeline at every step
* ParallelModel class for multi-GPU training
* Evaluation on MS COCO metrics (AP)
* Example of training on your own dataset
```bashrc
mask_rcnn_coco.h5:
- https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
train2014 data:
- http://images.cocodataset.org/zips/train2014.zip
- http://images.cocodataset.org/annotations/annotations_trainval2014.zip
val2014 data(valminusminival):
- http://images.cocodataset.org/zips/val2014.zip
- https://dl.dropboxusercontent.com/s/s3tw5zcg7395368/instances_valminusminival2014.json.zip?dl=0
val2014 data(minival):
- http://images.cocodataset.org/zips/val2014.zip
- https://dl.dropboxusercontent.com/s/o43o90bna78omob/instances_minival2014.json.zip?dl=0
```
# Getting Started
* 参考 config.py 文件配置。
* 下面文件中 def __init__(self) 方法中的配置文件,基本都是来自于 config.py
* 测试看效果:
* mask_test.py 下载好 mask_rcnn_coco.h5 模型,随便找点数据,设置好配置文件,直接运行看结果吧。
* 数据处理:
* prepare.py 直接运行代码,将 labelme json 数据制作成 coco json 数据。
* 并将数据进行划分
* 数据训练:
* mask_train.py 直接运行代码,观察 loss 情况。
* mask_rcnn_coco.h5 作为预训练模型很强,训练模型会有一个很好的起点。
* 多 GPU 训练:
* parallel_model.py: 本人没有多 GPU,这一步没做到验证,里面的代码,是沿用作者的。
* 本项目,操作上,就三板斧搞定,不搞那么复杂,吓到人。
代码,我基本做成傻瓜式一键运行,基本不用修改代码,修改一下配置就 OK 的了。
config.py 文件如下:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# ============================================
# @Time : 2020/04/15 22:53
# @Author : WanDaoYi
# @FileName : config.py
# ============================================
import os
from easydict import EasyDict as edict
# mask_rcnn_coco.h5 预训练模型下载地址: https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
__C = edict()
# Consumers can get config by: from config import cfg
cfg = __C
# common options 公共配置文件
__C.COMMON = edict()
# 论文中的模型 url
__C.COMMON.COCO_MODEL_URL = "https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5"
# 相对路径 当前路径
__C.COMMON.RELATIVE_PATH = "./"
# mask 默认背景 类别, 背景为第一个类别
__C.COMMON.DEFAULT_CLASS_INFO = [{"source": "", "id": 0, "name": "BG"}]
__C.COMMON.DATA_SET_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "dataset")
# 原始图像 文件 路径
__C.COMMON.IMAGE_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "dataset/images")
# labelme 生成的 json 注释文件 路径
__C.COMMON.JSON_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "dataset/ann_json")
# 是否删除已有文件,True 为删除,False 为不删除
__C.COMMON.FILE_EXISTS_FLAG = True
# 数据划分比例
__C.COMMON.TEST_PERCENT = 0.7
__C.COMMON.VAL_PERCENT = 0.2
__C.COMMON.TEST_PERCENT = 0.1
# 数据来源
__C.COMMON.DATA_SOURCE = "our_data"
# 文件后缀名
__C.COMMON.JSON_SUFFIX = ".json"
__C.COMMON.PNG_SUFFIX = ".png"
__C.COMMON.JPG_SUFFIX = ".jpg"
__C.COMMON.TXT_SUFFIX = ".txt"
# 划分数据的保存路径
__C.COMMON.TRAIN_DATA_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/train_data.txt")
__C.COMMON.VAL_DATA_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/val_data.txt")
__C.COMMON.TEST_DATA_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/test_data.txt")
__C.COMMON.LOGS_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "logs")
# coco_class_names.txt 文件路径
__C.COMMON.COCO_CLASS_NAMES_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/coco_class_names.txt")
__C.COMMON.OUR_CLASS_NAMES_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/our_class_names.txt")
# Input image resizing
# Generally, use the "square" resizing mode for training and predicting
# and it should work well in most cases. In this mode, images are scaled
# up such that the small side is = IMAGE_MIN_DIM, but ensuring that the
# scaling doesn't make the long side > IMAGE_MAX_DIM. Then the image is
# padded with zeros to make it a square so multiple images can be put
# in one batch.
# Available resizing modes:
# none: No resizing or padding. Return the image unchanged.
# square: Resize and pad with zeros to get a square image
# of size [max_dim, max_dim].
# pad64: Pads width and height with zeros to make them multiples of 64.
# If IMAGE_MIN_DIM or IMAGE_MIN_SCALE are not None, then it scales
# up before padding. IMAGE_MAX_DIM is ignored in this mode.
# The multiple of 64 is needed to ensure smooth scaling of feature
# maps up and down the 6 levels of the FPN pyramid (2**6=64).
# crop: Picks random crops from the image. First, scales the image based
# on IMAGE_MIN_DIM and IMAGE_MIN_SCALE, then picks a random crop of
# size IMAGE_MIN_DIM x IMAGE_MIN_DIM. Can be used in training only.
# IMAGE_MAX_DIM is not used in this mode.
__C.COMMON.IMAGE_RESIZE_MODE = "square"
__C.COMMON.IMAGE_MIN_DIM = 800
__C.COMMON.IMAGE_MAX_DIM = 1024
# Minimum scaling ratio. Checked after MIN_IMAGE_DIM and can force further
# up scaling. For example, if set to 2 then images are scaled up to double
# the width and height, or more, even if MIN_IMAGE_DIM doesn't require it.
# However, in 'square' mode, it can be overruled by IMAGE_MAX_DIM.
__C.COMMON.IMAGE_MIN_SCALE = 0
# 是否 crop 操作,True 为 crop
__C.COMMON.CROP_FLAG = False
# 训练输入图像的 shape
if __C.COMMON.CROP_FLAG:
# [h, w, c]
__C.COMMON.IMAGE_SHAPE = [800, 800, 3]
else:
__C.COMMON.IMAGE_SHAPE = [1024, 1024, 3]
# 1 background + n classes
# __C.COMMON.CLASS_NUM = 1 + 80
__C.COMMON.CLASS_NUM = 1 + 1
# image_id(1维) + original_image_shape(3维) + image_shape(3维) + image_coor(y1, x1, y2, x2)(4维) +
# scale(1维) + class_num(类别数)
# 参考 compose_image_meta() 方法
__C.COMMON.IMAGE_META_SIZE = 1 + 3 + 3 + 4 + 1 + __C.COMMON.CLASS_NUM
# backbone 支持 resNet50 和 resNet101
__C.COMMON.BACKBONE = "resNet101"
# The strides of each layer of the FPN Pyramid. These values
# are based on a resNet101 backbone.
__C.COMMON.BACKBONE_STRIDES = [4, 8, 16, 32, 64]
# Train or freeze batch normalization layers
# None: Train BN layers. This is the normal mode
# False: Freeze BN layers. Good when using a small batch size
# True: (don't use). Set layer in training mode even when predicting
# Defaulting to False since batch size is often small
__C.COMMON.TRAIN_FLAG = False
# Size of the top-down layers used to build the feature pyramid
__C.COMMON.TOP_DOWN_PYRAMID_SIZE = 256
# Length of square anchor side in pixels
__C.COMMON.RPN_ANCHOR_SCALES = (32, 64, 128, 256, 512)
# Ratios of anchors at each cell (width/height)
# A value of 1 represents a square anchor, and 0.5 is a wide anchor
__C.COMMON.RPN_ANCHOR_RATIOS = [0.5, 1, 2]
# Anchor stride
# If 1 then anchors are created for each cell in the backbone feature map.
# If 2, then anchors are created for every other cell, and so on.
__C.COMMON.RPN_ANCHOR_STRIDE = 1
# Bounding box refinement standard deviation for RPN and final detections.
__C.COMMON.RPN_BBOX_STD_DEV = [0.1, 0.1, 0.2, 0.2]
__C.COMMON.BBOX_STD_DEV = [0.1, 0.1, 0.2, 0.2]
# Image mean (RGB)
__C.COMMON.MEAN_PIXEL = [123.7, 116.8, 103.9]
# ROIs kept after tf.nn.top_k and before non-maximum suppression
__C.COMMON.PRE_NMS_LIMIT = 6000
# Non-max suppression threshold to filter RPN proposals.
# You can increase this during training to generate more propsals.
__C.COMMON.RPN_NMS_THRESHOLD = 0.7
# Minimum probability value to accept a detected instance
# ROIs below this threshold are skipped
__C.COMMON.DETECTION_MIN_CONFIDENCE = 0.7
# Pooled ROIs
__C.COMMON.POOL_SIZE = 7
__C.COMMON.MASK_POOL_SIZE = 14
# Size of the fully-connected layers in the classification graph
__C.COMMON.FPN_CLASS_FC_LAYERS_SIZE = 1024
# NUMBER OF GPUs to use. When using only a CPU, this needs to be set to 1.
__C.COMMON.GPU_COUNT = 1
# Loss weights for more precise optimization.
# Can be used for R-CNN training setup.
__C.COMMON.LOSS_WEIGHTS = {"rpn_class_loss": 1.,
"rpn_bbox_loss": 1.,
"mrcnn_class_loss": 1.,
"mrcnn_bbox_loss": 1.,
"mrcnn_mask_loss": 1.
}
# mask train options 训练配置文件
__C.TRAIN = edict()
__C.TRAIN.DATA_SOURCE = "coco"
__C.TRAIN.DATA_SOURCE_INFO = "our_data"
__C.TRAIN.COCO_TRAIN_ANN_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/train_data.json")
__C.TRAIN.COCO_TRAIN_IMAGE_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "dataset/images")
__C.TRAIN.COCO_VAL_ANN_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/val_data.json")
__C.TRAIN.COCO_VAL_IMAGE_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "dataset/images")
__C.TRAIN.MODEL_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "models/mask_rcnn_coco.h5")
__C.TRAIN.SAVE_MODEL_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "models/mask_rcnn_coco_{epoch:04d}.h5")
__C.TRAIN.LOGS_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "logs")
# If enabled, resizes instance masks to a smaller size to reduce
# memory load. Recommended when using high-resolution images.
__C.TRAIN.USE_MINI_MASK = True
# (height, width) of the mini-mask
__C.TRAIN.MINI_MASK_SHAPE = (56, 56)
# Maximum number of ground truth instances to use in one image
__C.TRAIN.MAX_GT_INSTANCES = 100
# Shape of output mask
# To change this you also need to change the neural network mask branch
__C.TRAIN.MASK_SHAPE = [28, 28]
# train batch size
__C.TRAIN.BATCH_SIZE = 1
# learning rate for rough train
__C.TRAIN.ROUGH_LEARNING_RATE = 0.001
# learning rate for fine-tuning
__C.TRAIN.FINE_LEARNING_RATE = 0.0001
__C.TRAIN.WEIGHT_DECAY = 0.0001
# momentum 超参
__C.TRAIN.LEARNING_MOMENTUM = 0.9
# Gradient norm clipping
__C.TRAIN.GRADIENT_CLIP_NORM = 5.0
# n_epoch for rough train
__C.TRAIN.FIRST_STAGE_N_EPOCH = 32
# n_epoch for convergence loss
__C.TRAIN.MIDDLE_STAGE_N_EPOCH = 128
# n_epoch for fine-tuning
__C.TRAIN.LAST_STAGE_N_EPOCH = 256
# Training network heads
__C.TRAIN.HEADS_LAYERS = "heads"
# Fine tune ResNet stage 4 and up
__C.TRAIN.FOUR_MORE_LAYERS = "4+"
# Fine tune all layers
__C.TRAIN.ALL_LAYERS = "all"
# Number of training steps per epoch
# This doesn't need to match the size of the training set. Tensorboard
# updates are saved at the end of each epoch, so setting this to a
# smaller number means getting more frequent TensorBoard updates.
# Validation stats are also calculated at each epoch end and they
# might take a while, so don't set this too small to avoid spending
# a lot of time on validation stats.
__C.TRAIN.STEPS_PER_EPOCH = 1000
# Number of validation steps to run at the end of every training epoch.
# A bigger number improves accuracy of validation stats, but slows
# down the training.
__C.TRAIN.VALIDATION_STEPS = 50
# ROIs kept after non-maximum suppression
__C.TRAIN.POST_NMS_ROIS = 2000
# Number of ROIs per image to feed to classifier/mask heads
# The Mask RCNN paper uses 512 but often the RPN doesn't generate
# enough positive proposals to fill this and keep a positive:negative
# ratio of 1:3. You can increase the number of proposals by adjusting
# the RPN NMS threshold.
__C.TRAIN.ROIS_PER_IMAGE = 200
# Percent of positive ROIs used to train classifier/mask heads
__C.TRAIN.ROI_POSITIVE_RATIO = 0.33
# Use RPN ROIs or externally generated ROIs for training
# Keep this True for most situations. Set to False if you want to train
# the head branches on ROI generated by code rather than the ROIs from
# the RPN. For example, to debug the classifier head without having to
# train the RPN.
__C.TRAIN.USE_RPN_ROIS = True
# Pre-defined layer regular expressions
# heads: all layers but the backbone
__C.TRAIN.LAYER_REGEX = {"heads": r"(mrcnn\_.*)|(rpn\_.*)|(fpn\_.*)",
# 3+, 4+, 5+: From a specific ResNet stage and up
"3+": r"(res3.*)|(bn3.*)|(res4.*)|(bn4.*)|(res5.*)|(bn5.*)|(mrcnn\_.*)|(rpn\_.*)|(fpn\_.*)",
"4+": r"(res4.*)|(bn4.*)|(res5.*)|(bn5.*)|(mrcnn\_.*)|(rpn\_.*)|(fpn\_.*)",
"5+": r"(res5.*)|(bn5.*)|(mrcnn\_.*)|(rpn\_.*)|(fpn\_.*)",
# all: All layers
"all": ".*",
}
# Augmenters that are safe to apply to masks
# Some, such as Affine, have settings that make them unsafe, so always
# test your augmentation on masks
__C.TRAIN.MASK_AUGMENTERS = ["Sequential", "SomeOf", "OneOf", "Sometimes",
"Fliplr", "Flipud", "CropAndPad",
"Affine", "PiecewiseAffine"]
# How many anchors per image to use for RPN training
__C.TRAIN.ANCHORS_PER_IMAGE = 256
# mask_test options 测试配置文件
__C.TEST = edict()
# model 文件路径
__C.TEST.COCO_MODEL_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "models/mask_rcnn_coco_0001.h5")
__C.TEST.SAVE_MODEL_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "models")
__C.TEST.TEST_INFO_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "infos/test.txt")
__C.TEST.TEST_IMAGE_FILE_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "dataset/test_image")
__C.TEST.OUTPUT_IMAGE_PATH = os.path.join(__C.COMMON.RELATIVE_PATH, "output_info/images")
__C.TEST.POST_NMS_ROIS = 1000
# TEST batch size
__C.TEST.BATCH_SIZE = 1
# Max number of final detections
__C.TEST.DETECTION_MAX_INSTANCES = 100
__C.TEST.DETECTION_NMS_THRESHOLD = 0.3
1. 不熟悉 coco dataset 的朋友,可以先加载作者提供的数据,观察数据结构,下面为部分数据可视化:(直接运行 coco_dataset.py 文件,打印 coco 数据可视化)


2. 将我们的 labelme json 数据,做成 coco json 数据,代码如下:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# ============================================
# @Time : 2020/05/21 15:53
# @Author : WanDaoYi
# @FileName : prepare.py
# ============================================
"""
从 coco 的 json 数据中,得到一张图片的标注信息如下,包含5大部分的字段信息:
"info"的value是一个dict,存储数据集的一些基本信息,我们不需要关注;
"licenses"的value是一个list,存储license信息,我们不需要关注;
"categories"的value是一个list,存储数据集的类别信息,包括类别的超类、类别id、类别名称;
“images”的value是一个list,存储这张图片的基本信息,包括图片名、长、宽、id等重要信息;
"annotations"的value是一个list,存储这张图片的标注信息,非常重要,list中的每一个元素是一个dict,
也即一个标注对象(instance)的信息。包括的字段有"segmentation":标注点的坐标,
从第一个的x,y坐标一直到最后一个点的x,y坐标;
"area"是标注的闭合多边形的面积;
"iscrowd"表示对象之间是否有重叠; 0 表示不重叠
"image_id"是图片的id;
"bbox"是instance的边界框的左上角的x,y,边界框的宽和高;
"category_id"是这个instance对应的类别id;
"id"表示此instance标注信息在所有instance标注信息中的id。
"""
from datetime import datetime
import os
import json
import random
import numpy as np
from config import cfg
class Prepare(object):
def __init__(self):
self.label_me_json_file_path = "./dataset/ann_json"
self.ori_image_file_path = "./dataset/images"
self.save_data_path = "./infos"
self.cate_and_super = self.load_json_data("./infos/cate_and_super.json")
# 默认 BG 为背景 class name
self.class_name_list = self.load_txt_data("./infos/our_class_names.txt")
# 数据的百分比
self.test_percent = cfg.COMMON.TEST_PERCENT
self.val_percent = cfg.COMMON.VAL_PERCENT
# 各成分数据保存路径
self.train_data_path = cfg.COMMON.TRAIN_DATA_PATH
self.val_data_path = cfg.COMMON.VAL_DATA_PATH
self.test_data_path = cfg.COMMON.TEST_DATA_PATH
self.train_image_name_list = []
self.val_image_name_list = []
# info 和 licenses 基本是固定的,所以可以在这里写死。
# 具体信息你想怎么写就怎么写,感觉,无关痛痒。如果是要做记录,则需要写好点而已。
self.info = {"description": "our data", "url": "",
"version": "1.0", "year": 2020,
"contributor": "our leader",
"date_created": "2020/05/20"}
self.licenses = [{'url': "", 'id': 1, 'name': 'our leader'}]
self.categories = self.category_info()
self.images = []
self.annotations = []
self.ann_id = 0
pass
def load_txt_data(self, file_path):
with open(file_path, encoding="utf-8") as file:
data_info = file.readlines()
data_list = [data.strip() for data in data_info]
return data_list
pass
pass
def load_json_data(self, file_path):
with open(file_path, encoding="utf-8") as file:
return json.load(file)
pass
pass
def divide_data(self):
"""
train, val, test 数据划分
:return:
"""
# 原始图像名字的 list
image_name_list = os.listdir(self.ori_image_file_path)
# 统计有多少张图像
image_number = len(image_name_list)
# 根据百分比得到各成分 数据量
n_test = int(image_number * self.test_percent)
n_val = int(image_number * self.val_percent)
n_train = image_number - n_test - n_val
if os.path.exists(self.train_data_path):
os.remove(self.train_data_path)
pass
if os.path.exists(self.val_data_path):
os.remove(self.val_data_path)
pass
if os.path.exists(self.test_data_path):
os.remove(self.test_data_path)
pass
# 随机划分数据
n_train_val = n_train + n_val
train_val_list = random.sample(image_name_list, n_train_val)
train_list = random.sample(train_val_list, n_train)
train_file = open(self.train_data_path, "w")
val_file = open(self.val_data_path, "w")
test_file = open(self.test_data_path, "w")
for image_name in image_name_list:
if image_name in train_val_list:
if image_name in train_list:
# 将训练的数据名称放到 list 中,不用再次去读写。
self.train_image_name_list.append(image_name)
# 将训练数据保存下来,可以用来参考,后续代码中不用到这个文件
train_file.write(image_name + "\n")
pass
else:
# 将验证的数据名称放到 list 中,不用再次去读写。
self.val_image_name_list.append(image_name)
# 将验证数据保存下来,可以用来参考,后续代码中不用到这个文件
val_file.write(image_name + "\n")
pass
pass
else:
# 测试图像,这个可以在 mask_test.py 文件中用于 test
test_file.write(image_name + "\n")
pass
pass
train_file.close()
val_file.close()
test_file.close()
pass
def category_info(self):
categories = []
class_name_list_len = len(self.class_name_list)
for i in range(1, class_name_list_len):
category_info = {}
class_name = self.class_name_list[i]
super_cate = self.cate_and_super[class_name]
category_info.update({"supercategory": super_cate})
category_info.update({"id": i})
category_info.update({"name": class_name})
categories.append(category_info)
pass
return categories
pass
def json_dump(self, data_info, file_path):
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(data_info, file, ensure_ascii=False, indent=2)
pass
def coco_data_info(self):
data_info = {}
data_info.update({"info": self.info})
data_info.update({"license": self.licenses})
data_info.update({"categories": self.categories})
data_info.update({"images": self.images})
data_info.update({"annotations": self.annotations})
return data_info
pass
def do_data_2_coco(self):
# 划分数据
self.divide_data()
# 将划分的训练数据做成 coco 数据
for train_image_name in self.train_image_name_list:
name_info = train_image_name.split(".")[0]
ann_json_name = name_info + ".json"
ann_json_path = os.path.join(self.label_me_json_file_path, ann_json_name)
json_data = self.load_json_data(ann_json_path)
self.image_info(json_data, name_info, train_image_name)
self.annotation_info(json_data, name_info)
pass
train_data = self.coco_data_info()
train_data_path = os.path.join(self.save_data_path, "train_data.json")
self.json_dump(train_data, train_data_path)
# 初始化,不受上面训练数据影响
self.images = []
self.annotations = []
# 将划分的验证数据做成 coco 数据
for val_image_name in self.val_image_name_list:
name_info = val_image_name.split(".")[0]
ann_json_name = name_info + ".json"
ann_json_path = os.path.join(self.label_me_json_file_path, ann_json_name)
json_data = self.load_json_data(ann_json_path)
self.image_info(json_data, name_info, val_image_name)
self.annotation_info(json_data, name_info)
pass
val_data = self.coco_data_info()
val_data_path = os.path.join(self.save_data_path, "val_data.json")
self.json_dump(val_data, val_data_path)
pass
def image_info(self, json_data, name_info, train_image_name):
image_info = {}
height = json_data["imageHeight"]
width = json_data["imageWidth"]
image_info.update({"height": height})
image_info.update({"width": width})
image_info.update({"id": int(name_info)})
image_info.update({"file_name": train_image_name})
self.images.append(image_info)
pass
def annotation_info(self, json_data, name_info):
data_shape = json_data["shapes"]
for shape_info in data_shape:
annotation = {}
label = shape_info["label"]
points = shape_info["points"]
category_id = self.class_name_list.index(label)
annotation.update({"id": self.ann_id})
annotation.update({"image_id": int(name_info)})
annotation.update({"category_id": category_id})
segmentation = [np.asarray(points).flatten().tolist()]
annotation.update({"segmentation": segmentation})
bbox = self.bounding_box_info(points)
annotation.update({"bbox": bbox})
annotation.update({"iscrowd": 0})
area = annotation['bbox'][-1] * annotation['bbox'][-2]
annotation.update({"area": area})
self.annotations.append(annotation)
self.ann_id += 1
pass
def bounding_box_info(self, points):
"""
# COCO的格式: [x1, y1, w, h] 对应COCO的bbox格式
:param points: "points": [[160.0, 58.985], [151.2, 60.1], ..., [166.1, 56.1]]
:return:
"""
# np.inf 为无穷大
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
pass
if __name__ == "__main__":
# 代码开始时间
start_time = datetime.now()
print("开始时间: {}".format(start_time))
demo = Prepare()
demo.do_data_2_coco()
# 代码结束时间
end_time = datetime.now()
print("结束时间: {}, 训练模型耗时: {}".format(end_time, end_time - start_time))
pass
3. 在运行代码前,需要先设置一下我们的类别文件 our_class_names.txt
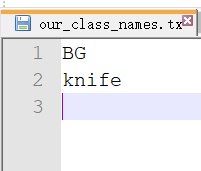
4. 运行代码后,会生成如下文件:

篮框内的 json 数据,就是我们 mask rcnn 使用的 coco 数据集了。test_data.txt 是划分用来做 test 用,而 train_data.txt、val_data.txt 只做参考作用,后续代码不用到。
四. 训练
训练代码 mask_train.py:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# ============================================
# @Time : 2020/05/15 17:31
# @Author : WanDaoYi
# @FileName : mask_train.py
# ============================================
from datetime import datetime
import os
import re
import keras
import imgaug
import logging
import numpy as np
import multiprocessing
import tensorflow as tf
from m_rcnn import common
from utils.bbox_utils import BboxUtil
from m_rcnn.mask_rcnn import MaskRCNN
from utils.image_utils import ImageUtils
from utils.anchor_utils import AnchorUtils
from m_rcnn.coco_dataset import CocoDataset
from config import cfg
class MaskTrain(object):
def __init__(self):
self.anchor_utils = AnchorUtils()
self.bbox_utils = BboxUtil()
self.image_utils = ImageUtils()
# 日志保存路径
self.log_path = self.log_file_path(cfg.TRAIN.LOGS_PATH, cfg.TRAIN.DATA_SOURCE)
# 模型保存路径
self.model_save_path = cfg.TRAIN.SAVE_MODEL_PATH
# 训练数据
self.train_data = CocoDataset(cfg.TRAIN.COCO_TRAIN_ANN_PATH, cfg.TRAIN.COCO_TRAIN_IMAGE_PATH)
# 验证数据
self.val_data = CocoDataset(cfg.TRAIN.COCO_VAL_ANN_PATH, cfg.TRAIN.COCO_VAL_IMAGE_PATH)
# 加载 mask 网络模型
self.mask_model = MaskRCNN(train_flag=True)
# 使用 原作者 1 + 80 类别的数据
# self.mask_model.load_weights(cfg.TEST.COCO_MODEL_PATH, by_name=True)
# 载入在MS COCO上的预训练模型, 跳过不一样的分类数目层
self.mask_model.load_weights(cfg.TEST.COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits",
"mrcnn_bbox_fc",
"mrcnn_bbox",
"mrcnn_mask"])
self.epoch = 0
pass
# 设置 日志文件夹
def log_file_path(self, log_dir, data_source="coco"):
log_start_time = datetime.now()
log_file_name = "{}_{:%Y%m%dT%H%M}".format(data_source.lower(), log_start_time)
log_path = os.path.join(log_dir, log_file_name)
return log_path
pass
def do_mask_train(self):
# image augmentation
augmentation = imgaug.augmenters.Fliplr(0.5)
print("training - stage 1")
# training - stage 1
self.train_details(self.train_data,
self.val_data,
learning_rate=cfg.TRAIN.ROUGH_LEARNING_RATE,
epochs=cfg.TRAIN.FIRST_STAGE_N_EPOCH,
layers=cfg.TRAIN.HEADS_LAYERS,
augmentation=augmentation)
print("training - stage 2")
# training - stage 2
self.train_details(self.train_data, self.val_data,
learning_rate=cfg.TRAIN.ROUGH_LEARNING_RATE,
epochs=cfg.TRAIN.MIDDLE_STAGE_N_EPOCH,
layers=cfg.TRAIN.FOUR_MORE_LAYERS,
augmentation=augmentation)
print("training - stage 3")
# training - stage 3
self.train_details(self.train_data, self.val_data,
learning_rate=cfg.TRAIN.FINE_LEARNING_RATE,
epochs=cfg.TRAIN.LAST_STAGE_N_EPOCH,
layers=cfg.TRAIN.ALL_LAYERS,
augmentation=augmentation)
pass
def train_details(self, train_data, val_data, learning_rate,
epochs, layers, augmentation=None,
custom_callbacks=None, no_augmentation_sources=None):
"""
Train the model.
:param train_data: Training data object
:param val_data: val data object
:param learning_rate: The learning rate to train with
:param epochs: Number of training epochs. Note that previous training epochs
are considered to be done alreay, so this actually determines
the epochs to train in total rather than in this particaular
call.
:param layers: Allows selecting wich layers to train. It can be:
- A regular expression to match layer names to train
- One of these predefined values:
heads: The RPN, classifier and mask heads of the network
all: All the layers
3+: Train Resnet stage 3 and up
4+: Train Resnet stage 4 and up
5+: Train Resnet stage 5 and up
:param augmentation: Optional. An imgaug (https://github.com/aleju/imgaug)
augmentation. For example, passing imgaug.augmenters.Fliplr(0.5)
flips images right/left 50% of the time. You can pass complex
augmentations as well. This augmentation applies 50% of the
time, and when it does it flips images right/left half the time
and adds a Gaussian blur with a random sigma in range 0 to 5.
:param custom_callbacks: Optional. Add custom callbacks to be called
with the keras fit_generator method. Must be list of type keras.callbacks.
:param no_augmentation_sources: Optional. List of sources to exclude for
augmentation. A source is string that identifies a dataset and is
defined in the Dataset class.
:return:
"""
# Pre-defined layer regular expressions
layer_regex = cfg.TRAIN.LAYER_REGEX
if layers in layer_regex:
layers = layer_regex[layers]
pass
self.set_trainable(layers)
if not os.path.exists(self.log_path):
os.makedirs(self.log_path)
pass
# Callbacks
callbacks = [keras.callbacks.TensorBoard(log_dir=self.log_path, histogram_freq=0,
write_graph=True, write_images=False),
keras.callbacks.ModelCheckpoint(self.model_save_path, verbose=0,
save_weights_only=True)]
# Add custom callbacks to the list
if custom_callbacks:
callbacks += custom_callbacks
pass
# Data generators
train_generator = self.data_generator(train_data,
augmentation=augmentation,
batch_size=self.mask_model.batch_size,
no_augmentation_sources=no_augmentation_sources)
val_generator = self.data_generator(val_data, batch_size=self.mask_model.batch_size)
self.compile(learning_rate, cfg.TRAIN.LEARNING_MOMENTUM)
print("learning_rate: {}, checkpoint path: {}".format(learning_rate, self.model_save_path))
# Work-around for Windows: Keras fails on Windows when using
# multiprocessing workers. See discussion here:
# https://github.com/matterport/Mask_RCNN/issues/13#issuecomment-353124009
if os.name is 'nt':
workers = 0
pass
else:
workers = multiprocessing.cpu_count()
pass
self.mask_model.keras_model.fit_generator(generator=train_generator,
initial_epoch=self.epoch,
epochs=epochs,
steps_per_epoch=cfg.TRAIN.STEPS_PER_EPOCH,
callbacks=callbacks,
validation_data=val_generator,
validation_steps=cfg.TRAIN.VALIDATION_STEPS,
max_queue_size=100,
workers=workers,
use_multiprocessing=True,
)
self.epoch = max(self.epoch, epochs)
pass
def data_generator(self, data, augmentation=None, batch_size=1, random_rois=0,
detection_targets=False, no_augmentation_sources=None):
"""
A generator that returns images and corresponding target class ids,
bounding box deltas, and masks.
:param data: The Dataset object to pick data from
:param augmentation: Optional. An imgaug (https://github.com/aleju/imgaug) augmentation.
For example, passing imgaug.augmenters.Fliplr(0.5) flips images
right/left 50% of the time.
:param batch_size: How many images to return in each call
:param random_rois: If > 0 then generate proposals to be used to train the
network classifier and mask heads. Useful if training
the Mask RCNN part without the RPN.
:param detection_targets: If True, generate detection targets (class IDs, bbox
deltas, and masks). Typically for debugging or visualizations because
in trainig detection targets are generated by DetectionTargetLayer.
:param no_augmentation_sources: Optional. List of sources to exclude for
augmentation. A source is string that identifies a dataset and is
defined in the Dataset class.
:return: Returns a Python generator. Upon calling next() on it, the
generator returns two lists, inputs and outputs. The contents
of the lists differs depending on the received arguments:
inputs list:
- images: [batch, H, W, C]
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
- rpn_match: [batch, N] Integer (1=positive anchor, -1=negative, 0=neutral)
- rpn_bbox: [batch, N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
- gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs
- gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]
- gt_masks: [batch, height, width, MAX_GT_INSTANCES]. The height and width
are those of the image unless use_mini_mask is True, in which
case they are defined in MINI_MASK_SHAPE.
outputs list: Usually empty in regular training. But if detection_targets
is True then the outputs list contains target class_ids, bbox deltas,
and masks.
"""
# batch item index
batch_index = 0
image_index = -1
image_ids = np.copy(data.image_ids_list)
error_count = 0
no_augmentation_sources = no_augmentation_sources or []
# Anchors
# [anchor_count, (y1, x1, y2, x2)]
# Generate Anchors
anchors = self.anchor_utils.generate_pyramid_anchors(image_shape=cfg.COMMON.IMAGE_SHAPE)
image_id = ""
mini_mask = cfg.TRAIN.USE_MINI_MASK
max_gt_instances = cfg.TRAIN.MAX_GT_INSTANCES
mean_pixel = np.array(cfg.COMMON.MEAN_PIXEL)
# Keras requires a generator to run indefinitely.
while True:
try:
# Increment index to pick next image. Shuffle if at the start of an epoch.
image_index = (image_index + 1) % len(image_ids)
if image_index == 0:
np.random.shuffle(image_ids)
# Get GT bounding boxes and masks for image.
image_id = image_ids[image_index]
# If the image source is not to be augmented pass None as augmentation
if data.image_info_list[image_id]['source'] in no_augmentation_sources:
image, image_meta, gt_class_ids, gt_boxes, gt_masks = self.bbox_utils.load_image_gt(data,
image_id,
None,
mini_mask)
else:
image, image_meta, gt_class_ids, gt_boxes, gt_masks = self.bbox_utils.load_image_gt(data,
image_id,
augmentation,
mini_mask)
# Skip images that have no instances. This can happen in cases
# where we train on a subset of classes and the image doesn't
# have any of the classes we care about.
if not np.any(gt_class_ids > 0):
continue
pass
# RPN Targets
rpn_match, rpn_bbox = common.build_rpn_targets(anchors, gt_class_ids, gt_boxes)
# 在这里定义 变量,避免下面使用的时候出现未定义
rpn_rois = None
rois = None
mrcnn_class_ids = None
mrcnn_bbox = None
mrcnn_mask = None
# Mask R-CNN Targets
if random_rois:
rpn_rois = self.mask_model.generate_random_rois(image.shape, random_rois, gt_boxes)
if detection_targets:
rois, mrcnn_class_ids, mrcnn_bbox, mrcnn_mask = \
self.mask_model.build_detection_targets(rpn_rois, gt_class_ids, gt_boxes, gt_masks)
pass
pass
# Init batch arrays
if batch_index == 0:
batch_image_meta = np.zeros((batch_size,) + image_meta.shape, dtype=image_meta.dtype)
batch_rpn_match = np.zeros([batch_size, anchors.shape[0], 1], dtype=rpn_match.dtype)
batch_rpn_bbox = np.zeros([batch_size, cfg.TRAIN.ANCHORS_PER_IMAGE, 4], dtype=rpn_bbox.dtype)
batch_images = np.zeros((batch_size,) + image.shape, dtype=np.float32)
batch_gt_class_ids = np.zeros((batch_size, max_gt_instances), dtype=np.int32)
batch_gt_boxes = np.zeros((batch_size, max_gt_instances, 4), dtype=np.int32)
batch_gt_masks = np.zeros((batch_size, gt_masks.shape[0], gt_masks.shape[1],
max_gt_instances), dtype=gt_masks.dtype)
if random_rois:
batch_rpn_rois = np.zeros((batch_size, rpn_rois.shape[0], 4), dtype=rpn_rois.dtype)
if detection_targets:
batch_rois = np.zeros((batch_size,) + rois.shape, dtype=rois.dtype)
batch_mrcnn_class_ids = np.zeros((batch_size,) + mrcnn_class_ids.shape,
dtype=mrcnn_class_ids.dtype)
batch_mrcnn_bbox = np.zeros((batch_size,) + mrcnn_bbox.shape, dtype=mrcnn_bbox.dtype)
batch_mrcnn_mask = np.zeros((batch_size,) + mrcnn_mask.shape, dtype=mrcnn_mask.dtype)
pass
pass
pass
# If more instances than fits in the array, sub-sample from them.
if gt_boxes.shape[0] > max_gt_instances:
ids = np.random.choice(
np.arange(gt_boxes.shape[0]), max_gt_instances, replace=False)
gt_class_ids = gt_class_ids[ids]
gt_boxes = gt_boxes[ids]
gt_masks = gt_masks[:, :, ids]
# Add to batch
batch_image_meta[batch_index] = image_meta
batch_rpn_match[batch_index] = rpn_match[:, np.newaxis]
batch_rpn_bbox[batch_index] = rpn_bbox
batch_images[batch_index] = self.image_utils.mold_image(image.astype(np.float32), mean_pixel)
batch_gt_class_ids[batch_index, :gt_class_ids.shape[0]] = gt_class_ids
batch_gt_boxes[batch_index, :gt_boxes.shape[0]] = gt_boxes
batch_gt_masks[batch_index, :, :, :gt_masks.shape[-1]] = gt_masks
if random_rois:
batch_rpn_rois[batch_index] = rpn_rois
if detection_targets:
batch_rois[batch_index] = rois
batch_mrcnn_class_ids[batch_index] = mrcnn_class_ids
batch_mrcnn_bbox[batch_index] = mrcnn_bbox
batch_mrcnn_mask[batch_index] = mrcnn_mask
pass
pass
batch_index += 1
# Batch full?
if batch_index >= batch_size:
inputs = [batch_images, batch_image_meta, batch_rpn_match, batch_rpn_bbox,
batch_gt_class_ids, batch_gt_boxes, batch_gt_masks]
outputs = []
if random_rois:
inputs.extend([batch_rpn_rois])
if detection_targets:
inputs.extend([batch_rois])
# Keras requires that output and targets have the same number of dimensions
batch_mrcnn_class_ids = np.expand_dims(
batch_mrcnn_class_ids, -1)
outputs.extend(
[batch_mrcnn_class_ids, batch_mrcnn_bbox, batch_mrcnn_mask])
yield inputs, outputs
# start a new batch
batch_index = 0
pass
except (GeneratorExit, KeyboardInterrupt):
raise
except:
# Log it and skip the image
logging.exception("Error processing image {}".format(data.image_info_list[image_id]))
error_count += 1
if error_count > 5:
raise
pass
pass
def set_trainable(self, layer_regex, mask_model=None, indent=0, verbose=1):
"""
Sets model layers as trainable if their names match
the given regular expression.
:param layer_regex:
:param mask_model:
:param indent:
:param verbose:
:return:
"""
# Print message on the first call (but not on recursive calls)
if verbose > 0 and mask_model is None:
print("Selecting layers to train")
pass
mask_model = mask_model or self.mask_model.keras_model
# In multi-GPU training, we wrap the model. Get layers
# of the inner model because they have the weights.
layers = mask_model.inner_model.layers if hasattr(mask_model, "inner_model") else mask_model.layers
for layer in layers:
# Is the layer a model?
if layer.__class__.__name__ == 'Model':
print("In model: ", layer.name)
self.set_trainable(layer_regex, mask_model=layer, indent=indent + 4)
continue
if not layer.weights:
continue
# Is it trainable?
trainable = bool(re.fullmatch(layer_regex, layer.name))
# Update layer. If layer is a container, update inner layer.
if layer.__class__.__name__ == 'TimeDistributed':
layer.layer.trainable = trainable
else:
layer.trainable = trainable
# Print trainable layer names
if trainable and verbose > 0:
print("{}{:20} ({})".format(" " * indent, layer.name, layer.__class__.__name__))
pass
def compile(self, learning_rate, momentum_param):
"""
Gets the model ready for training. Adds losses, regularization, and
metrics. Then calls the Keras compile() function.
:param learning_rate:
:param momentum_param:
:return:
"""
# Optimizer object
optimizer = keras.optimizers.SGD(lr=learning_rate, momentum=momentum_param,
clipnorm=cfg.TRAIN.GRADIENT_CLIP_NORM)
self.mask_model.keras_model._losses = []
self.mask_model.keras_model._per_input_losses = {}
loss_names = ["rpn_class_loss", "rpn_bbox_loss",
"mrcnn_class_loss", "mrcnn_bbox_loss", "mrcnn_mask_loss"]
for name in loss_names:
layer = self.mask_model.keras_model.get_layer(name)
if layer.output in self.mask_model.keras_model.losses:
continue
loss = (tf.reduce_mean(layer.output, keepdims=True) * cfg.COMMON.LOSS_WEIGHTS.get(name, 1.))
self.mask_model.keras_model.add_loss(loss)
pass
# Add L2 Regularization
# Skip gamma and beta weights of batch normalization layers.
reg_losses = [keras.regularizers.l2(cfg.TRAIN.WEIGHT_DECAY)(w) / tf.cast(tf.size(w), tf.float32)
for w in self.mask_model.keras_model.trainable_weights if
'gamma' not in w.name and 'beta' not in w.name]
self.mask_model.keras_model.add_loss(tf.add_n(reg_losses))
# Compile
self.mask_model.keras_model.compile(optimizer=optimizer, loss=[None] * len(self.mask_model.keras_model.outputs))
# Add metrics for losses
for name in loss_names:
if name in self.mask_model.keras_model.metrics_names:
continue
pass
layer = self.mask_model.keras_model.get_layer(name)
self.mask_model.keras_model.metrics_names.append(name)
loss = (tf.reduce_mean(layer.output, keepdims=True) * cfg.COMMON.LOSS_WEIGHTS.get(name, 1.))
self.mask_model.keras_model.metrics_tensors.append(loss)
pass
if __name__ == "__main__":
# 代码开始时间
start_time = datetime.now()
print("开始时间: {}".format(start_time))
demo = MaskTrain()
demo.do_mask_train()
print("hello world! ")
# 代码结束时间
end_time = datetime.now()
print("结束时间: {}, 训练模型耗时: {}".format(end_time, end_time - start_time))
pass
五. 测试
1. 先看看测试效果图

这张图像,看不太清晰 类别名 和 预测概率值,有点遗憾。但是,我可以很负责的告诉你,类别名就是 knife,概率在 90% 以上。因为,我跑过很多数据,随便 10+ 张图像,随便训练一个 epoch,3-5 分类 都可以达到 90% 以上的命中。这,也就是我前面为什么说 mask_rcnn_coco.h5 很强大的原因。mask_rcnn_coco.h5 各层提取特征能力都非常的强大,你值得拥有。
测试代码 mask_test.py
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# ============================================
# @Time : 2020/05/18 14:42
# @Author : WanDaoYi
# @FileName : mask_test.py
# ============================================
from datetime import datetime
import os
import colorsys
import skimage.io
import numpy as np
from matplotlib import patches
import matplotlib.pyplot as plt
from m_rcnn.mask_rcnn import MaskRCNN
from matplotlib.patches import Polygon
from skimage.measure import find_contours
from config import cfg
class MaskTest(object):
def __init__(self):
# 获取 类别 list
self.class_names_path = cfg.COMMON.OUR_CLASS_NAMES_PATH
self.class_names_list = self.read_class_name()
# 测试图像的输入 和 输出 路径
self.test_image_file_path = cfg.TEST.TEST_IMAGE_FILE_PATH
self.output_image_path = cfg.TEST.OUTPUT_IMAGE_PATH
# 加载网络模型
self.mask_model = MaskRCNN(train_flag=False)
# 加载权重模型
self.mask_model.load_weights(cfg.TEST.COCO_MODEL_PATH, by_name=True)
pass
def read_class_name(self):
with open(self.class_names_path, "r") as file:
class_names_info = file.readlines()
class_names_list = [class_names.strip() for class_names in class_names_info]
return class_names_list
pass
def do_test(self, show_image_flag=False):
"""
batch predict
:param show_image_flag: show images or not
:return:
"""
test_image_name_list = os.listdir(self.test_image_file_path)
for test_image_name in test_image_name_list:
test_image_path = os.path.join(self.test_image_file_path, test_image_name)
# 读取图像
image_info = skimage.io.imread(test_image_path)
# Run detection
results_info_list = self.mask_model.detect([image_info])
# print("results: {}".format(results_info_list))
# Visualize results
result_info = results_info_list[0]
self.deal_instances(image_info, self.class_names_list, result_info)
height, width = image_info.shape[:2]
fig = plt.gcf()
# 输出原始图像 width * height的像素
fig.set_size_inches(width / 100.0, height / 100.0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.subplots_adjust(top=1, bottom=0, left=0, right=1, hspace=0, wspace=0)
plt.margins(0, 0)
# save images
output_image_path = os.path.join(self.output_image_path, test_image_name)
plt.savefig(output_image_path)
if show_image_flag:
plt.show()
# clear a axis
plt.cla()
# will close all open figures
plt.close("all")
pass
pass
# 获取实例随机颜色
def random_colors(self, n, bright=True):
"""
Generate random colors. To get visually distinct colors, generate them in HSV space then
convert to RGB.
:param n: Number of instances
:param bright: image bright
:return:
"""
brightness = 1.0 if bright else 0.7
hsv = [(i / n, 1, brightness) for i in range(n)]
colors = list(map(lambda c: colorsys.hsv_to_rgb(*c), hsv))
np.random.shuffle(colors)
return colors
pass
# 给图像的实例添加 mask
def apply_mask(self, image, mask, color, alpha=0.5):
"""
Apply the given mask to the image.
:param image:
:param mask:
:param color:
:param alpha:
:return:
"""
for c in range(3):
image[:, :, c] = np.where(mask == 1,
image[:, :, c] * (1 - alpha) + alpha * color[c] * 255,
image[:, :, c])
return image
pass
def deal_instances(self, image_info, class_names_list, result_info,
fig_size=(7, 7), ax=None, show_mask=True, show_bbox=True,
colors=None, captions=None):
"""
实例处理
:param image_info: original image info
:param class_names_list: list of class names of the dataset
:param result_info:
boxes: [num_instance, (y1, x1, y2, x2, class_id)] in image coordinates.
masks: [height, width, num_instances]
class_ids: [num_instances]
scores: (optional) confidence scores for each box
:param fig_size: (optional) the size of the image
:param ax:
:param show_mask: To show masks or not
:param show_bbox: To show bounding boxes or not
:param colors: (optional) An array or colors to use with each object
:param captions: (optional) A list of strings to use as captions for each object
:return:
"""
# r = results[0]
# visualize.display_instances(image_info, r['rois'], r['masks'], r['class_ids'],
# self.class_names_list, r['scores'])
boxes = result_info["rois"]
masks = result_info["masks"]
class_ids = result_info["class_ids"]
scores = result_info["scores"]
# Number of instances
n = boxes.shape[0]
if not n:
print("\n*** No instances to display *** \n")
else:
assert boxes.shape[0] == masks.shape[-1] == class_ids.shape[0]
pass
# Generate random colors
colors = colors or self.random_colors(n)
print("colors_len: {}".format(len(colors)))
masked_image = image_info.astype(np.uint32).copy()
if not ax:
# fig_size 用来设置画布大小
_, ax = plt.subplots(1, figsize=fig_size)
pass
# 不显示坐标
ax.axis('off')
for i in range(n):
color = colors[i]
# Bounding box
if not np.any(boxes[i]):
# Skip this instance. Has no bbox. Likely lost in image cropping.
continue
pass
y1, x1, y2, x2 = boxes[i]
if show_bbox:
p = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2,
alpha=0.7, linestyle="dashed",
edgecolor=color, facecolor='none')
ax.add_patch(p)
pass
# Label
if not captions:
class_id = class_ids[i]
score = scores[i] if scores is not None else None
label = class_names_list[class_id]
caption = "{} {:.3f}".format(label, score) if score else label
pass
else:
caption = captions[i]
pass
ax.text(x1, y1 + 8, caption, color='w', size=11, backgroundcolor="none")
# Mask
mask = masks[:, :, i]
if show_mask:
masked_image = self.apply_mask(masked_image, mask, color)
pass
# Mask Polygon
# Pad to ensure proper polygons for masks that touch image edges.
padded_mask = np.zeros((mask.shape[0] + 2, mask.shape[1] + 2), dtype=np.uint8)
padded_mask[1:-1, 1:-1] = mask
contours = find_contours(padded_mask, 0.5)
for flip in contours:
# Subtract the padding and flip (y, x) to (x, y)
flip = np.fliplr(flip) - 1
p = Polygon(flip, facecolor="none", edgecolor=color)
ax.add_patch(p)
pass
masked_image_uint8 = masked_image.astype(np.uint8)
# 将 masked_image_uint8 放入到 plt 中
ax.imshow(masked_image_uint8)
pass
if __name__ == "__main__":
# 代码开始时间
start_time = datetime.now()
print("开始时间: {}".format(start_time))
demo = MaskTest()
# print(demo.class_names_list)
demo.do_test()
# 代码结束时间
end_time = datetime.now()
print("结束时间: {}, 训练模型耗时: {}".format(end_time, end_time - start_time))
由于篇幅太长了,相关网络,数据,工具 代码 在下一小节再进行描述。

上一章:深度篇——实例分割(一) mask rcnn 论文 翻译 和 总结
下一章: 深度篇——实例分割(三) 细说 mask rcnn 实例分割代码 训练自己数据 之 相关网络,数据处理,工具等