一,蜂房的简介
1.APACHE HIVE TM
Apache Hive™数据仓库软件有助于使用SQL读取,编写和管理驻留在分布式存储中的大型数据集。可以将结构投影到已存储的数据中。提供了命令行工具和JDBC驱动程序以将用户连接到配置单元。
数据计算:MapReduce分布式计算,难度大
:hive使用sql语句,简化开发,减小学习成本
2.优缺点
- 操作接口采用SQL,简化开发,减少学习成本
- 避免手写的MapReduce程序
- 蜂巢执行延迟较高,适合场景大多对实时性不强的情况
- 能够处理大数据
- 支持自定义函数
- HQL的辩答能力有限
- 蜂巢效率低
3.hive的架构
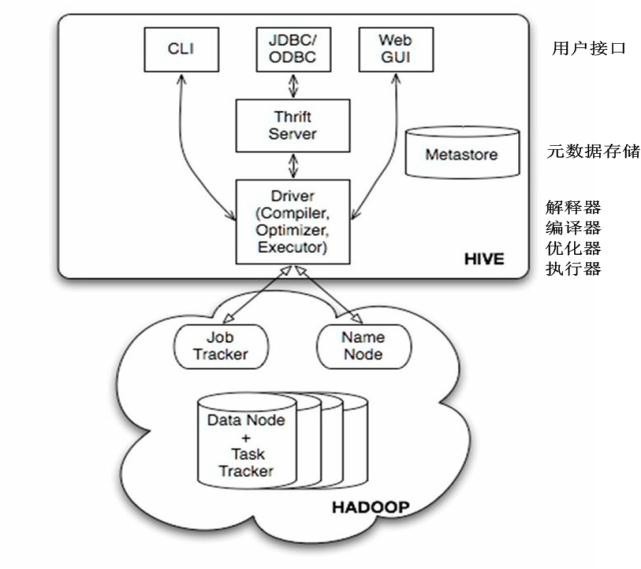
蜂巢提供了三种用户接口:CLI,HWI和客户端客户端是使用JDBC驱动通过节俭,远程操作Hive.HWI即提供的Web界面远程访问蜂巢但是最常见的使用方式还是使用CLI方式(在。 Linux的终端操作蜂巢)
蜂巢有三种安装方式:
1,内嵌模式(元数据保村在内嵌的德比种,允许一个会话链接,尝试多个会话链接时会报错,不适合开发环境)
2,本地模式(本地安装mysql替代derby存储元数据)
3,远程模式(远程安装mysql替代derby存储元数据)
二,配置单元的安装(在Linux的下)
1.安装MySQL
这个教程很详细:http://www.runoob.com/mysql/mysql-install.html
2.下载并解压
- 蜂巢:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2/下载apache-hive-1.2.2-bin.tar.gz
- tar -zxvf apache-hive-1.2.2-bin.tar.gz -C hd
3.进入Apache的蜂房1.2.2斌,进行配置
(1)。在Apache的蜂房1.2.2槽的名字重命名为蜂巢,便于后续操作)
mv apache-hive-1.2.2-bin hive
(2)将配置单元下的CONF下的蜂房env.sh.template重命名为hive-env.sh
mv hive-env.sh.template hive-env.sh
(3)然后进入CONF / hive-env.sh,进行编辑
找到这两行,取消注释符号,进行修改
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/root/hd/hadoop-2.8.4
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/root/hd/hive/confHADOOP_HOME =是你的hadoop文件包的路径(应为蜂巢是在hadoop的的基础之上的)
HIVE_CONF-DIR =是你蜂房的CONF的路径
(4)使用vi hive-site.xml,进入编辑模式,添加如下配置文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop04/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
<description>password to use against metastore database</description>
</property>
</configuration> <property>
<name> javax.jdo.option.ConnectionURL </ name>
<value> jdbc:mysql:// hadoop04 / metastore?createDatabaseIfNotExist = true </ value>
<description>用于JDBC Metastore的JDBC连接字符串</ description >
</ property
- 将上面复制进去,第一个要改的就是
这个配置是JDBC连接元存储,
第二和三要改的是连接数据库的用户名和密码,将对应的值改成相应的值即可。
然后保存退出。
(5)复制依赖包:cp mysql-connector-java-5.1.43-bin.jar hd / hive / lib /
这个文件在网盘:
链接:https://pan.baidu.com/s/1HlwE2RdP43kvy9Pls48LUg提取码:kxp6复制这段内容后打开百度网盘手机App,操作更方便哦
(6)配置环境变量
VI的/ etc / profilei /
export JAVA_HOME=/root/hd/jdk1.8.0_144
export HADOOP_HOME=/root/hd/hadoop-2.8.4
export ZOOKEEPER_HOME=/root/hd/zookeeper-3.4.10
export HIVE_HOME=/root/hd/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin(7)初始化元存储
schematool -dbType mysql -initSchema
(8)在蜂房下启动蜂巢
斌/蜂巢
成功的截图是这样的
[root@hadoop04 hive]# bin/hive
19/02/02 15:34:13 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist
Logging initialized using configuration in jar:file:/root/hd/hive/lib/hive-common-1.2.2.jar!/hive-log4j.properties
hive> show databases;
OK
default
Time taken: 1.432 seconds, Fetched: 1 row(s)然后就可以进行操作了