2017 CVPR
Mask R-CNN
Mask RCNN, PyTorch
Instance Segmentation
Mask R-CNN
Introduction
Mask RCNN = Faster RCNN + ResNet-FPN + Mask
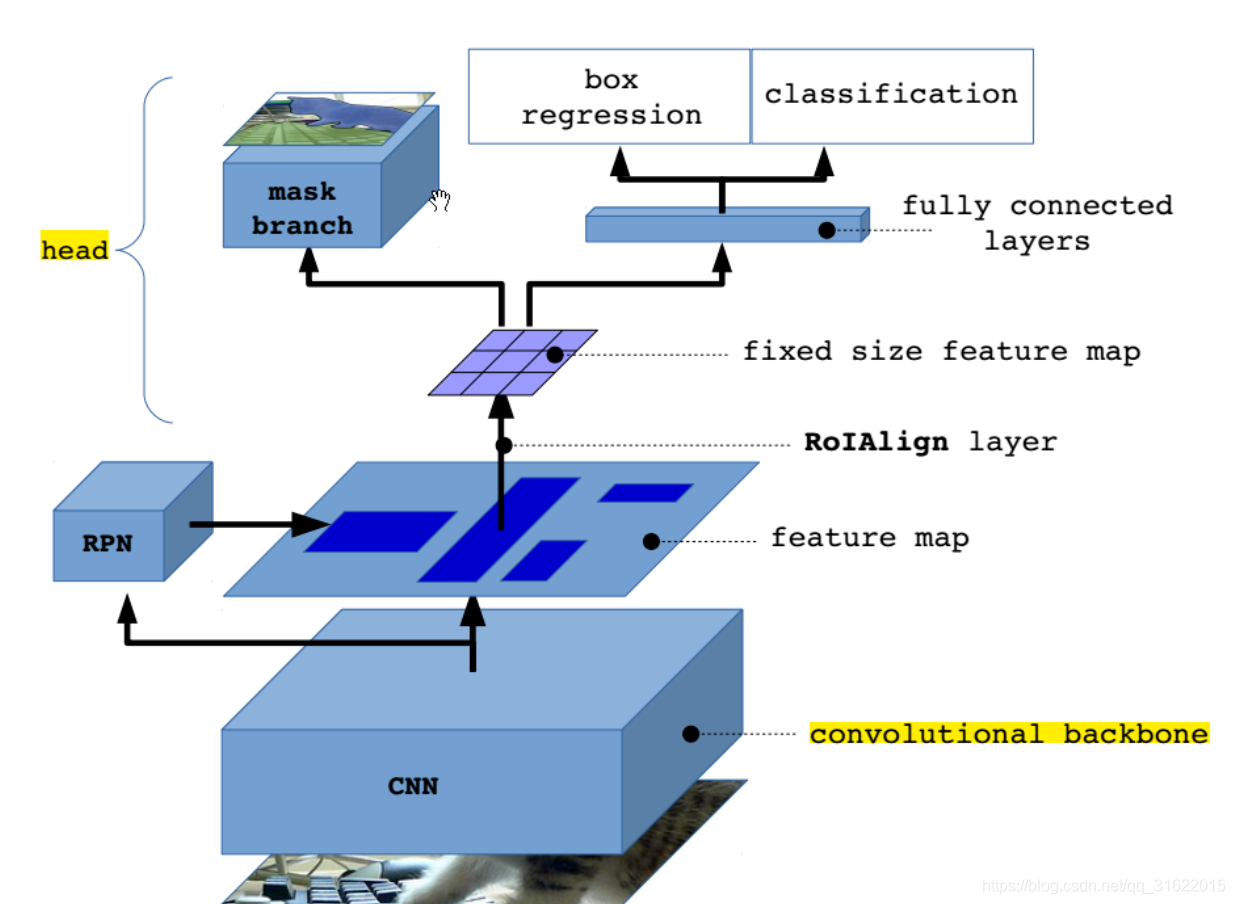
Motivation
-
强化的基础网络
通过 ResNeXt-101+FPN 用作特征提取网络,达到 state-of-the-art 的效果。 -
ROI Pooling → ROI Align
解决特征图与原始图像上的RoI不对准问题- ROI Pooling 是一种针对每一个RoI的提取一个小尺度特征图(e.g. 7x7)的标准操作
- ROI Align 使用双线性插值(bilinear interpolation)在每个RoI块中4个采样位置上计算输入特征的精确值,并将结果聚合(使用max或者average)。
-
分割、分类、定位同时进行
检测和分割是并行出结果的,而不像以前是分割完了之后再做分类- FCNs是对每个像素进行多类别分类,它同时进行分类和分割
- Mask RCNN 对每个类别独立地预测一个二值掩模,没有引入类间竞争,每个二值掩模的类别依靠网络RoI分类分支给出的分类预测结果
-
Loss Function
- mask loss
由原来的 FCIS 的 基于单像素softmax的多项式交叉熵变为了基于单像素sigmod二值交叉熵。
softmax会产生 FCIS 的 ROI inside map 与 ROI outside map的竞争。但文章作者确实写到了类间的竞争, 二值交叉熵会使得每一类的 mask 不相互竞争,而不是和其他类别的 mask 比较 。
- mask loss
Network
faster rcnn
Mask rcnn
“head” 作用是将RoI Align的输出维度扩大,这样在预测Mask时会更加精确。
在Mask Branch的训练环节,作者没有采用FCN式的SoftmaxLoss,反而是输出了K个Mask预测图(为每一个类都输出一张),并采用average binary cross-entropy loss训练,
-
two-state
extract feature 、RPN
对RPN找到的每个RoI进行 分类、定位、找到binary mask(对于 Faster RCNN 的每个 Proposal Box 使用 FCN 进行语义分割)
注意:这里和其他分割网络(先 mask 然后分类 )是不同的 -
Loss
L = L c l s + L b o x + L m a s k L=Lcls+Lbox+Lmask L=Lcls+Lbox+Lmask -
Mask Representation
没有采用全连接层并且使用了RoIAlign,可以实现输出与输入的像素一一对应
backbone
resnet-50,resnet-101,resnext-50,resnext-101;FPN
Mask
Faster RCNN使用resnet50时,从CONV4导出特征供RPN使用,这种叫做ResNet-50-C4
对于新增加的mask支路,其对于每个ROI的输出维度是 K ∗ m ∗ m K*m*m K∗m∗m,其中 m ∗ m m*m m∗m表示mask的大小,K表示K个类别,因此这里每一个ROI一共生成 K K K个binary mask,这就是文章中提到的class-specific mask概念。
在得到预测mask后,对mask的每个像素点值求sigmoid函数值(即所谓的per-pixel sigmoid),得到的结果作为Lmask(交叉熵损失函数)的输入之一。
- sigmoid:A logistic function or logistic curve is a common “S” shape (sigmoid curve).
二分类损失 - softmax:softmax is a generalization of logistic function that “squashes”(maps) a K-dimensional vector z of arbitrary real values to a K-dimensional vector σ(z) of real values in the range (0, 1) that add up to 1.
多分类损失
送进mask分支的ROI其实是只有正样本的ROI才被送进去。只有正样本ROI才会用于计算Lmask,正样本的定义和目标检测一样,都是IOU大于0.5定义为正样本。
问题
怎么做到区别 实例而不是类别??
对于每一个ROI,如果检测得到ROI属于哪一个分类,就只使用哪一个分支的相对熵误差作为误差值进行计算。
举例说明:分类有3类(猫,狗,人),检测得到当前ROI属于“人”这一类,那么所使用的Lmask为“人”这一分支的mask。
这样的定义使得我们的网络不需要去区分每一个像素属于哪一类,只需要去区别在这个类当中的不同小类。
我们定义的Lmask允许网络为每一类生成一个mask,而不用和其它类进行竞争;我们依赖于分类分支所预测的类别标签来选择输出的mask。
- FCN
-
Mask-RCNN
Mask-RCNN不是一次性对所有的通道channel上的像素求多分类损失,而是只在每一个ROI所对应的类别上对每一个像素求一个sigmoid二分类
第一个ROI我们只在对应的K=3的类别中,即在channel为3的通道上的那个mask上面对每一个像素求二分类
第二个ROI我们只在对应的K=8的类别中,即在channel为8的通道上的那个mask上面对每一个像素求二分类
- 关键问题:怎么知道每一个ROI到底是那个类别呢?
- 借助分类网络
分类网络告诉分割网络这个对应的 ROI 是属于哪一个类别 K 。 - 好处:
定义的 Lmask 允许网络为每一类生成一个mask,只用在自己的类别(即channel)上计算损失,而不用和其它类进行竞争。
对每个固定的类别的那张特征图的每一个像素计算损失之后,然后再求所有像素的平均,这也是文章中将Lmask称为average binary cross-entropy loss的原因。
- 借助分类网络
ROI Align 原理?
- 为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,即我们不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。
- 如何处理这些浮点数?
解决思路是使用“双线性插值”算法。双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。(如下图 四根红色指针)
如图
-
蓝色的虚线框表示卷积后获得的feature map
-
黑色实线框表示ROI feature
-
假设最后需要输出的大小是2x2
-
利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值(通过四周的四个真实存在的像素值来共同决定,例如图中红色指针),最后得到相应的输出。
-
这些蓝点是 2x2Cell 中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。
-
然后在每一个橘红色的区域里面进行 max pooling 或者 average pooling 操作,获得最终 2x2 的输出结果。
-
整个过程中没有用到量化操作,没有引入误差,即原图中的像素和 feature map 中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
Pytorch
改进
基于 Mask RCNN 的改进:
Reference
https://blog.csdn.net/jiongnima/article/details/79094159
https://zhuanlan.zhihu.com/p/37998710
https://blog.csdn.net/linolzhang/article/details/71774168
https://blog.csdn.net/u014380165/article/details/81878644
https://blog.csdn.net/xiamentingtao/article/details/78598511
https://blog.csdn.net/wangdongwei0/article/details/83110305
https://blog.csdn.net/qq_27825451/article/details/89677068