循环神经网络或RNN是一类用于处理序列数据的神经网络。
展开计算图
考虑一个又外部信号
当前状态包含了整个过去序列的信息。
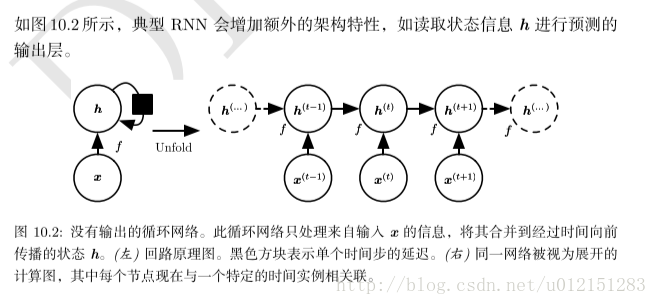
我们可以用一个函数
循环神经网络
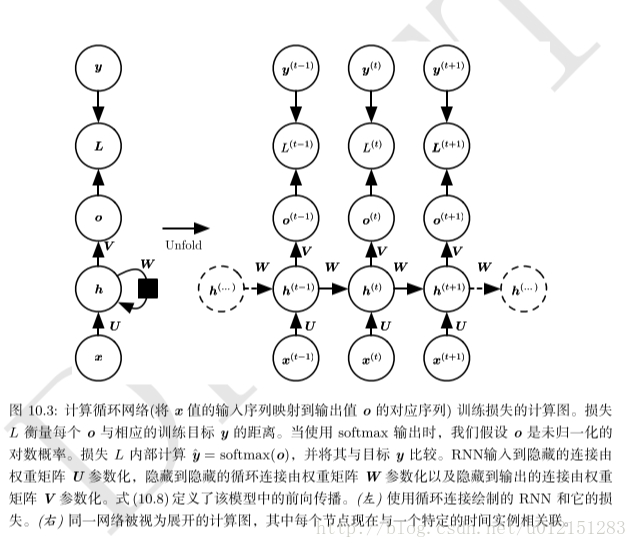
循环神经网络中一些重要的设计模式包括以下几种:
1. 每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络如图10.3。
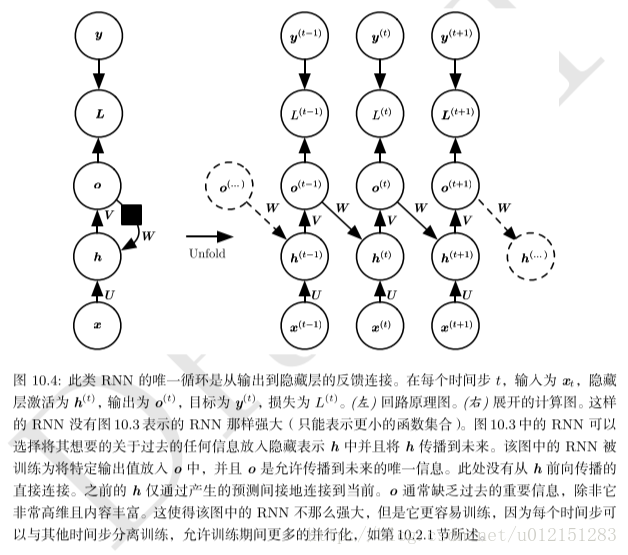
2. 每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络,如图10.4。
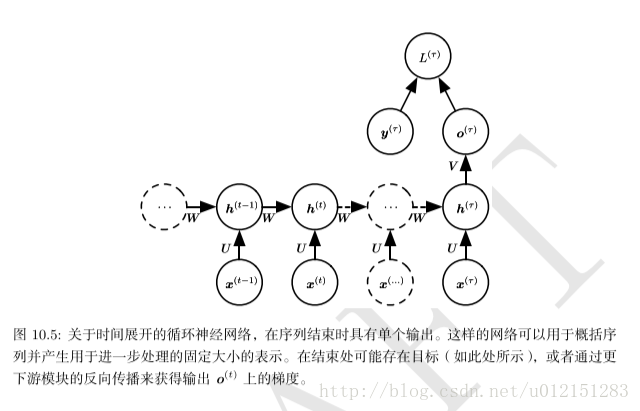
3. 隐藏单元之间存在循环连接,但读取整个序列后产生的单个输出的循环网络,如图10.5。
现在研究图10.3的RNN的前向传播公式。假设隐藏单元使用双曲正切激活函数。从
关于各个参数计算这个损失函数的梯度是计算成本很高的操作。梯度计算涉及执行一次前向传播,接着是由右到左的反向传播。运行时间是
基于上下文的RNN序列建模
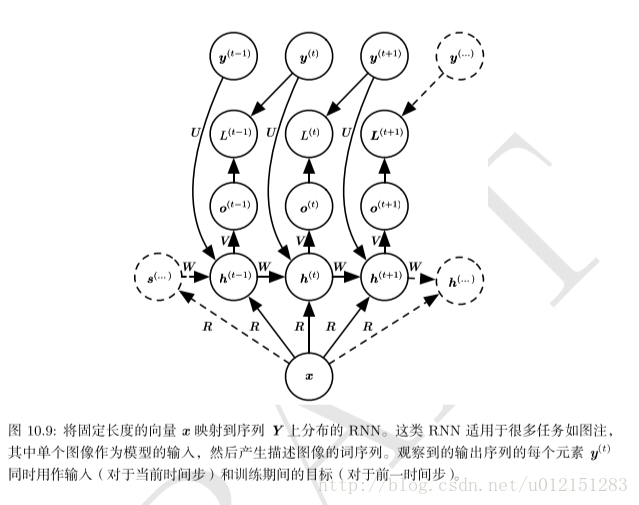
双向RNN
前面所说的神经网络都有一个“因果”结构,意味着在时刻t的状态只能从过去的序列
双向RNN满足了这种需要,他在需要双向信息的应用中非常成功,如手写识别,语音识别等。
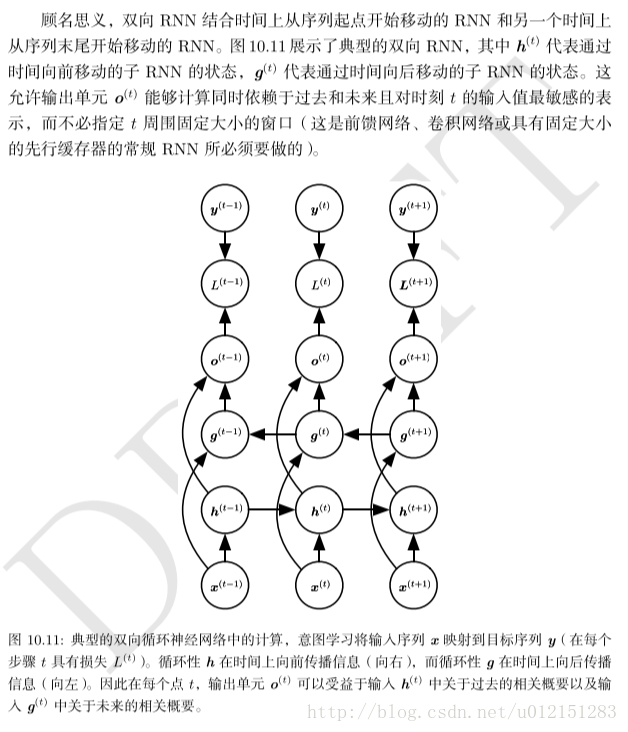
基于编码解码的序列到序列架构
现在介绍一种能够将输入序列映射到不一定等长的输出序列,这在许多场景都有应用,如语音识别,机器翻译或问答,其中训练集的输入和输出序列的长度通常不同。
架构特点如下
- 编码器处理输入序列,输出上下文C(通常是最终隐藏状态的简单函数)
- 解码器以固定长度的向量为条件产生输出序列。
编码器RNN的最后一个状态
此架构的一个明显不足是,编码器RNN输出的上下文C的维度太小而难以使当地概括一个长序列。通过让C称为可变长度的序列,而不是一个固定大小的向量解决。还可以引入将序列C的元素和输出序列的元素相关联的注意力机制。(attention)
递归神经网络
递归神经网轮被构造为深的树状结构而不是RNN的链状结构,因此是不同类型的计算图。
递归网络的一个明显优势是,对于具有相同长度
长期依赖的挑战
长期记忆和其他门控RNN
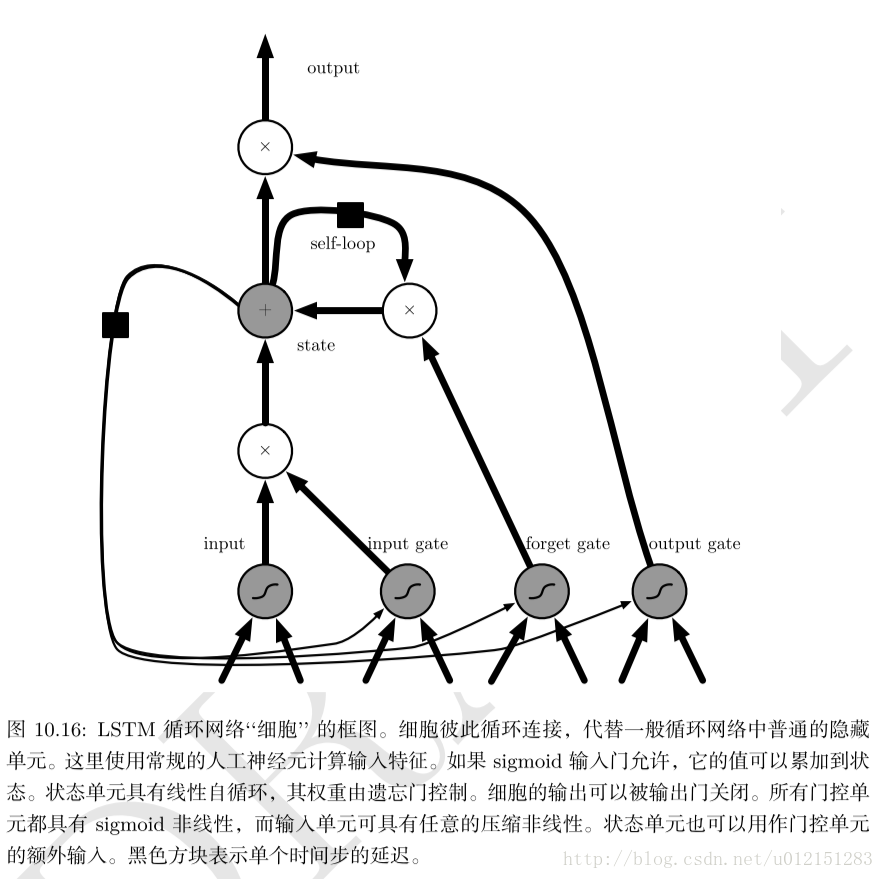
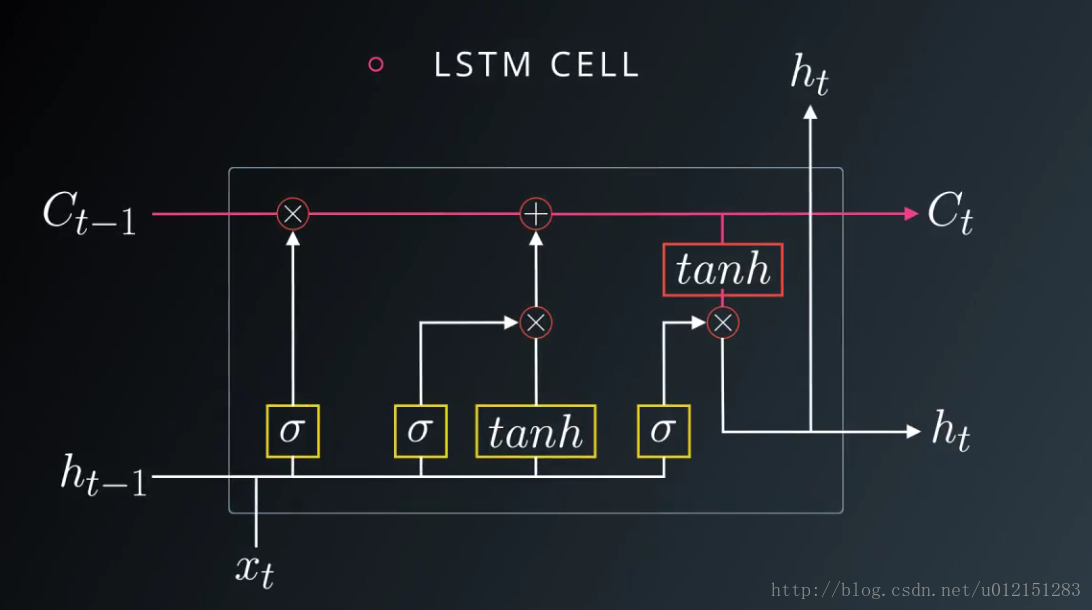
LSTM
引入自循环的巧妙构思,以产生梯度长时间持续流动的路径是初始LSTM模型的核心贡献。其中一个关键扩展是使自循环的权重视上下文而定,而不是固定的。门控此自循环(由另一个隐藏单元控制)的权重,累积的时间尺度可以动态地改变。
LSTM循环网络除了外部的RNN循环外,还具有内部的LSTM细胞循环(自环)。
GRU
GRU与LSTM主要区别是,单个门控单元同时控制遗忘因子和更新状态单元的决定。

优化长期依赖
截断梯度
梯度告诉我们,围绕当前参数的无穷小区域内最速下降的方向。
截断梯度(clipping the gradient)。
- 在参数更新之前,逐元素地截断小批量产生的参数梯度。
- 参数更新之前截断梯度g的范数
||g||
if||g||g>v←gv||g||
其中v是范数上届,g用来更新参数。因为所有参数的梯度被单个因子联合重整化,所以后一方法的优点是保证了每个步骤仍然是在梯度方向上的。
截断每小批量梯度范数不会改变单个小批量的梯度方向。然而,许多小批量使用范数截断梯度后的平均值不等于截断真实梯度(使用所有的实例所形成的梯度)的范数。
引导信息流的正则化

参考资料
《深度学习》第10章