“幸福感预测”Project报告
1 赛题简介
本赛题是天池上的一个数据挖掘类型的比赛——快来一起挖掘幸福感。比赛的数据使用的是官方的《中国综合社会调查(CGSS)》文件中的调查结果中的数据。其中,数据有139个维度的特征,其中包括个体变量(性别、年龄、地域、职业、健康、婚姻与政治面貌等等)、家庭变量(父母、配偶、子女、家庭资本等等)、社会态度(公平、信用、公共服务等等)特征。赛题要求使用以上的139个维度的信息,使用8000余组数据进行对于个人幸福感的预测(预测值为1,2,3,4,5,其中1代表幸福感最低,5代表幸福感最高)。
因为考虑到变量个数较多,部分变量间关系复杂,数据分为完整版和精简版两类。可从精简版入手熟悉赛题后,使用完整版挖掘更多信息。在这里我直接使用了完整版的数据。赛题也给出了index文件中包含每个变量对应的问卷题目,以及变量取值的含义;survey文件中为数据源的原版问卷,作为补充以方便理解问题背景。
最终的评价指标为均方误差MSE。
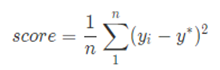
2 具体的比赛结果
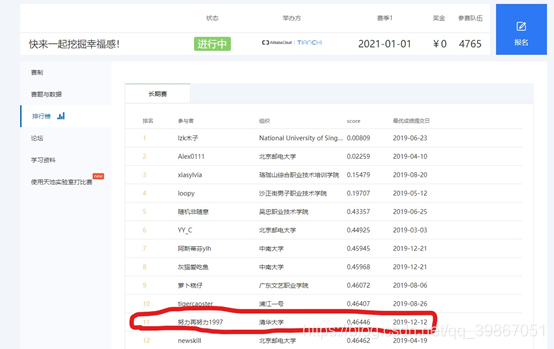
最终的比赛结果得分为0.46446,排名11/4765,百分比为0.231%。
3 数据预处理
3.1 初步处理
首先需要对于数据中的连续出现的负数值进行处理。由于数据中的负数值只有-1,-2,-3,-8这几种数值,所以我们将他们进行分别的操作,实现代码如下:
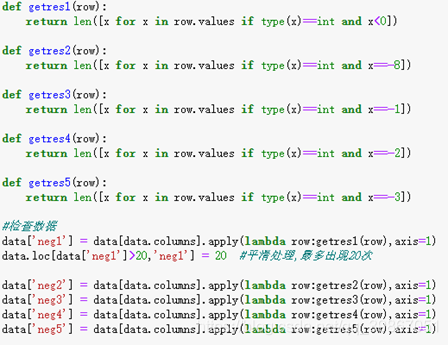
并最终将他们设置为negetive的特征,即最终不会再使用这些特征。
然后需要考虑数据样本中的缺失值,在这里我采取的方式是将缺失值补全,使用fillna(value),其中value的数值根据具体的情况来确定。例如将大部分缺失信息认为是零,将家庭成员数认为是1,将家庭收入这个特征认为是66265,即所有家庭的收入平均值。部分实现代码如下:

我们还应该删去有效样本数很少的特征,例如负值太多的特征或者是缺失值太多的特征,这里我一共删除了包括“目前的最高教育程度”在内的9类特征。
接下来就是最重要的特征提取与特征融合方面的工作了:首先要处理数据中明显不正确的信息,这里对于不同的数据采用了不同处理方式,有三种处理方式:方案一是使用众数(代码中使用mode()来实现),具体的代码参考如下:
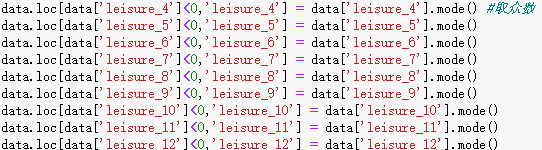
由于这里的特征是空闲活动,所以采用众数对于缺失值进行处理比较合理。方案二是取均值进行缺失值的补全(代码实现为means()),具体的代码参考如下:

在这里因为家庭的收入是连续值,所以不能再使用取众数的方法进行处理,这里就直接使用了均值进行缺失值的补全。第三种方法是使用我们日常生活中的真实情况,例如“宗教信息”特征为负数的认为是“不信仰宗教”,并认为“参加宗教活动的频率”为1,即没有参加过宗教活动,主观的进行补全,这也是我在这一步骤中使用最多的一种方式。具体的代码如下图:

就像我自己填表一样,这里我全部都使用了我自己的想法进行缺省值的补全。
采用以上的方法我一种处理了近50中特征,其中包括:宗教、教育程度、个人收入、政治面貌、体重处理、身高处理、健康等等近50种特征,使用上述的三种方法对其进行一一分析并补全。
除此之外,还有特殊格式的信息需要另外处理,比如与时间有关的信息,这里主要分为两部分进行处理:首先是将“连续”的年龄,进行分层处理,即划分年龄段,具体实现代码如下图:

在这里我们将年龄分为了6个区间。其次是计算具体的年龄,在Excel表格中,只有出生年月以及调查时间等信息,我们根据此计算出每一位调查者的真实年龄。具体实现代码如下:

3.2 数据增广
这一步,我们需要进一步分析每一个特征之间的关系,从而进行数据增广。经过思考,这里我添加了如下的特征:第一次结婚年龄、最近结婚年龄、是否再婚、配偶年龄、配偶年龄差、各种收入比(与配偶之间的收入比、十年后预期收入与现在收入之比等等)、收入与住房面积比(其中也包括10年后期望收入等等各种情况)、社会阶级(10年后的社会阶级、14年后的社会阶级等等)、悠闲指数、满意指数、信任指数等等。具体的实现代码如下:

除此之外,我还考虑了对于同一省、市、县进行了归一化。例如同一省市内的收入的平均值等以及一个个体相对于同省、市、县其他人的各个指标的情况。同时也考虑了对于同龄人之间的相互比较,即在同龄人中的收入情况、健康情况等等。具体的实现代码如下:

经过如上的操作后,最终我们的特征从一开始的131维,扩充为了263维的特征。接下来考虑特征工程、训练模型以及模型融合的工作。
4 特征工程与模型融合
在这里我首先使用lightGBM决策树进行特征重要性的判断,最终提取出排名前49位的特征,这里的49是由于第50重要的特征与第49重要的特征间出现了较大的断层,所以采用了前49中特征。具体的可视化图如下:

基于此,我这里构建了三种特征工程(训练数据集),其一是上面提取的最重要的49中特征,其中包括健康程度、社会阶级、在同龄人中的收入情况等等特征。其二是扩充后的263维特征(这里可以认为是初始特征)。其三是使用One-hot编码后的特征,这里要使用One-hot进行编码的原因在于,有部分特征为分离值,例如性别中男女,男为1,女为2,我们想使用One-hot将其变为男为0,女为1,来增强机器学习算法的鲁棒性能;再如民族这个特征,原本是1-56这56个数值,如果直接分类会让分类器的鲁棒性变差,所以使用One-hot编码将其变为6个特征进行非零即一的处理。
接下来,我继续使用了5中机器学习算法,并将folds设置为5,其中使用的算法包括:lightGBM、xgboost、RandomForestRegressor(随机森林回归)、GradientBoostingRegressor(梯度提升决策树)、ExtraTreesRegressor(极端随机森林)等。这里展示lightGBM算法在263个特征的数据下的实现代码:

其中在每一种特征工程种,进行5折的交叉验证,并重复两次(Kernel Ridge Regression,核脊回归),取得每一个特征数下的模型的结果。最终将三种特征工程再经过Kernel Ridge Regression进行融合得到最终的结果。模型融合的具体代码如下图:
得到最终的结果后,我继续对输出结果进行处理,由于最终的预测值应该为1,2,3,4,5这种分离值,而实际的预测结果为小数,所以这里尝试了使用将整数附近的小数使用整数来替代的处理方法。具体实现的代码如下图:

经过调参,最终的模型的结果如下表:
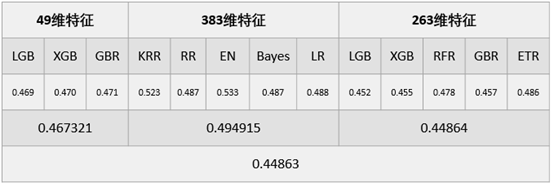
从上图的结果可以看出,经过模型融合的方法后的效果变好,而且对于使用原来的263维的特征的结果是三种特征工程中效果最好的。最终我认为出现这种结果的原因在于,可能与调参有关,另外我们一开始选取的49维的特征不一定是最重要的特征,因为这里的49维的特征是由263维的特征是经LGM算法得到的,有可能这种处理方法有误,不过经过提交后在线上的结果中,模型融合的效果是最优的,比仅仅使用263维的特征的得分要好很多。而且对于49维的特征的结果也要优于263维的特征所得到的结果。
5 结论与感想
相比较于CV的比赛,数据挖掘的比赛用时要小很多,而且相比于CV的题目大多时间用在深度网络训练中,数据挖掘的比赛大部分时间是用在特征工程中,而且总时间也相对要短很多。我一直觉得一开始的特征工程或者说数据预处理比最终的模型选择或许还要重要,所以在这个“幸福感预测”的比赛中,我也是花费了大量的时间,来考虑如何做一个完美的特征工程,如何挖掘到最优的特征。