环境:
tensorflow-gpu-1.4.1、keras-2.0.9、py35、cuda-8.0、opencv、PIL、labelme
DeepFashion是香港中文大学整理出来检测服装时尚元素的数据集,这里使用它做Mask-RCNN实例分割并不适合,因为数据中不包含Mask,仅有bbox坐标。但是用来做分类,MRCNN效果还是很棒的,本实验仅起到一个实验性学习作用。
DeepFasion github地址:https://github.com/liuziwei7/fashion-landmarks
目前仅使用Category and Attribute Prediction Benchmark 数据集:

Mask R-CNN简介:
用FPN进行目标检测,并通过添加额外分支进行语义分割(额外分割分支和原检测分支不共享参数),即MaskR-CNN有三个输出分支(分类、坐标回归、和分割)
(1).改进了RoIpooling,通过双线性差值使候选区域和卷积特征的对齐不因量化而损失信息。
(2).在分割时,MaskR-CNN将判断类别和输出模板(mask)这两个任务解耦合,用sigmoid配合对率(logistic)损失函数对每个类别的模板单独处理,比经典分割方法用softmax让所有类别一起竞争效果更好
1、整张图片送入CNN,进行特征提取
2、在最后一层卷积featuremap上,通过RPN生成ROI,每张图片大约300个建议窗口
3、通过RoIAlign层使得每个建议窗口生成固定大小的feature map(ROIAlign是生成mask预测的关键)
4、得到三个输出向量,第一个是softmax分类,第二个是每一类的bounding box回归,第三个是每一个ROI的二进制掩码Mask(FCN生成)
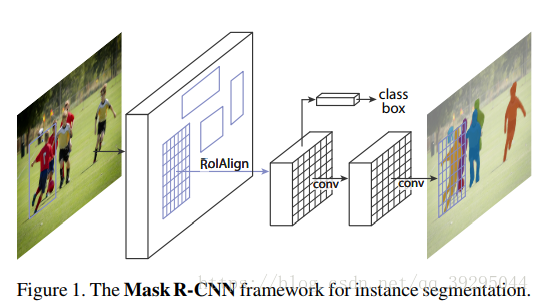
Mask Representation:
mask 编码了 输入的 object 的空间布局(spatial layout)
针对每个 RoI,采用 FCN 预测一个 m×m 的 mask.
mask 分支的每一网络层均可保持 m×m 的 object 空间布局,而不用压扁拉伸成向量形式来表示,导致空间信息损失.
pixel-to-pixel 操作需要保证 RoI 特征图的对齐性,以保留 per-pixel 空间映射关系(映射到ROI原图). 即 RoIAlign.
ROIAlign:
原来RoIPooling是映射原图RoI 到特征图 RoI,其间基于 stride 间隔来取整,导致将特征图RoI映射回原图RoI时,出现 stride 造成的误差(max pool 后特征图的 RoI 与原RoI 间的空间不对齐更加明显). 会影响像素级的 mask 分割. 因此需要像素级的对齐ROIAlign
RoIPool 用于从每个 RoI 中提取小的特征图的操作,RoIPool 选择的特征图区域,会与原图中的区域有轻微出入,分析ROIpool的步骤:把浮点数ROI量化到离散粒度的特征图,细分为空间直方图的bins,最后每个bin所涵盖的特征值被聚合(常用max pooling聚合)
也就是说,对浮点数 RoI 量化,再提取分块的直方图,最后利用 max pooling 组合,导致 RoI 和提取的特征间的 misalignments。对于平移不变性的分类任务影响不大,但对于要求精确的像素级 masks 预测具有较大的负影响.
RoIAlign 能够去除 RoIPool 引入的 misalignments,准确地对齐输入的提取特征. 即: 避免 RoI 边界或 bins 进行量化(如,采用 来替代 [四舍五入处理] );采用 bilinear interpolation 根据每个 RoI bin 的四个采样点来计算输入特征的精确值,并采用 max 或 average 来组合结果。如,假设点 ,取其周围最近的四个采样点,在 Y 方向进行两次插值,再在 X 方向 进行两次插值,以得到新的插值. 这种处理方式不会影响 RoI 的空间布局.
假设有一个 128x128 的图像,25x25 的特征图,想要找出与原始图像左上角 15x15 位置对应的特征区域,怎么在特征图上选取像素?
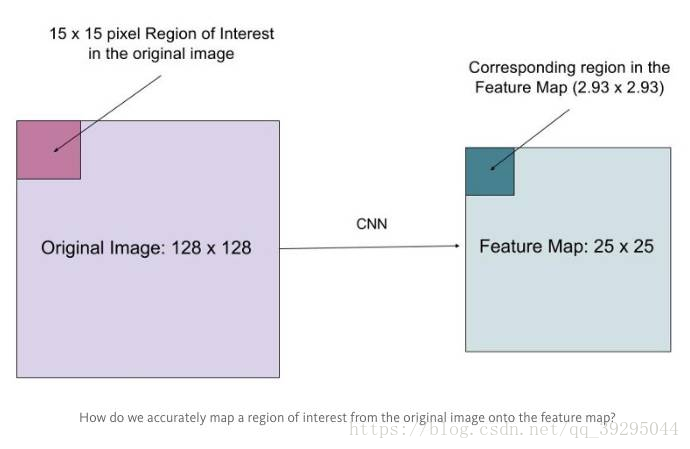
原始图像的每一个像素与特征图上的 25/128 个像素对应. 为了在原始图像选取 15 个像素,在特征图上我们需要选择 15 * 25/128 ~= 2.93 个像素.
对于这种情形,RoIPool 会舍去零头选择两个像素,导致排列问题. 但在 RoIAlign,这种去掉小数点之后数字的方式被避免,而是使用双线性插值(bilinear interpolation)准确获得 2.93 像素位置的信息,避免了排列错误.

网络结构
Backbone 卷积网络 —— 用于整张图片的特征提取 ,ResNeXt-101,ResNet-50,FPN(Feature Pyramid Network).
- Backbone1:Faster R-CNN 基于 ResNets,是从第 4 stage 的最后一个卷积层提取特征,这里记为 C4,即 ResNet-50-C4,ResNeXt-101-C4.(常用的)
- Backbone2:ResNet-FPN(性能 better,对基础网络的改进,另一个改进方向)
Head 网络 —— 用于对每个 RoI 分别进行 bounding-box 识别(分类和回归) 和 Mask 预测.

服装数据集所有文件概览:
byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark$ ll Anno/ total 953368 drwxrwxr-x 2 byz byz 4096 Mar 6 16:36 ./ drwxrwxr-x 5 byz byz 4096 Mar 6 16:37 ../ -rw-rw-r-- 1 byz byz 31541 Mar 6 16:21 list_attr_cloth.txt -rw-rw-r-- 1 byz byz 888197576 Mar 6 16:35 list_attr_img.txt -rw-rw-r-- 1 byz byz 25162370 Mar 6 16:22 list_bbox.txt -rw-rw-r-- 1 byz byz 882 Mar 6 16:21 list_category_cloth.txt -rw-rw-r-- 1 byz byz 21355261 Mar 6 16:22 list_category_img.txt -rw-rw-r-- 1 byz byz 41475819 Mar 6 16:36 list_landmarks.txt byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark/Anno$ cat list_attr_cloth.txt 1000 attribute_name attribute_type #属性名字 a-line 3 abstract 1 abstract chevron 1 abstract chevron print 1 #抽象雪佛龙印花 abstract diamond 1 abstract floral 1 abstract floral print 1 acid 2 acid wash 2 americana 5 angeles 5 animal 1 animal print 1 byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark/Anno$ head list_attr_img.txt 289222 image_name attribute_labels #图片属性标签,有的就标记1,没有的属性标记-1 img/Sheer_Pleated-Front_Blouse/img_00000001.jpg -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 img/Sheer_Pleated-Front_Blouse/img_00000002.jpg -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 img/Sheer_Pleated-Front_Blouse/img_00000003.jpg -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark/Anno$ head list_bbox.txt 289222 image_name x_1 y_1 x_2 y_2 #目标在图片中的坐标 bouding box img/Sheer_Pleated-Front_Blouse/img_00000001.jpg 072 079 232 273 img/Sheer_Pleated-Front_Blouse/img_00000002.jpg 067 059 155 161 img/Sheer_Pleated-Front_Blouse/img_00000003.jpg 065 065 156 200 img/Sheer_Pleated-Front_Blouse/img_00000004.jpg 051 062 167 182 img/Sheer_Pleated-Front_Blouse/img_00000005.jpg 046 088 166 262 img/Sheer_Pleated-Front_Blouse/img_00000006.jpg 047 067 211 241 img/Sheer_Pleated-Front_Blouse/img_00000007.jpg 018 073 200 241 img/Sheer_Pleated-Front_Blouse/img_00000008.jpg 075 074 197 246 byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark/Anno$ head list_category_cloth.txt 50 category_name category_type #衣服类别(50大类) Anorak 1 Blazer 1 Blouse 1 Bomber 1 Button-Down 1 Cardigan 1 Flannel 1 Halter 1 byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark/Anno$ head list_category_img.txt 289222 image_name category_label # 图片类别/图片名字 img/Sheer_Pleated-Front_Blouse/img_00000001.jpg 3 img/Sheer_Pleated-Front_Blouse/img_00000002.jpg 3 img/Sheer_Pleated-Front_Blouse/img_00000003.jpg 3 img/Sheer_Pleated-Front_Blouse/img_00000004.jpg 3 img/Paisley_Maxi_Cami_Dress/img_00000025.jpg 41 img/Paisley_Maxi_Cami_Dress/img_00000026.jpg 41 img/Paisley_Print_Babydoll_Dress/img_00000028.jpg 41 img/Paisley_Print_Babydoll_Dress/img_00000029.jpg 41 img/Paisley_Print_Babydoll_Dress/img_00000030.jpg 41 img/Paisley_Print_Babydoll_Dress/img_00000031.jpg 41 byz@ubuntu:~/app/coco/Category and Attribute Prediction Benchmark/Anno$ head list_landmarks.txt 289222 image_name clothes_type variation(变异)_type img/Sheer_Pleated-Front_Blouse/img_00000001.jpg 1 landmark_visibility_1 landmark_location_x_1 landmark_location_y_1 # 01:坐标物是否可见, xy:宽高 0 146 102 landmark_visibility_2 landmark_location_x_2 landmark_location_y_2 0 173 095 landmark_visibility_3 landmark_location_x_3 landmark_location_y_3 0 094 242 landmark_visibility_4 landmark_location_x_4 landmark_location_y_4 # 0 205 255 0 136 229 0 177 232 landmark_visibility_5 landmark_location_x_5 landmark_location_y_5 landmark_visibility_6 landmark_location_x_6 landmark_location_y_6 landmark_visibility_7 landmark_location_x_7 landmark_location_y_7 landmark_visibility_8 landmark_location_x_8 landmark_location_y_8 img/Sheer_Pleated-Front_Blouse/img_00000002.jpg 1 0 107 067 0 122 067 0 079 078 0 140 091 0 106 150 0 134 152 img/Sheer_Pleated-Front_Blouse/img_00000003.jpg 1 0 101 079 0 116 076 0 078 081 0 141 084 0 087 188 0 118 185 img/Sheer_Pleated-Front_Blouse/img_00000004.jpg 1 0 096 074 0 113 072 0 067 171 0 148 171 0 100 148 0 120 148 img/Sheer_Pleated-Front_Blouse/img_00000005.jpg 1 1 102 106 0 116 102 0 063 194 1 146 216 0 105 245 0 137 246 img/Sheer_Pleated-Front_Blouse/img_00000006.jpg 1 0 118 084 0 142 081 0 070 205 0 184 203 0 111 225 0 143 223 img/Sheer_Pleated-Front_Blouse/img_00000007.jpg 1 0 086 088 0 097 087 0 044 210 0 175 184 0 079 226 0 106 225 img/Sheer_Pleated-Front_Blouse/img_00000008.jpg 1 0 144 089 0 161 088 0 092 227 0 177 230 0 125 212 0 161 212
将数据整理成Mask-RCNN输入格式:
(可以修改Mask源码将输入格式简化,这里选择修改数据)
''' construct_to_json.py ''' from PIL import Image import numpy as np import time import json import shutil import os import base64 # DeepFashion数据集路径 path = r'/home/byz/dataset/DeepFashion/ClothesData/' data_path = path + r'Img/' #"/home/byz/dataset/DeepFashion/tmp/Img/" bbox_path = path + r'Anno/list_bbox.txt' img_category_path = path + r'Anno/list_category_img.txt' cloth_category_path = path + r'Anno/list_category_cloth.txt' cloth_category = {} img_category = {} img_bbox = {} newpath = r'/home/byz/dataset/DeepFashion/CAPB/' # 新的数据路径(jpg\json) #"/home/byz/dataset/DeepFashion/tmp/ImgOuput/" img_category_label_set = set() """ ----------------------------------------------------------- """ #read list_bbox,save as a dict def get_cloth_category(): '''得到{服装类别编号:服装类别名称}''' try: img_category_file = open(cloth_category_path, 'r') lines = img_category_file.readlines() index = 1 for l in lines[2:]: s = l.split() category = s[0] cloth_category[int(index)] = category #s[1] index += 1 except Exception: print('img_category_path error!!') """ ----------------------------------------------------------- """ def get_img_category(): ''' 得到{图片路径:服装类别名称} ''' get_cloth_category() try: img_category_dir = open(img_category_path, 'r') lines = img_category_dir.readlines() #print(len(lines)) for l in lines[2:]: s = l.split() img_path = data_path + s[0] img_category[img_path] = cloth_category.get(int(s[1])) except Exception: print('img_category_path error!!') # sorted(list(set(img_category.values()))) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 # , 32, 33, 34, 35, 36, 37, 39, 40, 41, 42, 43, 44, 46, 47, 48] """ ----------------------------------------------------------- """ def read_bbox(): try: bbox_file = open(bbox_path, 'r') except Exception: print("list_bbox.txt IOError!") bbox_data = bbox_file.readlines() for d, index in zip(bbox_data[2:],range(bbox_data.__len__()-2)): s = d.split() p = data_path + s[0] # if p=="/home/byz/dataset/DeepFashion/ClothesData/Img/img/Lace_Print_Skirt/img_00000038.jpg": # print(p) # print(s) # ['img/Lace_Print_Skirt/img_00000038.jpg', '001', '046', '194', '261'] <---说明一张图片不管有几件衣服都只有一个BBox bbox_loca = [] for a in s[1:]: bbox_loca.append(float(a)) bbox_4point = [[bbox_loca[0],bbox_loca[1]], [bbox_loca[2],bbox_loca[1]], [bbox_loca[2],bbox_loca[3]], [bbox_loca[0],bbox_loca[3]]] #x_1 y_1 x_2 y_2 img_bbox[p] = bbox_4point #bbox_loca bbox_file.close() print('list_bbox.txt ready!') # 返回{path:bbox} read_bbox() '/home/byz/app/coco/Category and Attribute Prediction Benchmark/Img/img/Boxy_Rugby_Striped_Sweater/img_00000019.jpg' """ ----------------------------------------------------------- """ ''' 获取imageData ''' def mk_imageData(imagePath): # imagePath = "/home/byz/Mask/test/rgb_114372.jpg" try: with open(imagePath, 'rb') as f: imageData = f.read() imageData = base64.b64encode(imageData).decode('utf-8') except Exception as e: print(e + "\n在" + imagePath + "获取imageData失败!") return imageData ''' 对所有图片都resize到(512,512)''' def orignal_grapg_resize(jpg_path, ouput_path): img = Image.open(jpg_path) # 打开图片img = Image.open(dir)#打开图片 img = np.array(img) img = Image.fromarray(img) resize_mage = img.resize((512, 512),Image.ANTIALIAS) resize_mage.save(ouput_path) print("开始保存数据:") def save_data(): # 执行读取img_category_bbox程序 get_img_category() read_bbox() # length = 1 for jpg_path, bbox in img_bbox.items(): dstpath = str(length) + ".jpg" # try: ouput_path = newpath + "rgb_" + dstpath # 输出路径 # orignal_grapg_resize(jpg_path, ouput_path) # resize后复制全部文件到一个目录下 # #shutil.copyfile(jpg_path, ouput_path) # imageData = mk_imageData(jpg_path) # 得到imageData , 注:不可用resize图ouput_path # # 制作json img_category_label = img_category.get(jpg_path) json_data = {'shapes': [{'line_color': None, 'points': bbox, 'fill_color': None, 'label': img_category_label}], 'imageData': imageData, 'imagePath': dstpath, 'fillColor': [255, 0, 0, 128], 'lineColor': [0, 255, 0, 128]} with open(newpath + "rgb_" + str(length) + ".json", 'w', encoding='utf-8') as json_file: json.dump(json_data, json_file, ensure_ascii=False) length += 1 img_category_label_set.add(img_category_label) # # # 制作类别信息(json/rgb_2_json/info.yaml) # os.mkdir(newpath + "json/rgb_" + str(length) + "_json/") # label_names = "label_names:\n- _background_\n- %s" % img_category_label # with open(newpath + "json/rgb_" + str(length) + "_json/" + "info.yaml", 'w', encoding='utf-8') as yaml_file: # yaml_file.write(label_names) # yaml_file.close() except Exception as e: print(e) save_data() print("数据执行完毕! \n\nimg_category_label_set:") print(list(img_category_label_set)) # img_category_label_set: # ['Skirt', 'Trunks', 'Tank', 'Jersey', 'Romper', 'Dress', 'Gauchos', 'Shorts', 'Cutoffs', 'Blazer', 'Hoodie', 'Sweater', 'Peacoat', 'Capris', 'Halter', 'Henley', 'Turtleneck', 'Jeans', 'Poncho', 'Button-Down', 'Joggers', 'Sweatpants', 'Kimono', 'Jeggings', 'Sarong', 'Kaftan', 'Tee', 'Blouse', 'Jacket', 'Cardigan', 'Onesie', 'Caftan', 'Sweatshorts', 'Jumpsuit', 'Top', 'Chinos', 'Jodhpurs', 'Coat', 'Coverup', 'Parka', 'Culottes', 'Robe', 'Anorak', 'Flannel', 'Leggings', 'Bomber'] # 利用rsync删除rm -rf 不能一次性删除的大量文件 # 解决: # ls | grep .json | xargs -n 10 rm -fr # ls | grep .jpg | xargs -n 10 rm -fr """ ----------------------------------------------------------- """ # 转化脚本(old) # ./labelme2voc.py labels.txt data_annotated data_dataset_voc # python labelme2voc.py labels.txt ./ data_dataset_voc
''' json_to_dataset_.py 使用: (py35) byz@ubuntu:~/Mask/Mask_RCNN/net_img$ python json_to_dataset.py rgb_5.json /home/byz/Mask/Mask_RCNN/test (jpg和json在一个目录) 执行脚本: python json_to_dataset.py -o /home/byz/Mask/test/ouput /home/byz/dataset/DeepFashion/CAPB/rgb_98.json 注意: 不管图片有没有resize,该脚本出来的文件都是原图尺寸, 需要进一步resize(在16_to_8.py中)-已整合进来 ''' import argparse import json import os import re import os.path as osp import warnings import numpy as np from PIL import Image import PIL.Image import yaml from labelme import utils def excutor(json_file, json_name, ouput_dir = "/home/byz/Mask/Mask_RCNN/net_img"): '''指定输出目录''' out_mask_dir = ouput_dir + "/mask" out_json_dir = ouput_dir + "/json/rgb_" + json_name + "_json" if not osp.exists(out_mask_dir): os.mkdir(out_mask_dir) if not osp.exists(ouput_dir + "/json/"): os.mkdir(ouput_dir + "/json/") if not osp.exists(out_json_dir): print(out_json_dir) os.mkdir(out_json_dir) '''load json''' data = json.load(open(json_file)) img = utils.img_b64_to_arr(data['imageData']) label_name_to_value = {'_background_': 0} for shape in data['shapes']: label_name = shape['label'] if label_name in label_name_to_value: label_value = label_name_to_value[label_name] else: label_value = len(label_name_to_value) label_name_to_value[label_name] = label_value # label_values must be dense label_values, label_names = [], [] for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]): label_values.append(lv) label_names.append(ln) assert label_values == list(range(len(label_values))) lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value) # captions = ['{}: {}'.format(lv, ln) # for ln, lv in label_name_to_value.items()] # lbl_viz = utils.draw_label(lbl, img, captions) # # PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png')) # PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png')) # PIL.Image.fromarray(lbl_viz).save(osp.join(out_mask_dir, 'label_viz.png')) # # PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png')) PIL.Image.fromarray(np.uint8(lbl)).resize((512, 512), Image.ANTIALIAS).save( osp.join(out_mask_dir, json_name + '.png')) # 'label.png' # with open(osp.join(out_dir, 'label_names.txt'), 'w') as f: # for lbl_name in label_names: # f.write(lbl_name + '\n') # # warnings.warn('info.yaml is being replaced by label_names.txt') info = dict(label_names=label_names) with open(osp.join(out_json_dir, 'info.yaml'), 'w') as f: yaml.safe_dump(info, f, default_flow_style=False) print('Saved to: %s' % out_json_dir) def main(): path = "/home/byz/dataset/DeepFashion/CAPB/" json_files = [file for file in os.listdir(path) if re.search(r'.json', file) != None] print("总共有%d条数据" % len(json_files)) # 289147条 print("start...") for file_name in json_files: json_name = file_name.split(".")[0].split("_")[1] #print("python json_to_dataset.py rgb_" + json_name + ".json /home/byz/Mask/Mask_RCNN/net_img") #'''执行每个输出''' excutor(path+file_name, json_name) #+"/" if __name__ == '__main__': main() # python json_to_dataset.py rgb_119322.json ######################################################## # 临时修改(可使用多线程),少量数据还是用上面代码转换 # path = "/home/byz/dataset/DeepFashion/CAPB/" # #json_files = [file for file in os.listdir(path) if re.search(r'.json', file) != None] # json_files = [file.split("_")[1].split(".")[0] for file in os.listdir(path) if re.search(r'.json', file) != None] # json_files = sorted(json_files) # # print("总共有%d条数据" % len(json_files)) # 28 9147条 # print("start...") # for file_name in json_files[270000:289148]: # excutor(path+"rgb_"+file_name+".json", file_name)
使用python语言将16位图像转换为8位图像,用于labelme标记的MASK_RCNN
因为opencv仅支持8位图像输入,所以需要做下转换,网上提供的都是C++的实现,这里照着写了个Python的脚本
(此步骤已经整合到之前代码,所以看看就行,不需要使用)
''' 我们需要将16位图像转换为8位图像;16位图像的像素值一共有:2^16=65536种颜色 而8位位图像只有:2^8=256种颜色,传统的位数转换都是:像素值*256/65536,比如photoshop,以及matlab的im2uint8函数都是如此, 在一般场景下是没有问题的,我们姑且称之为“真转换”,而如果是labelme得到的label.png标注图像在进行转换时, 由于每个类别的像素值从0开始赋值,如0,1,2,3,4.......如果进行“真转换”的话,由于这些值都太小, 基本转换后的像素值都是(0,1)之间,所以都变成了0,所以我们需要将16位转换位8位的时候还保留住原来的像素值, 这种只改变位数,而不改变具体数值的转换方法,姑且称之为“伪转换”; 而解决的思路也很简单,图像说白了也就是一个矩阵,像素值也就是一个数值而已,我们只需要把表示类别的像素值找出来,并且把他们的值投射到8位即可: 使用的软件环境如下: Python 3.6.3 VS2013 OPENCV 2.4.11 PIL Labelme 2.8.0 ''' from PIL import Image import numpy as np import math import os path = '/home/byz/Mask/Mask_RCNN/net_img/json/' newpath = '/home/byz/Mask/Mask_RCNN/net_img/mask/' #sprintf(buff1,"/home/byz/Mask/Mask_RCNN/net_img/json/rgb_%d_json/label.png",i); #sprintf(buff2,"/home/byz/Mask/Mask_RCNN/net-img/mask/%d.png",i); #/home/byz/Mask/Mask_RCNN/net_img/mask/89821.png def toeight(): filelist = os.listdir(path) # 该文件夹下所有的文件(包括文件夹) for file in filelist: new_png_name = file.split('_')[1] # ['rgb_2_json', 'rgb_3_json', 'rgb_1_json', 'rgb_5_json', 'rgb_4_json'] whole_path = os.path.join(path, file + '/label.png') img = Image.open(whole_path) # 打开图片img = Image.open(dir)#打开图片 img = np.array(img) # img = Image.fromarray(np.uint8(img / float(math.pow(2, 16) - 1) * 255)) img = Image.fromarray(np.uint8(img)) # 转换完成后,可以使用软件查看时候变为8位,但是打开图片依然是一片黑 # 如果需要提高类别之间的差异性,可以直接乘以一个较大的值,图片就会有明显的区分,如下: #img = Image.fromarray(np.uint8(img)*20) resize_mage = img.resize((512, 512),Image.ANTIALIAS) resize_mage.save(newpath + new_png_name + '.png') #resize_mage.save('/home/byz/Mask/Mask_RCNN/net_img/mask/114372.png') toeight()
至此,数据处理阶段完成,接下来就可以跑Mask-RCNN的训练代码了
import os import sys import random import math import re import time import numpy as np import cv2 import matplotlib import matplotlib.pyplot as plt from mrcnn.config import Config from mrcnn import utils import mrcnn.model as modellib from mrcnn import visualize from mrcnn.model import log from tensorflow.examples.tutorials.mnist.input_data import read_data_sets import yaml from PIL import Image # 控制程序可见的GPU # os.environ["CUDA_VISIBLE_DEVICES"] = "0" ROOT_DIR = os.getcwd() # 保存产生的日志和已训练的权重文件 MODEL_DIR = os.path.join(ROOT_DIR, "logs") # 预训练权重文件 COCO_MODEL_PATH = "./model/mask_rcnn_clothes_600.h5" # 一开始是用的coco权重 if not os.path.exists(COCO_MODEL_PATH): print("请先下载预训练权重文件!") # 在全局定义一个 iter_num=0 iter_num = 0 # global, modify def get_ax(rows=1, cols=1, size=8): _, ax = plt.subplots(rows, cols, figsize=(size * cols, size * rows)) return ax class ShapesConfig(Config): NAME = "shapes" GPU_COUNT = 1 IMAGES_PER_GPU = 4 #根据自己电脑配置修改参数,由于该工程用的resnet101为主干的网络,训练需要大量的显存支持 NUM_CLASSES = 1 + 46 #NUM_CLASSES = 1 + 46 为你数据集的类别数,第一类为bg,我的是46类,所以为1+46 IMAGE_MIN_DIM = 512 #800 IMAGE_MAX_DIM = 512 #1280 修改为自己图片尺寸 RPN_ANCHOR_SCALES = (8 * 3, 16 * 3, 32 * 3, 64 * 3, 128 * 3) #改成3对应512尺寸,比较合适 (8 * 6, 16 * 6, 32 * 6, 64 * 6, 128 * 6) #根据自己情况设置anchor大小 TRAIN_ROIS_PER_IMAGE = 32 STEPS_PER_EPOCH = 2000 #20000 VALIDATION_STEPS = 5 config = ShapesConfig() config.display() # 自定义数据集类 class ClothesDataset(utils.Dataset): def get_obj_index(self, image): ''' 得到该图中有多少个物体 :param i: :param age: :return: ''' n = np.max(image) return n def from_yaml_get_class(self, image_id): ''' 解析labelme中得到yaml文件,从而得到mask每一层对应的实例标签 :param image_id: :return: ''' info = self.image_info[image_id] with open(info['yaml_path']) as f: temp = yaml.load(f.read()) labels = temp['label_names'] del labels[0] return labels def draw_mask(self, num_obj, mask, image,image_id): info = self.image_info[image_id] for index in range(num_obj): for i in range(info['width']): for j in range(info['height']): at_pixel = image.getpixel((i, j)) if at_pixel == index + 1: mask[j, i, index] = 1 return mask def load_shapes(self, count, height, width, img_floder, mask_floder, imglist, dataset_root_path): ''' 重新写load_shapes,里面包含的是自己的类别(这里是box、column、package、fruit四类) #并在self.image_info信息中添加了path、mask_path 、yaml_path :param count: :param height: :param width: :param img_floder: :param mask_floder: :param imglist: :param dataset_root_path: :return: ''' # Add classes self.add_class("shapes", 1, "Anorak") self.add_class("shapes", 2, "Blazer") self.add_class("shapes", 3, "Blouse") self.add_class("shapes", 4, "Bomber") self.add_class("shapes", 5, "Button-Down") self.add_class("shapes", 6, "Cardigan") self.add_class("shapes", 7, "Flannel") self.add_class("shapes", 8, "Halter") self.add_class("shapes", 9, "Henley") self.add_class("shapes", 10, "Hoodie") self.add_class("shapes", 11, "Jacket") self.add_class("shapes", 12, "Jersey") self.add_class("shapes", 13, "Parka") self.add_class("shapes", 14, "Peacoat") self.add_class("shapes", 15, "Poncho") self.add_class("shapes", 16, "Sweater") self.add_class("shapes", 17, "Tank") self.add_class("shapes", 18, "Tee") self.add_class("shapes", 19, "Top") self.add_class("shapes", 20, "Turtleneck") self.add_class("shapes", 21, "Capris") self.add_class("shapes", 22, "Chinos") self.add_class("shapes", 23, "Culottes") self.add_class("shapes", 24, "Cutoffs") self.add_class("shapes", 25, "Gauchos") self.add_class("shapes", 26, "Jeans") self.add_class("shapes", 27, "Jeggings") self.add_class("shapes", 28, "Jodhpurs") self.add_class("shapes", 29, "Joggers") self.add_class("shapes", 30, "Leggings") self.add_class("shapes", 31, "Sarong") self.add_class("shapes", 32, "Shorts") self.add_class("shapes", 33, "Skirt") self.add_class("shapes", 34, "Sweatpants") self.add_class("shapes", 35, "Sweatshorts") self.add_class("shapes", 36, "Trunks") self.add_class("shapes", 37, "Caftan") self.add_class("shapes", 38, "Romper") self.add_class("shapes", 39, "Coat") self.add_class("shapes", 40, "Coverup") self.add_class("shapes", 41, "Dress") self.add_class("shapes", 42, "Jumpsuit") self.add_class("shapes", 43, "Kaftan") self.add_class("shapes", 44, "Kimono") self.add_class("shapes", 45, "Robe") self.add_class("shapes", 46, "Onesie") # self.add_class("shapes", 47, "Nightdress") # self.add_class("shapes", 48, "Cape") # self.add_class("shapes", 49, "Shirtdress") # self.add_class("shapes", 50, "Sundress") for i in range(count): filestr = imglist[i].split(".")[0] filestr = filestr.split("_")[1] # rgb_2.jpg mask_path = mask_floder + "/" + filestr + ".png" yaml_path = dataset_root_path + "json/rgb_" + filestr + "_json/info.yaml" self.add_image("shapes", image_id=i, path=img_floder + "/" + imglist[i], width=width, height=height, mask_path=mask_path, yaml_path=yaml_path) def load_mask(self, image_id): ''' 重写 :param image_id: :return: ''' global iter_num info = self.image_info[image_id] count = 1 # number of object img = Image.open(info['mask_path']) num_obj = self.get_obj_index(img) mask = np.zeros([info['height'], info['width'], num_obj], dtype=np.uint8) mask = self.draw_mask(num_obj, mask, img, image_id) occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8) for i in range(count - 2, -1, -1): mask[:, :, i] = mask[:, :, i] * occlusion occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i])) labels = [] labels = self.from_yaml_get_class(image_id) labels_form = [] for i in range(len(labels)): if labels[i].find("Anorak") != -1: # print "Anorak" labels_form.append("Anorak") elif labels[i].find("Blazer") != -1: # print ""Blazer" labels_form.append("Blazer") elif labels[i].find("Blouse") != -1: labels_form.append("Blouse") elif labels[i].find("Bomber") != -1: labels_form.append("Bomber") elif labels[i].find("Button-Down") != -1: labels_form.append("Button-Down") elif labels[i].find("Cardigan") != -1: labels_form.append("Cardigan") elif labels[i].find("Flannel") != -1: labels_form.append("Flannel") elif labels[i].find("Halter") != -1: labels_form.append("Halter") elif labels[i].find("Henley") != -1: labels_form.append("Henley") elif labels[i].find("Hoodie") != -1: labels_form.append("Hoodie") elif labels[i].find("Jacket") != -1: labels_form.append("Jacket") elif labels[i].find("Jersey") != -1: labels_form.append("Jersey") elif labels[i].find("Parka") != -1: labels_form.append("Parka") elif labels[i].find("Peacoat") != -1: labels_form.append("Peacoat") elif labels[i].find("Poncho") != -1: labels_form.append("Poncho") elif labels[i].find("Sweater") != -1: labels_form.append("Sweater") elif labels[i].find("Tank") != -1: labels_form.append("Tank") elif labels[i].find("Tee") != -1: labels_form.append("Tee") elif labels[i].find("Top") != -1: labels_form.append("Top") elif labels[i].find("Turtleneck") != -1: labels_form.append("Turtleneck") elif labels[i].find("Capris") != -1: labels_form.append("Capris") elif labels[i].find("Chinos") != -1: labels_form.append("Chinos") elif labels[i].find("Culottes") != -1: labels_form.append("Culottes") elif labels[i].find("Cutoffs") != -1: labels_form.append("Cutoffs") elif labels[i].find("Gauchos") != -1: labels_form.append("Gauchos") elif labels[i].find("Jeans") != -1: labels_form.append("Jeans") elif labels[i].find("Jeggings") != -1: labels_form.append("Jeggings") elif labels[i].find("Jodhpurs") != -1: labels_form.append("Jodhpurs") elif labels[i].find("Joggers") != -1: labels_form.append("Joggers") elif labels[i].find("Leggings") != -1: labels_form.append("Leggings") elif labels[i].find("Sarong") != -1: labels_form.append("Sarong") elif labels[i].find("Shorts") != -1: labels_form.append("Shorts") elif labels[i].find("Skirt") != -1: labels_form.append("Skirt") elif labels[i].find("Sweatpants") != -1: labels_form.append("Sweatpants") elif labels[i].find("Sweatshorts") != -1: labels_form.append("Sweatshorts") elif labels[i].find("Trunks") != -1: labels_form.append("Trunks") elif labels[i].find("Caftan") != -1: labels_form.append("Caftan") elif labels[i].find("Coat") != -1: labels_form.append("Coat") elif labels[i].find("Coverup") != -1: labels_form.append("Coverup") elif labels[i].find("Dress") != -1: labels_form.append("Dress") elif labels[i].find("Jumpsuit") != -1: labels_form.append("Jumpsuit") elif labels[i].find("Kaftan") != -1: labels_form.append("Kaftan") elif labels[i].find("Kimono") != -1: labels_form.append("Kimono") elif labels[i].find("Onesie") != -1: labels_form.append("Onesie") elif labels[i].find("Robe") != -1: labels_form.append("Robe") elif labels[i].find("Romper") != -1: labels_form.append("Romper") # elif labels[i].find("Shirtdress") != -1: # labels_form.append("Shirtdress") # elif labels[i].find("Sundress") != -1: # labels_form.append("Sundress") # elif labels[i].find("Cape") != -1: # labels_form.append("Cape") # elif labels[i].find("Nightdress") != -1: # labels_form.append("Nightdress") class_ids = np.array([self.class_names.index(s) for s in labels_form]) return mask, class_ids.astype(np.int32) # 基础设置 dataset_root_path = "/home/byz/Mask/Mask_RCNN/net_img/" img_floder = dataset_root_path + "rgb" mask_floder = dataset_root_path + "mask" # yaml_floder = dataset_root_path imglist = os.listdir(img_floder) count = len(imglist) dataset_train_count = round(0.7 * count) dataset_val_count = round(0.2 * count) dataset_test_count = round(0.1 * count) width = 512 #1280 height = 512 #800 # train与val数据集准备 dataset_train = ClothesDataset() dataset_train.load_shapes(count, height, width, img_floder, mask_floder, imglist, dataset_root_path) dataset_train.prepare() dataset_val = ClothesDataset() dataset_val.load_shapes(count, height, width, img_floder, mask_floder, imglist, dataset_root_path) dataset_val.prepare() # # 随机选取4个样本展示 Load and display random samples # image_ids = np.random.choice(dataset_train.image_ids, 2) # for image_id in image_ids: # image = dataset_train.load_image(image_id) # mask, class_ids = dataset_train.load_mask(image_id) # print(mask) # print(class_ids) # visualize.display_top_masks(image, mask, class_ids, dataset_train.class_names) # 随机选取4个样本展示 Load and display random samples # image_id = np.random.choice(dataset_train.image_ids, 10) # # image = dataset_train.load_image(483) # mask, class_ids = dataset_train.load_mask(483) # # print(mask) # # print(class_ids) # visualize.display_top_masks(image, mask, class_ids, dataset_train.class_names) model = modellib.MaskRCNN(mode="training", config=config, model_dir=MODEL_DIR) #model = modellib.MaskRCNN(mode="training", config=config, model_dir=MODEL_DIR) # model.load_weights(filepath=COCO_MODEL_PATH, by_name=True,exclude=["mrcnn_class_logits", "mrcnn_bbox_fc","mrcnn_bbox", "mrcnn_mask"]) # Which weights to start with? init_with = "coco" # imagenet, coco, or last if init_with == "imagenet": model.load_weights(model.get_imagenet_weights(), by_name=True) elif init_with == "coco": # 加载coco权重,但是跳过由于不同类别的层 model.load_weights(filepath=COCO_MODEL_PATH, by_name=True, exclude=["mrcnn_class_logits", "mrcnn_bbox_fc", "mrcnn_bbox", "mrcnn_mask"]) elif init_with == "last": # Load the last model you trained and continue training model.load_weights(model.find_last()[1], by_name=True) print("=========训练模型:") model.train(dataset_train, dataset_val, learning_rate=config.LEARNING_RATE, epochs=200, layers='heads') print("=========微调所有层:") model.train(dataset_train, dataset_val, learning_rate=config.LEARNING_RATE / 10, epochs=60, layers="all") # Save weights # Typically not needed because callbacks save after every epoch # Uncomment to save manually model_path = "./model/mrcnn_train_clothes_800_pochs.h5" model.keras_model.save_weights(model_path) print("模型训练成功:" + model_path)
。。。。有事离开一下 明天继续