一、说明与准备
此次实验数据集制作是PASCAL VOC数据集制作,针对mask-RCNN实例分割制作PASCAL VOC数据集,以pycharm环境进行演示
1、首先手动创建如下文件夹:
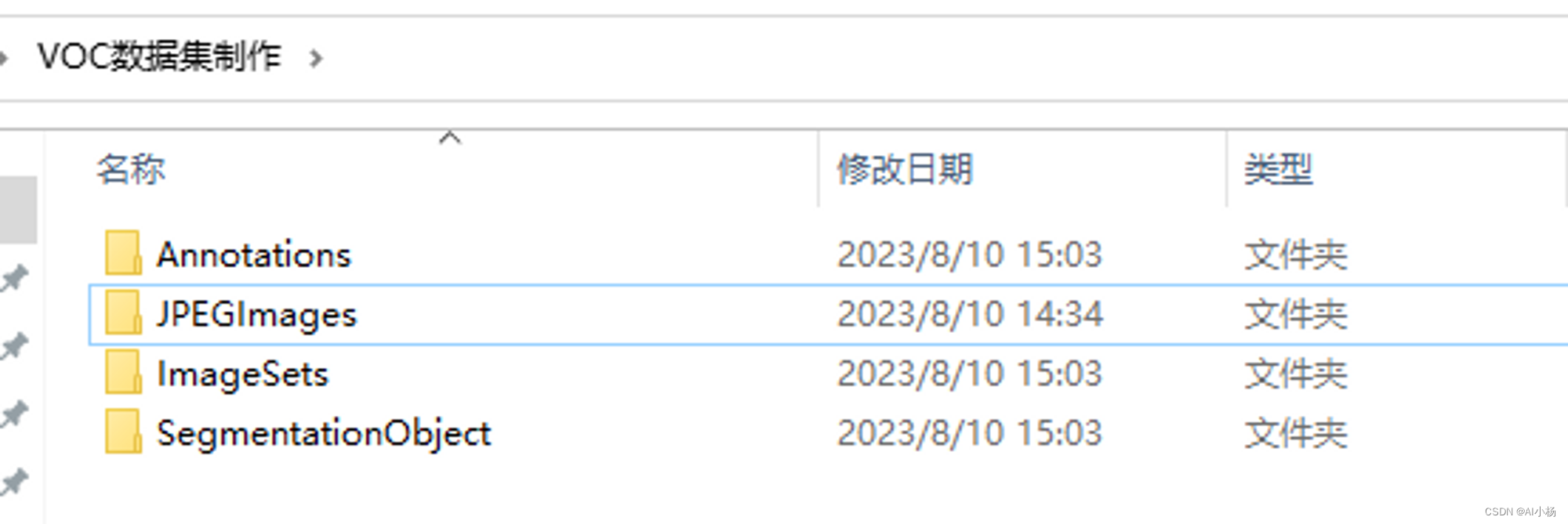
手动创建如上四个文件夹,便于后期操作。
2、安装环境
pip install labelimg
pip install labelme
在pycharm软件的终端中输入以上代码,安装labelimg库和labelme库
二、Annotations文件夹下的XML文件制作(目标检测数据标注)
标注xml文件用labelimg工具,操作如下:
1、打开环境
如下图,第一次打开失败了,报错如下,原因labelimg是不支持python3.10的版本,支持3.9 的版本。于是我切换到安装有python3.9的conda环境中去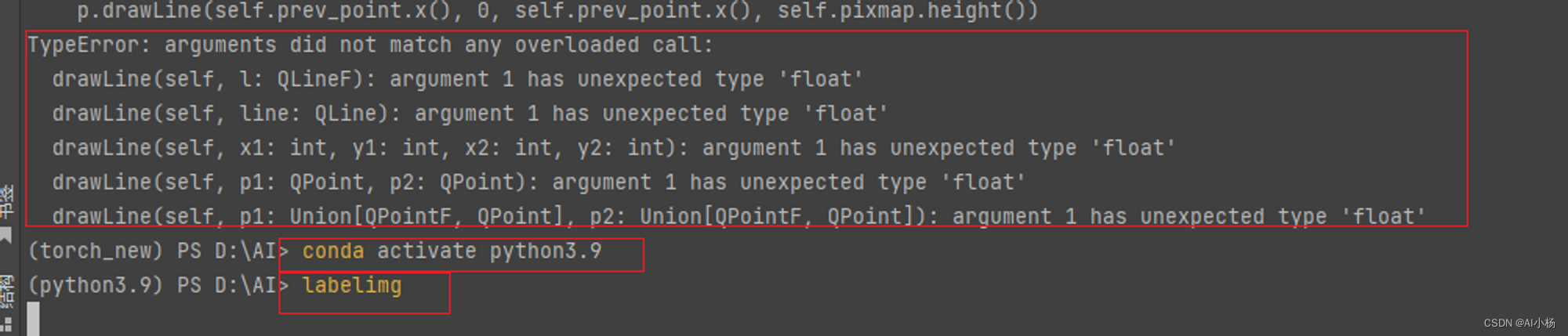
2、加载数据集
选择需要标注的数据集,即原图片存放位置,我存放到JPEGImages文件夹中的。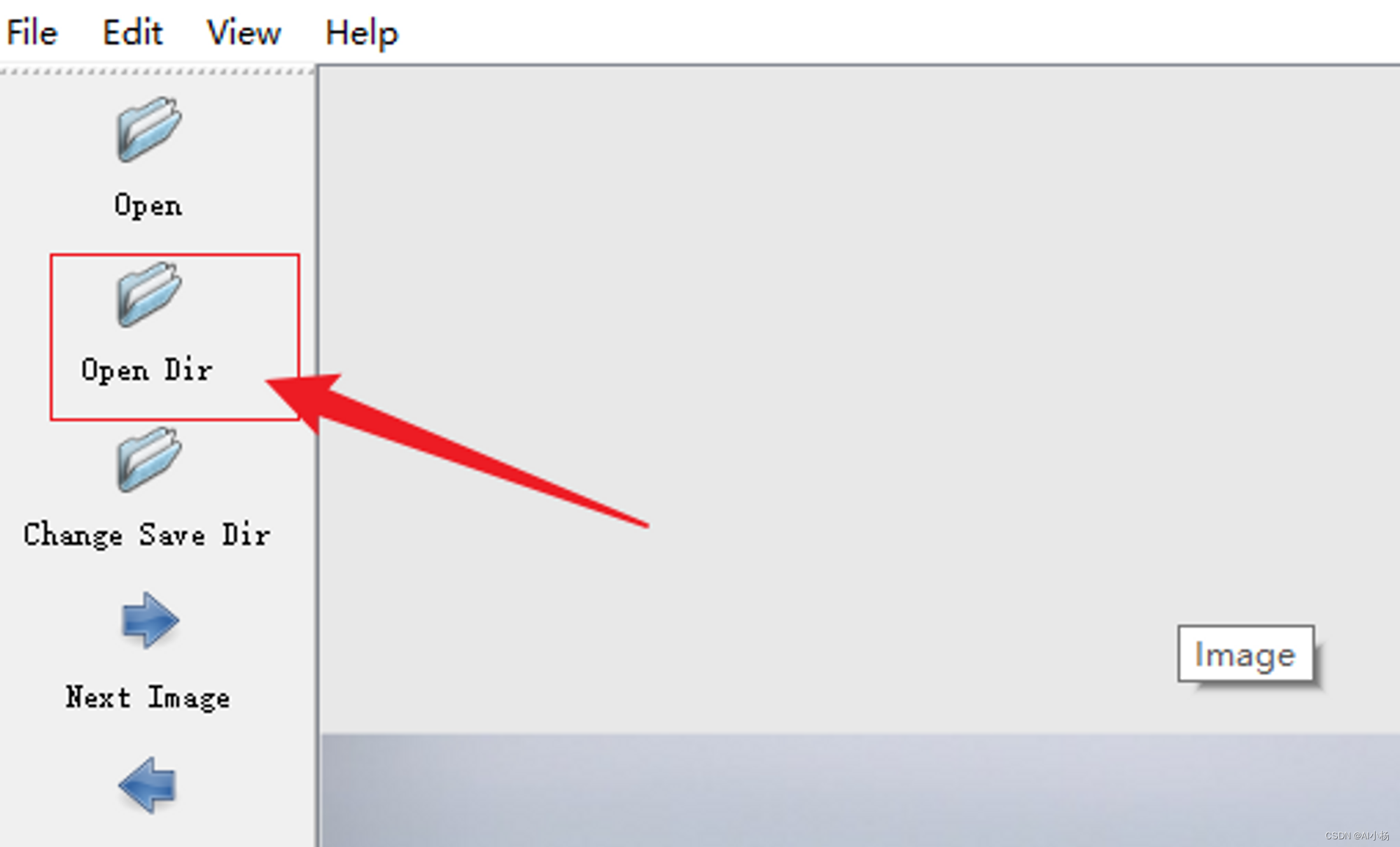
选择标注类型:选择矩形框进行标注
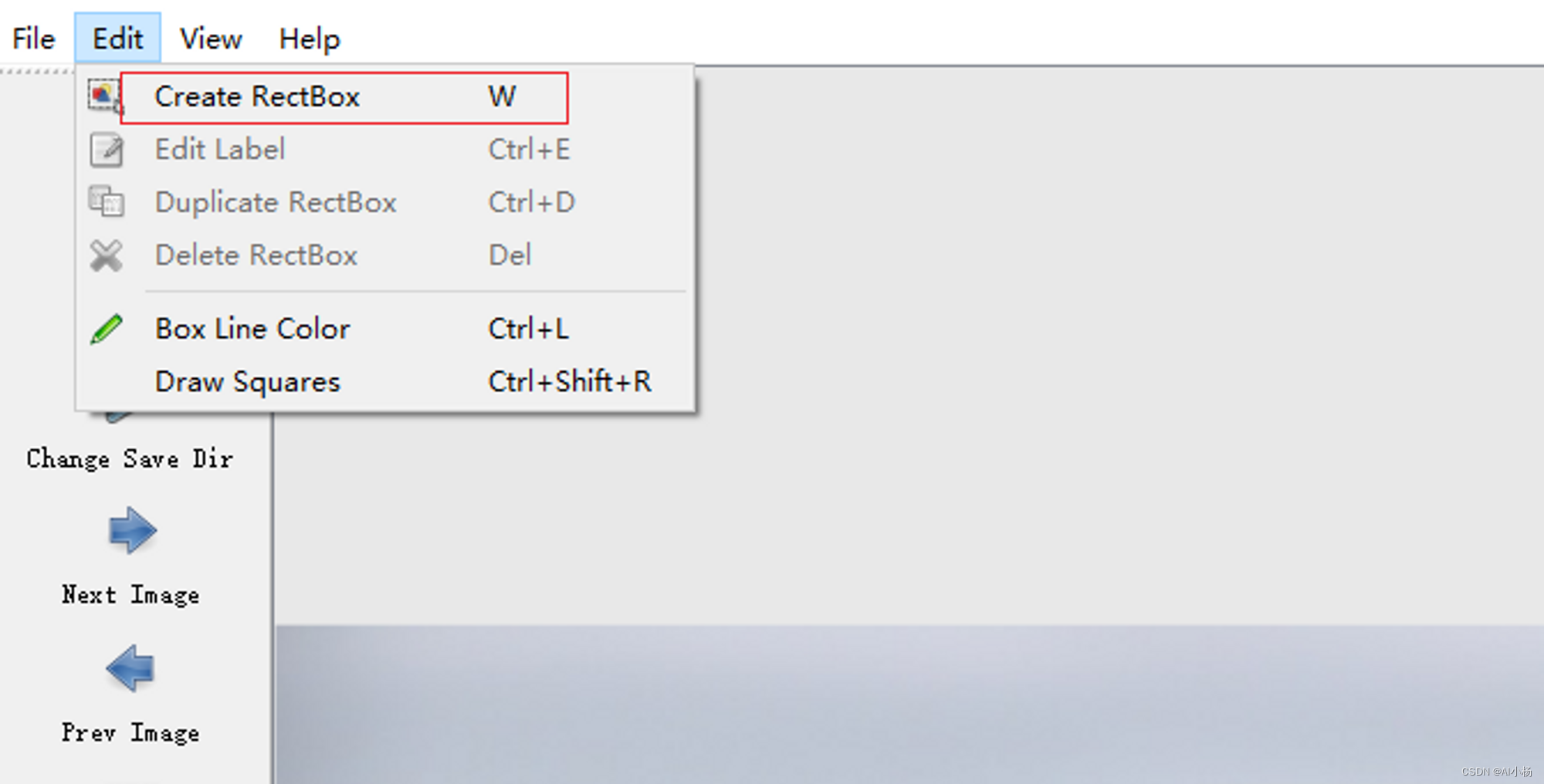
3、标注
用矩形框框住目标物,然后输入对应标签:
标注完成后选择保存的文件夹,保存在上述创建的Annotations文件中:
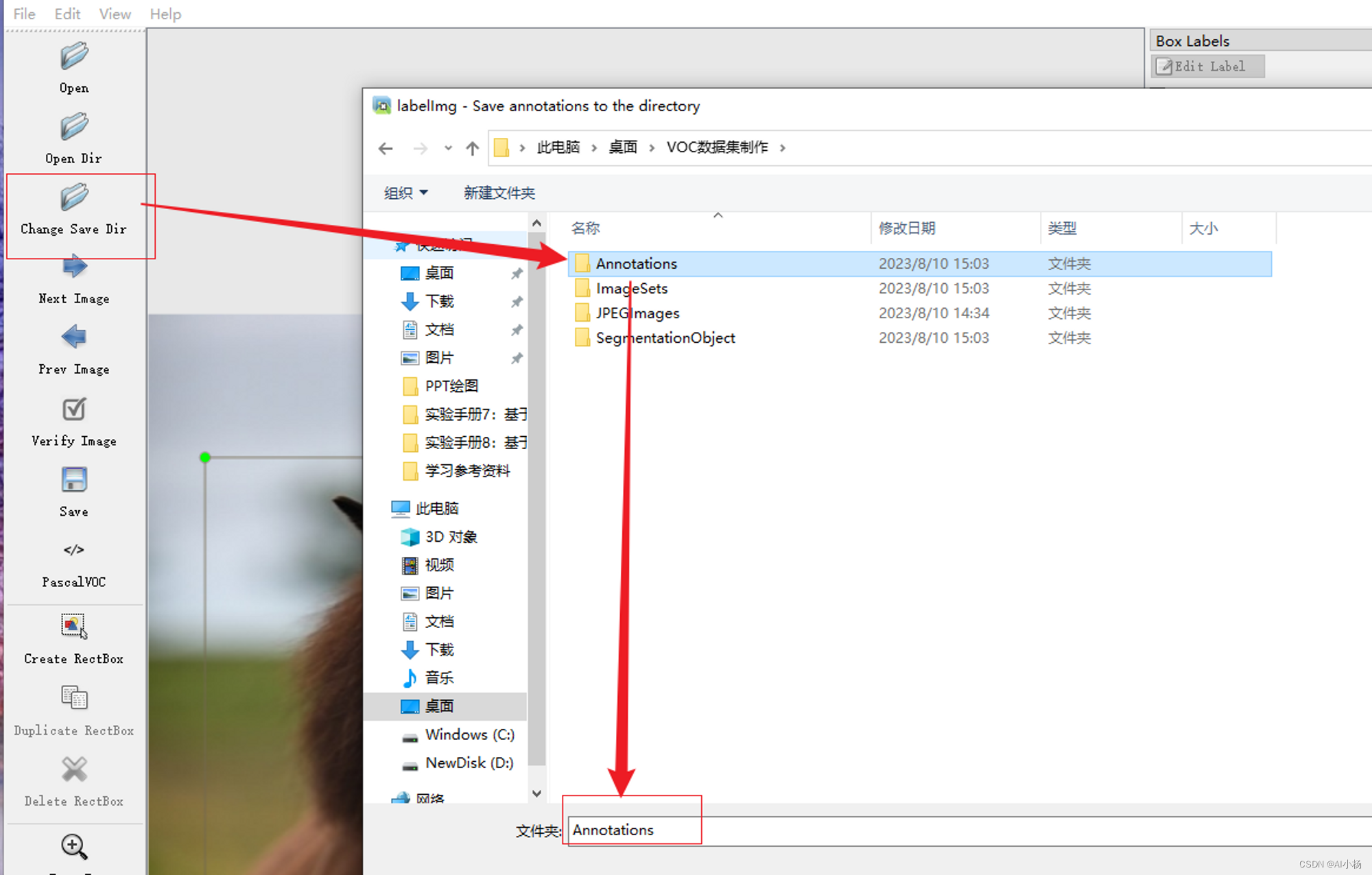
第一张图片标注完成,接下来是快捷键标注其他图片:
标注快捷键:
按W标注
ctrl+s保存
d切换下一张,
直到标注完成,就得到了VOC里面的Annotations文件下的xml文件了
标注完成后的xml文件如下图:

xml标注文件的部分内容展示如下:
<annotation>
<folder>images</folder>
<filename>0ada72de6a864e998c6da2192e327c22.jpg</filename>
<path>C:\Users\xxx\Desktop\VOC数据集制作\images\0ada72de6a864e998c6da2192e327c22.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>640</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>horse</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>36</xmin>
<ymin>92</ymin>
<xmax>510</xmax>
<ymax>626</ymax>
</bndbox>
</object>
</annotation>
xml文件标注完成了
三、SegmentationObject文件夹下的实例分割文件标注
1、标注这个文件用labelme工具,在pycharm中的打开方式,终端中输入labelme

2、选择标注数据-选择JPEGImages文件夹

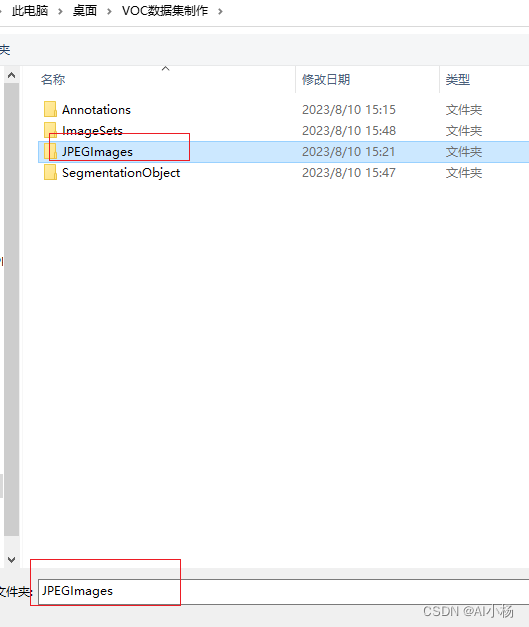
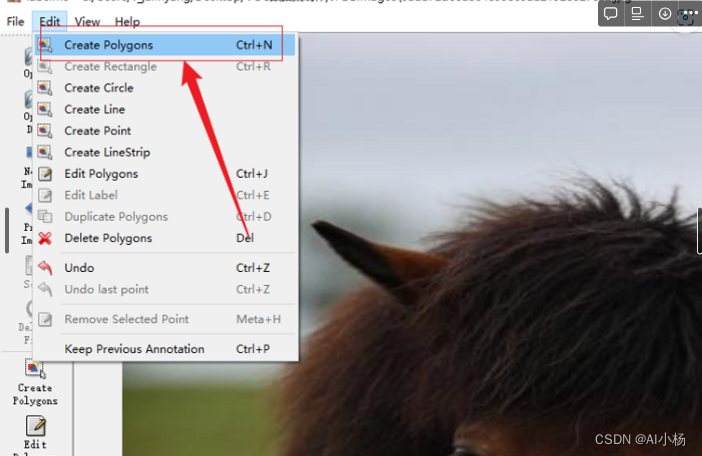
3、选择标注方式
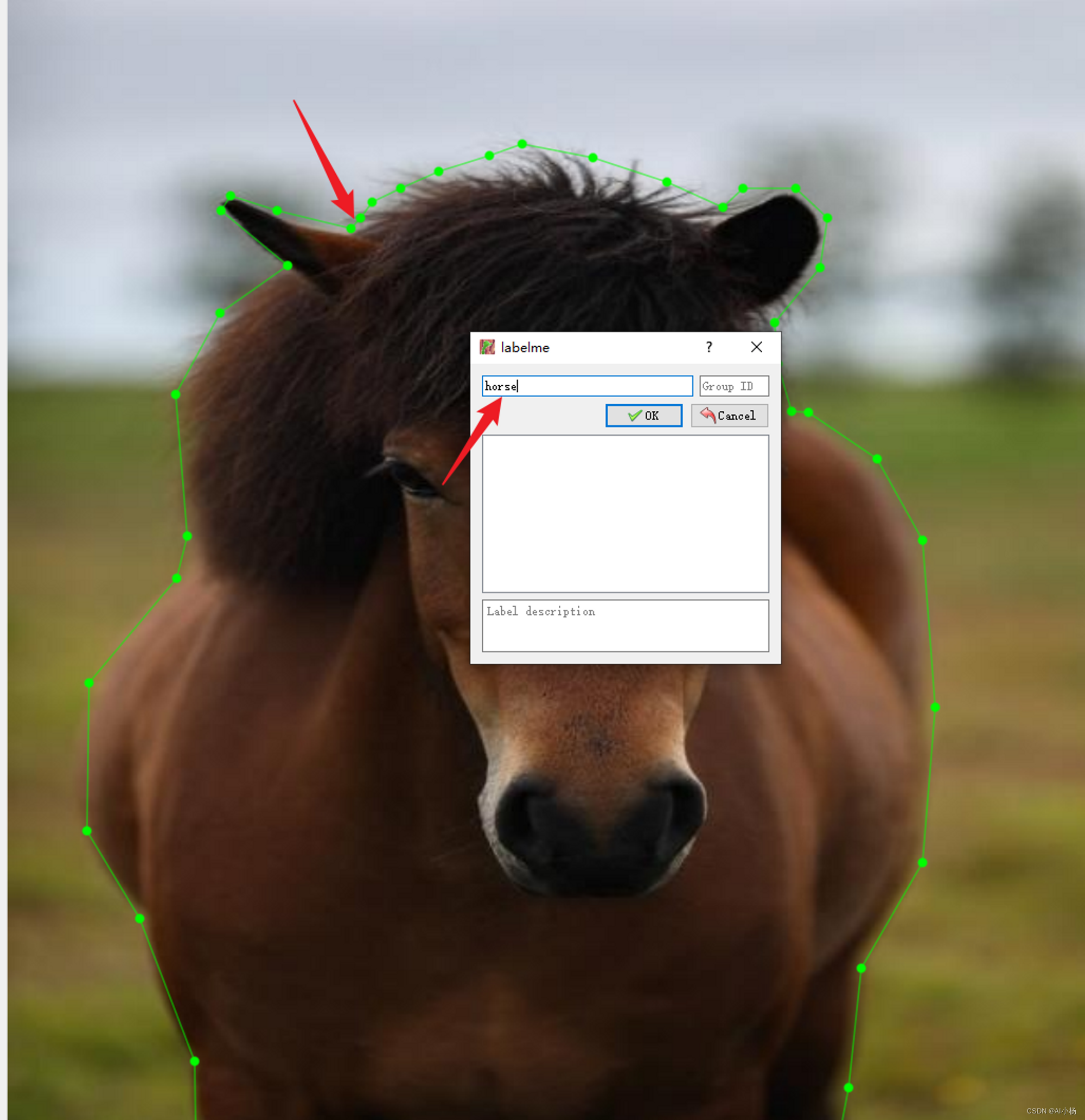
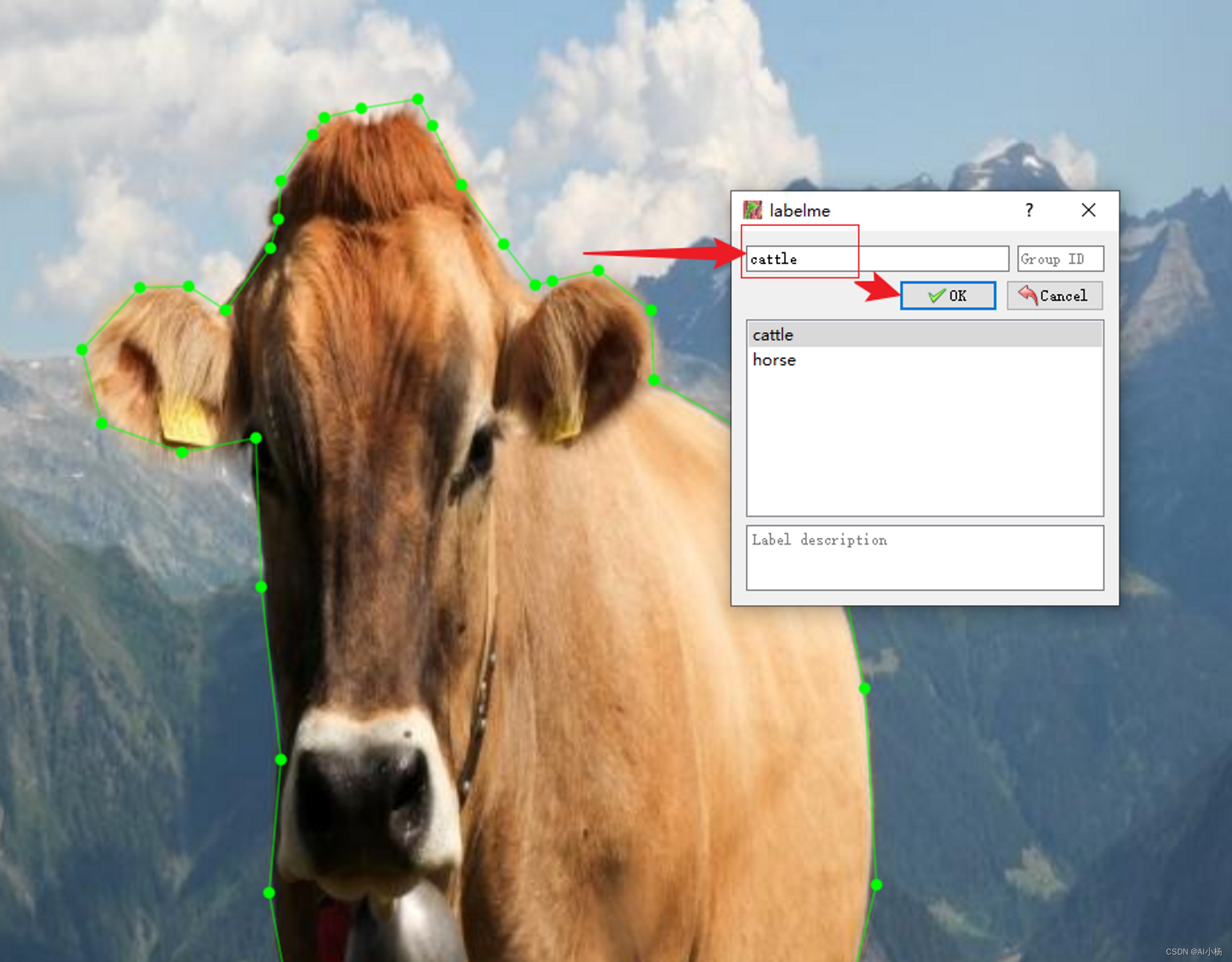
4、开始标注-对目标物进行贴边标注-标注完成输入对应的标签(注意标签名需要和上面的xml标注时的标签名保持一致)
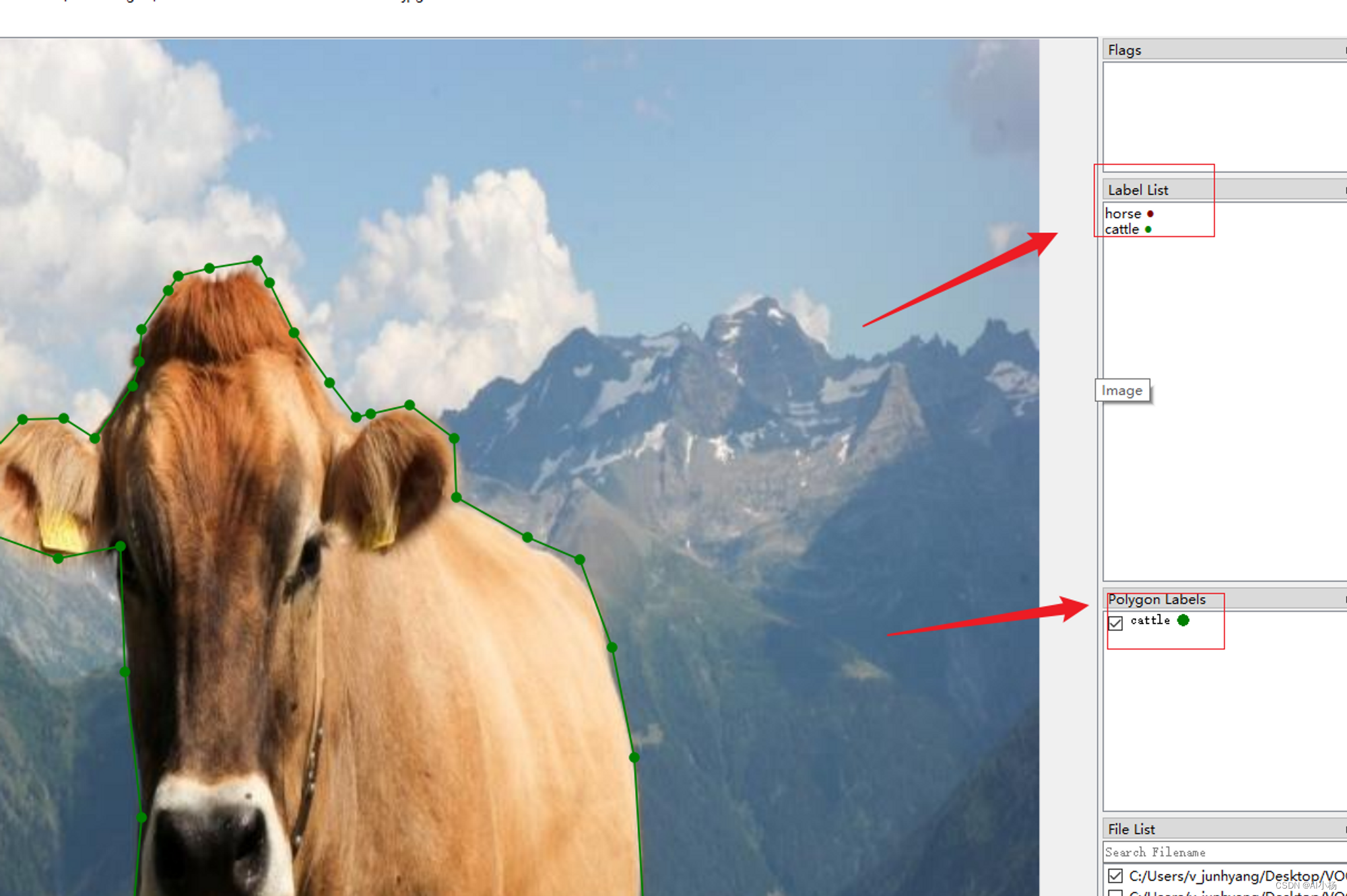
标注完成按ctrl+s进行保存,保存到原文件夹中:

继续标注:
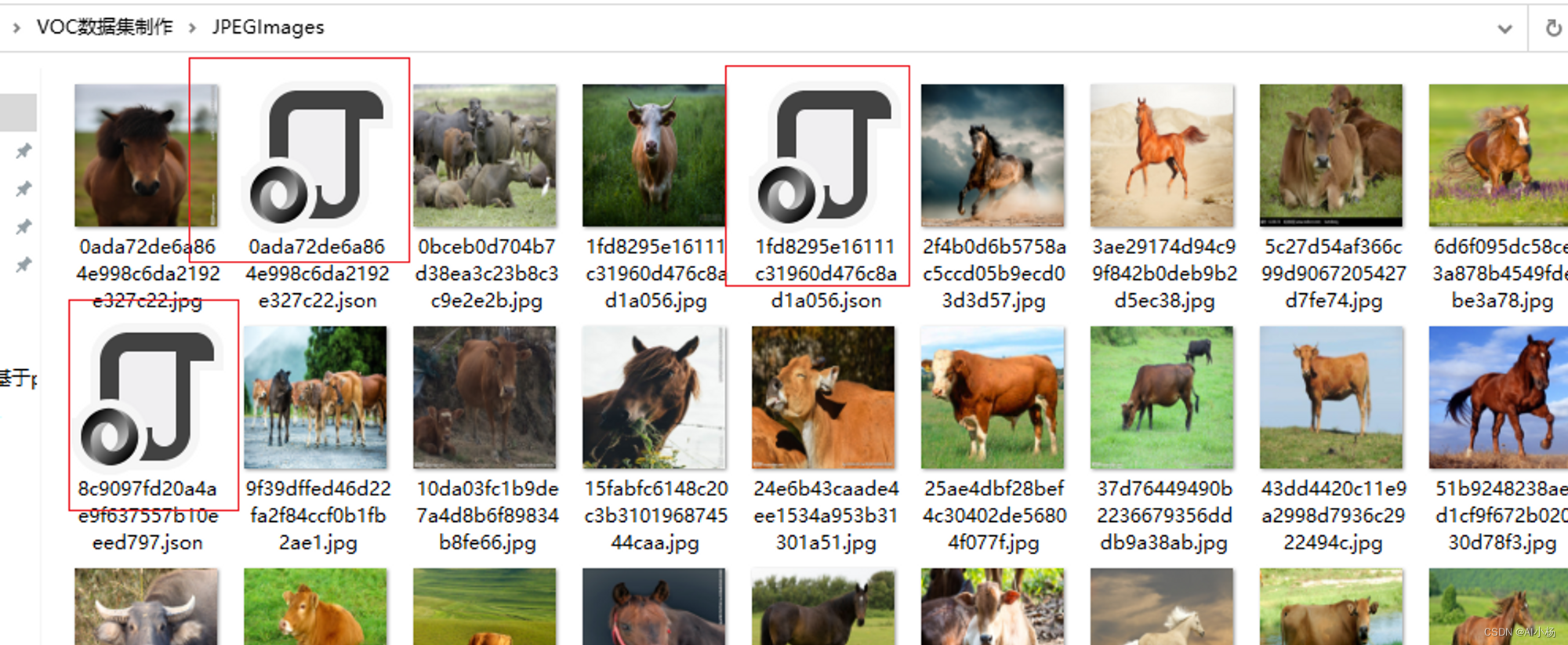
标注好后一张图片对应一个json文件,如下图(我只标注三张图片):
5、下载labelme处理文件
下载网址:labelme-实例分割处理源代码
点击进入上述网址,下载源代码如下:
下载好的源代码解压后得到一个名为labelme-main的文件夹。
将标注好的图片及对应的json文件复制到下载的源代码中的这个路径:
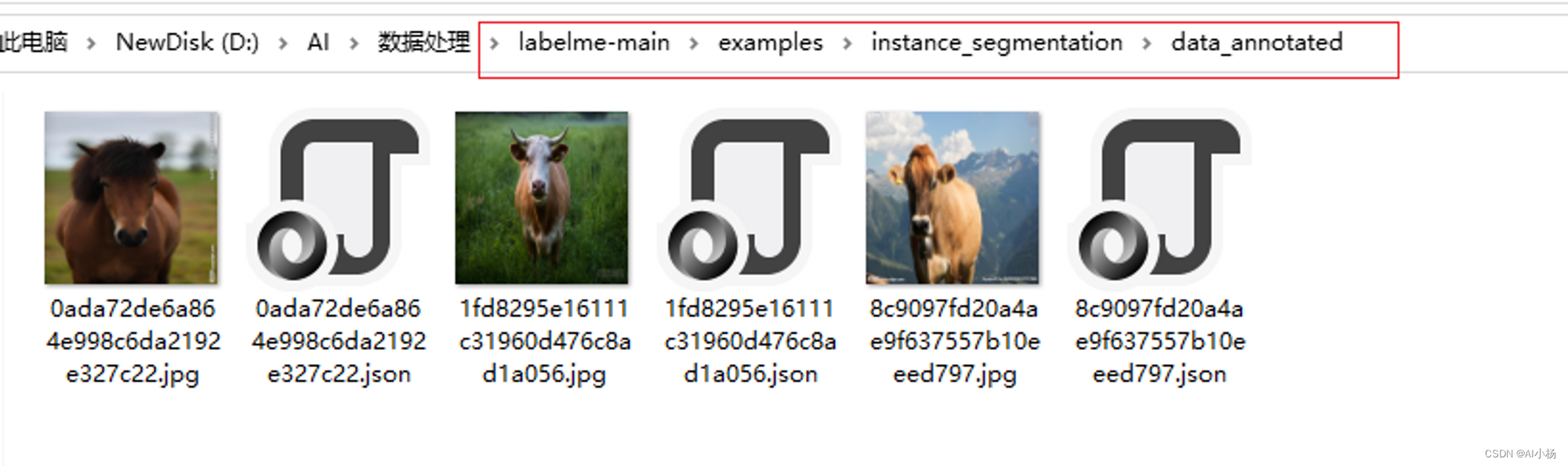
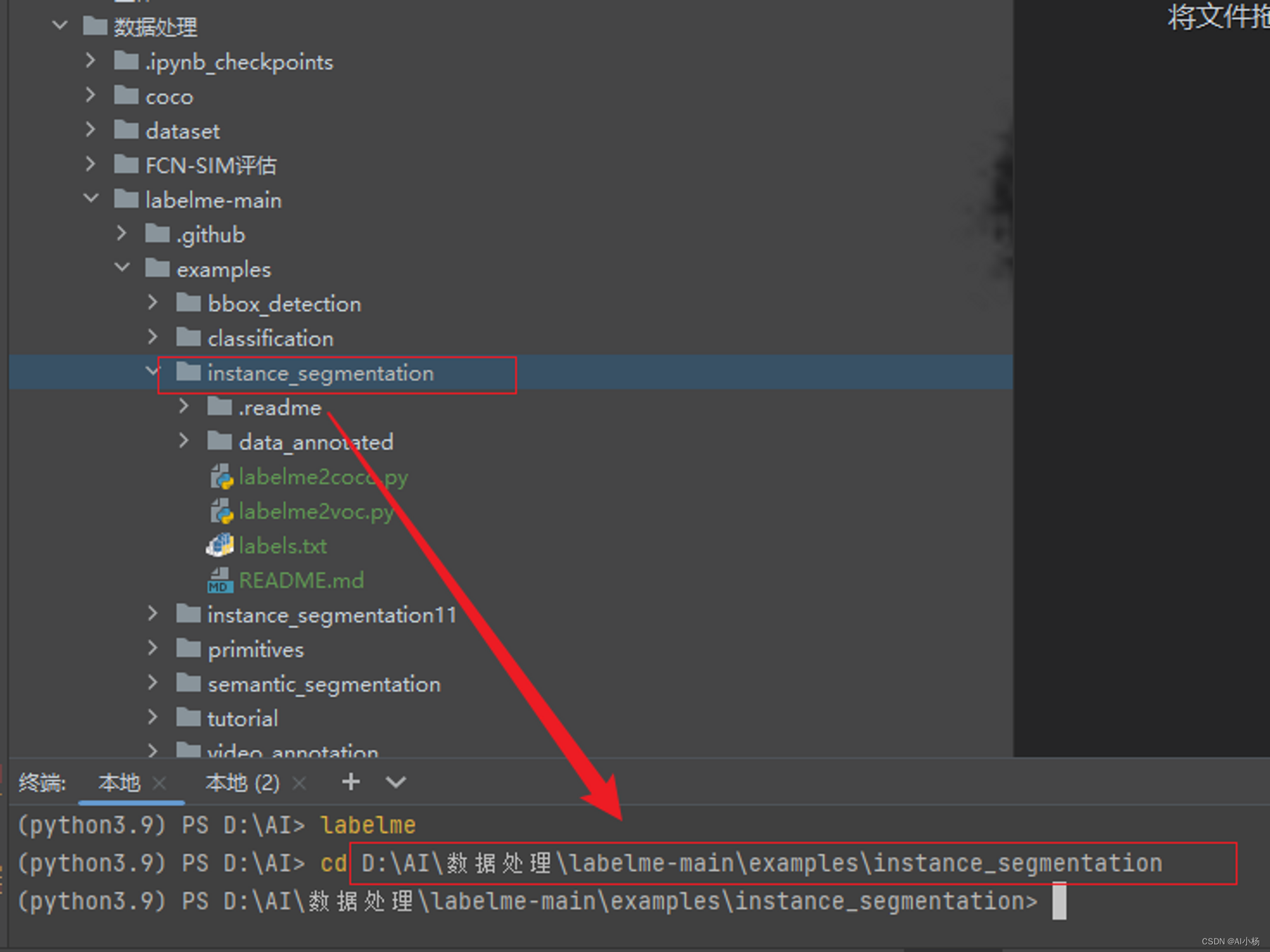
pycharm终端路径cd进入到如下路径:
labelme-main\examples\instance_segmentation\data_annotated
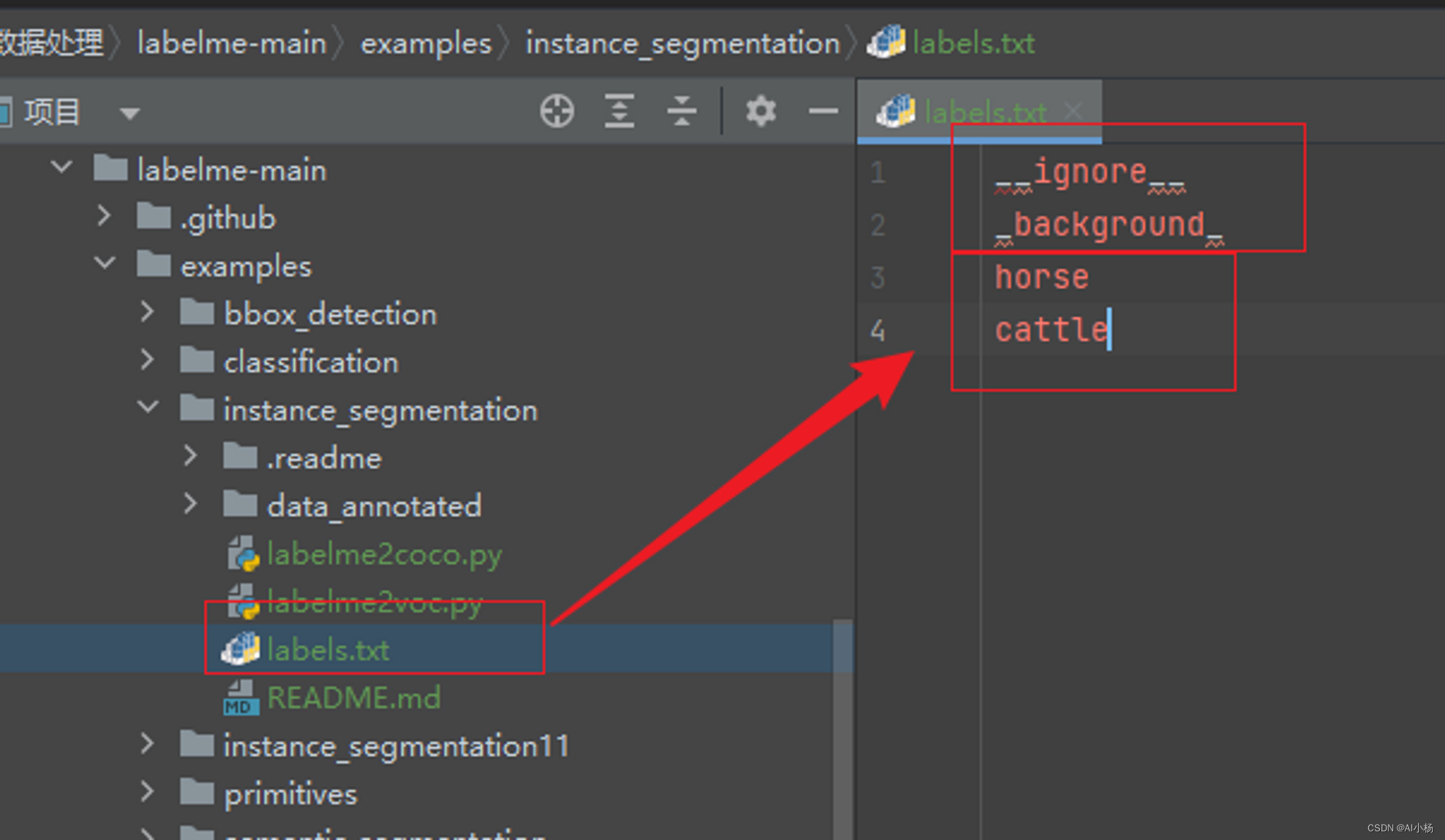
打开如下txt文件夹,将标签名字放到里面,第一行和第二行不要动,标签名从第三行开始放入:
在终端中输入以下指令进行数据标注处理:
python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt

处理完成后会在如下位置生成data_dataset_voc文件夹:
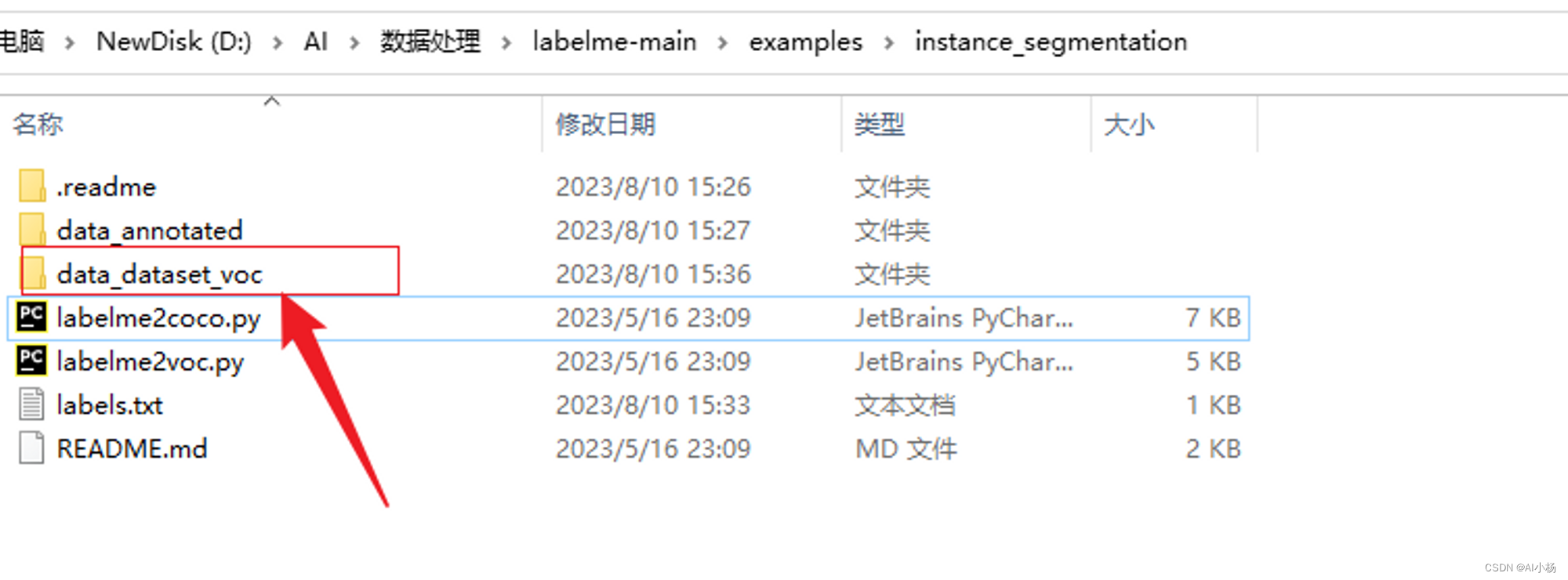
该文件夹里面有如下数据:
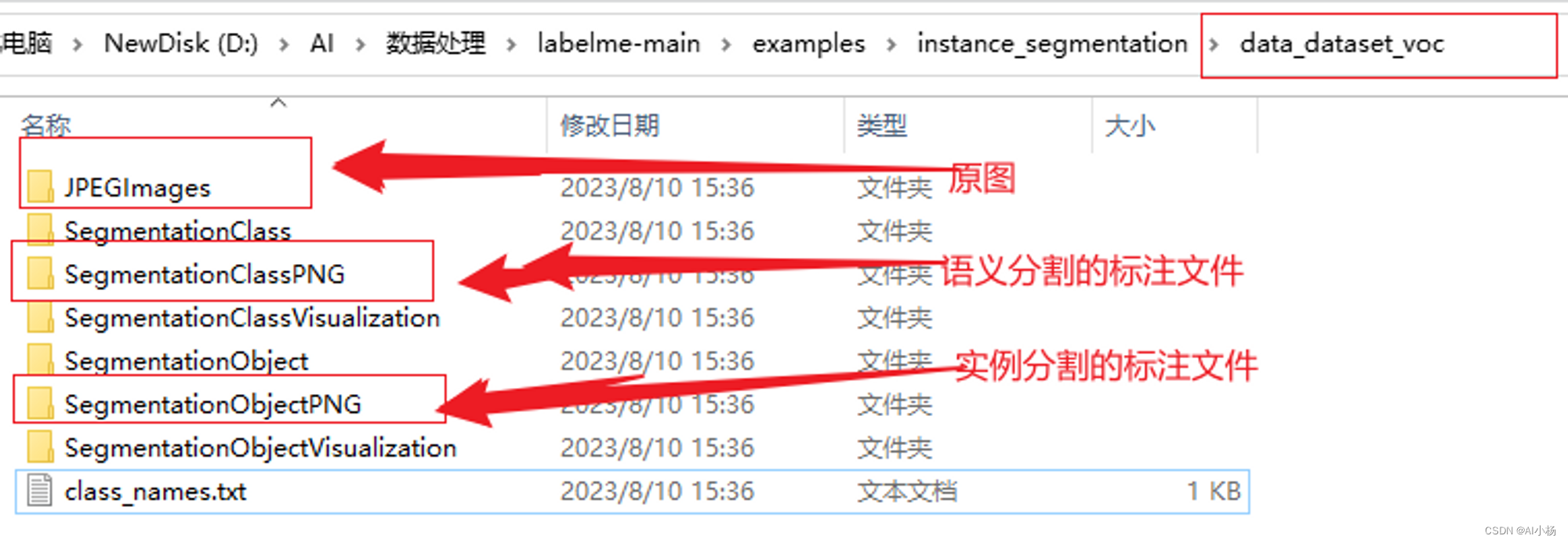
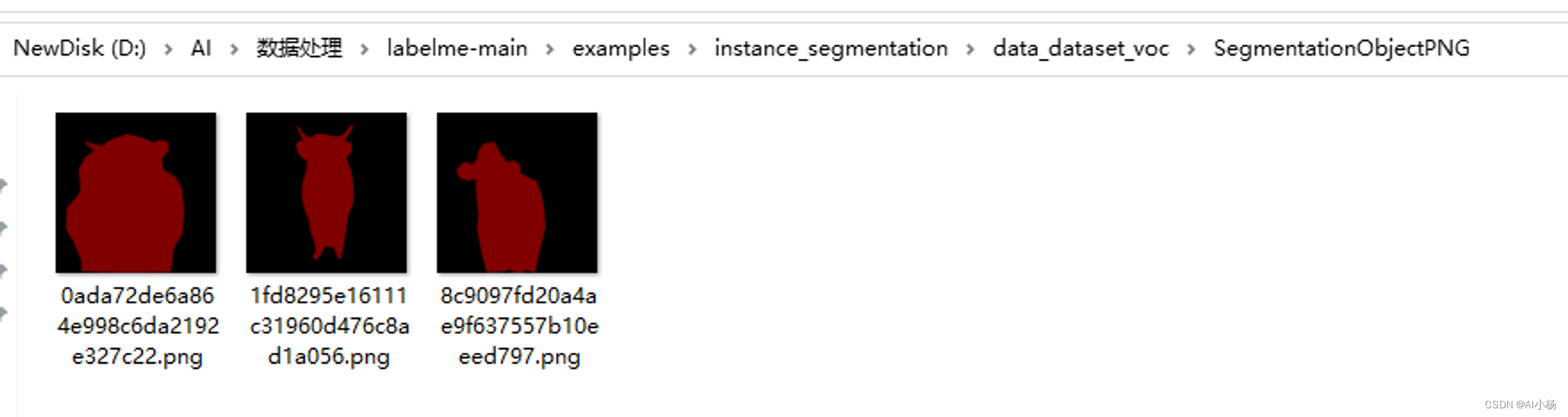
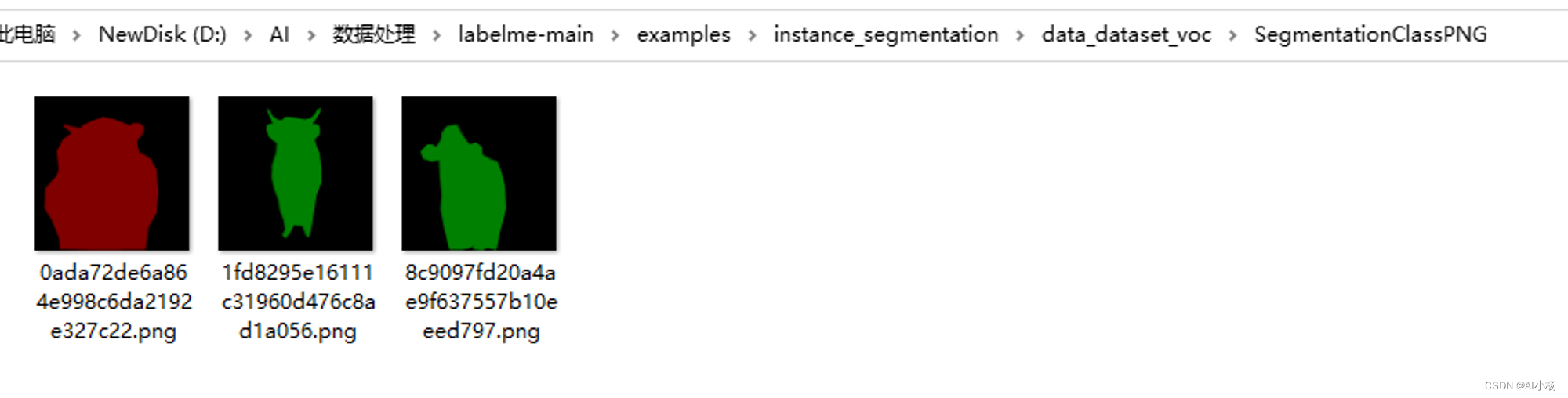
将实例分割的标注文件复制到开头创建的SegmentationObject文件夹中
6、制作ImageSets/Segmentation数据
运行如下代码:
from sklearn.model_selection import train_test_split
import os
imagedir = r'C:\Users\xxx\Desktop\VOC数据集制作\SegmentationObject'
outdir = r'C:\Users\xxx\Desktop\VOC数据集制作\ImageSets\Segmentation/'
images = []
for file in os.listdir(imagedir):
filename = file.split('.')[0]
images.append(filename)
train, test = train_test_split(images, train_size=0.9,random_state=0)#90%
val, test = train_test_split(test, train_size=0.2 / 0.3, random_state=0)#剩下的百分之十,前者占2后者占3
with open(outdir + "train.txt", 'w') as f:
f.write('\n'.join(train))
with open(outdir + "val.txt", 'w') as f:
f.write('\n'.join(val))
with open(outdir + "test.txt", 'w') as f:
f.write('\n'.join(test))
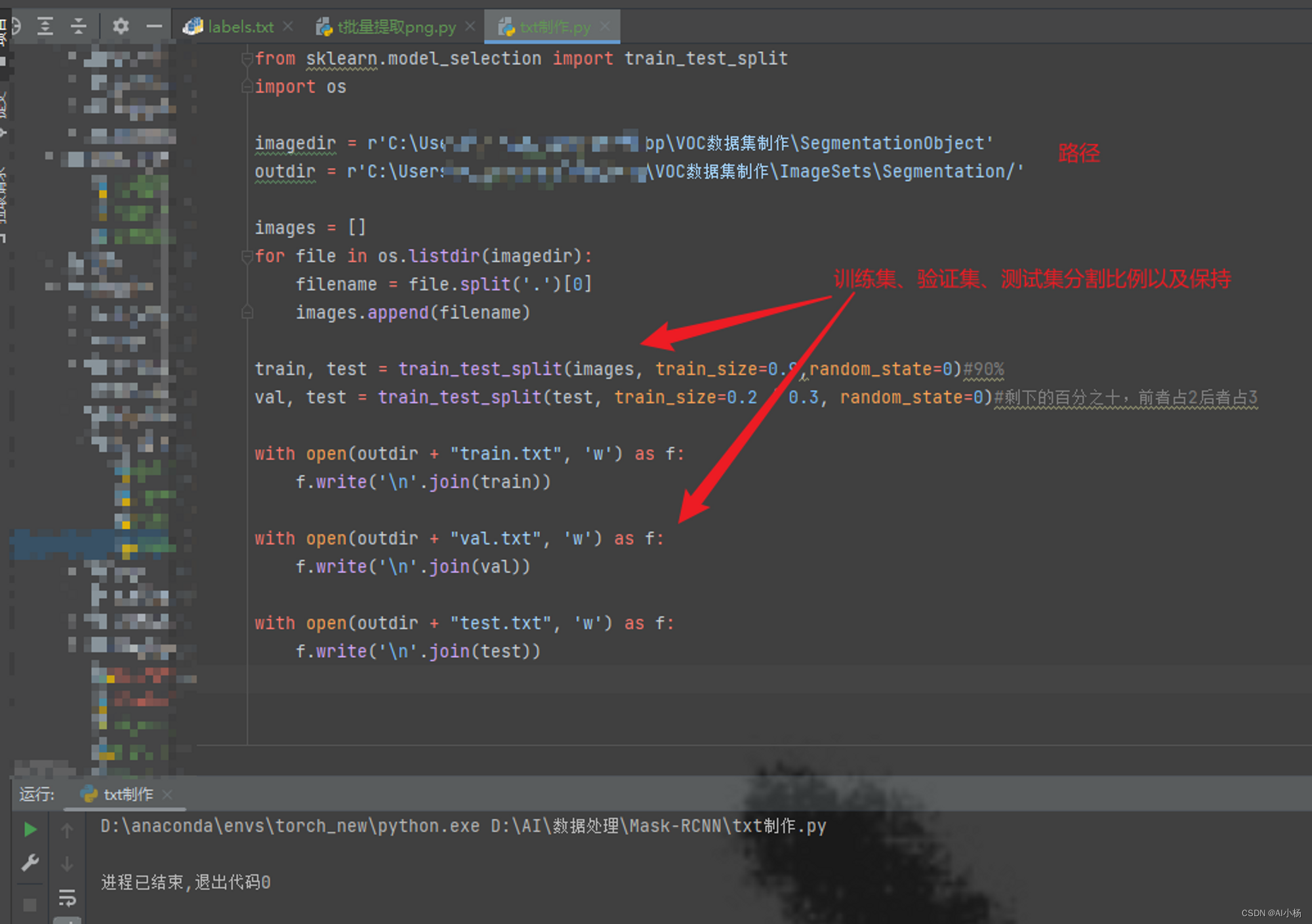
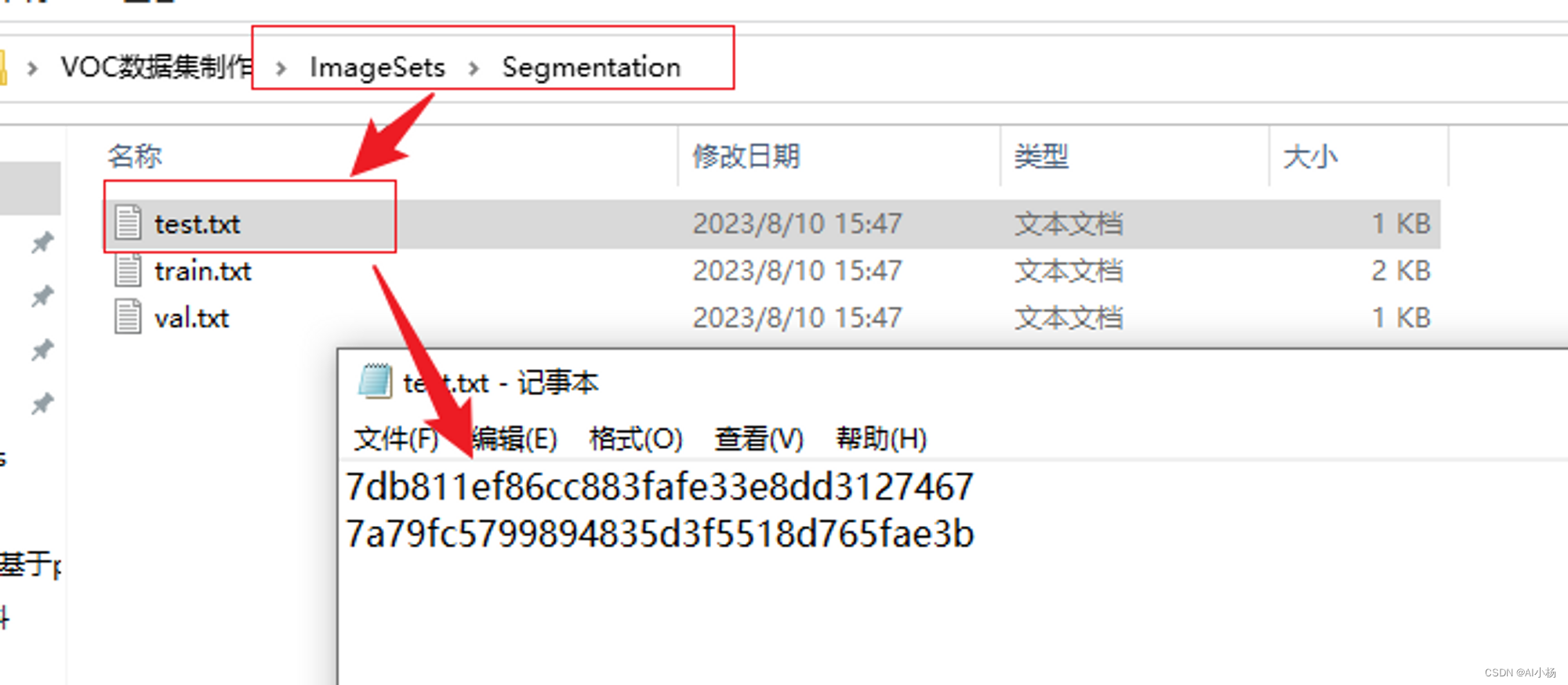
运行完成后该目录下就生成如下数据了:
至此,Mask_RCNN模型需要的标准的VOC数据集就制作完成了
针对Mask-RCNN的标准数据Mask-RCN源代码