本系列是本人对Hive的学习进行一个整理,主要包括以下内容:
1.HiveQL学习笔记(一):Hive安装及Hadoop,Hive原理简介
2.HiveQL学习笔记(二):Hive基础语法与常用函数
3.HiveQL学习笔记(三):Hive表连接
4.HiveQL学习笔记(四):Hive窗口函数
5.HiveQL学习笔记(五):Hive练习题
接下来对第二个内容进行介绍。
Hive是基于Hadoop的数据仓库
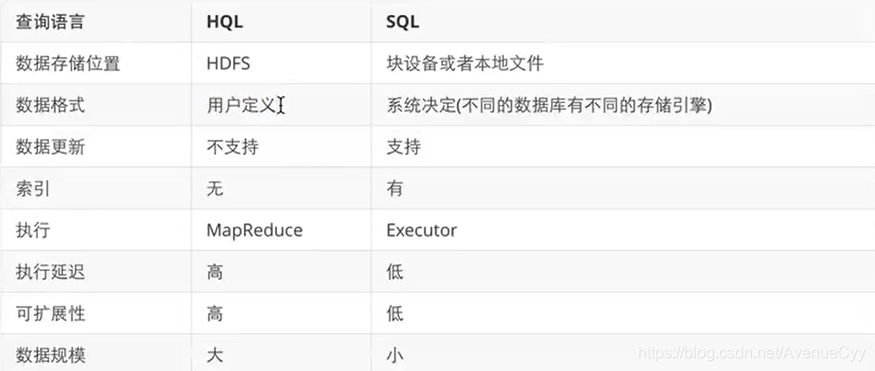
HiveQL与传统SQL对比:
基础语法
1.SELECT…A…FROM…B…WHERE…C…
这里放上SQL语法执行的先后顺序:
7:SELECT 查询列表
1:FROM 表
2:连接类型 JOIN 表2
3:ON 连接条件
4:WHERE 筛选条件
5:GROUP BY 分组
6:HAVING 分组后的筛选
8:ORDER BY 排序列表
9:LIMIT 偏移,条目数;

例子:

**注:**分区表必须用where限制分区字段。
2.GROUP BY
GROUP BY的作用:分类汇总
常用的聚合函数:

GROUP BY……HAVING
HAVING:对GROUP BY的对象进行筛选,仅返回符合HAVING的结果。
例子:

3.ORDER BY
ORDER BY的作用:按字段排序

例子:

注:
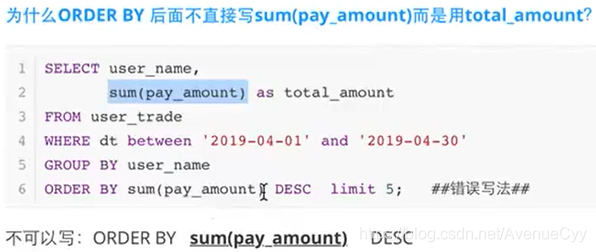
ORDER BY的执行顺序在SELECT之后,需要使用重新定义的列名进行排序。
- order by : 全排序!
- sort by : 部分排序! 需要先设置reducetask个数
set mapreduce.job.reduces=3 - distribute by : 分区,分区需要和sort by结合使用!
设置reducetask个数和数据的分区数一直! - cluster by : 当分区字段和排序字段一致时,可以简写!不能指定排序方式!
4.常用函数
函数分类:
- UDF : 一进一出,传入单个参数,返回一个结果!
- UDAF : 聚集函数,多进一出
- UDTF : 一(集合)进多出
1.时间函数
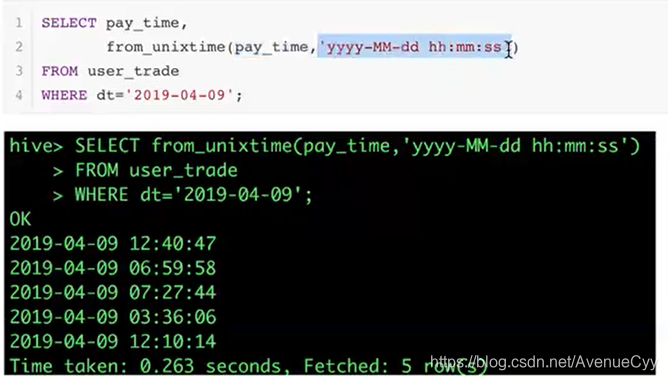
1.时间戳转化为日期:
from_unixtime()

例子:
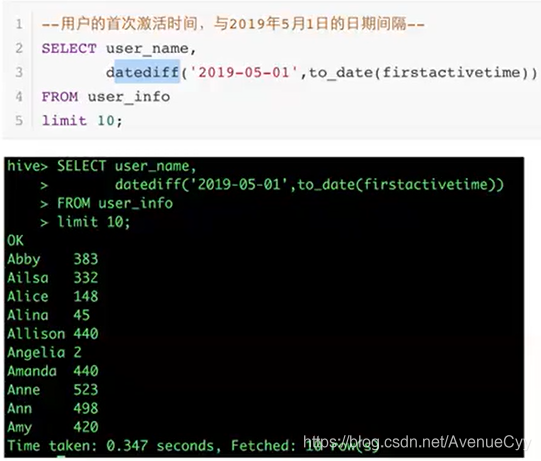
2.计算日期间隔
datediff()
例子:
2.条件函数
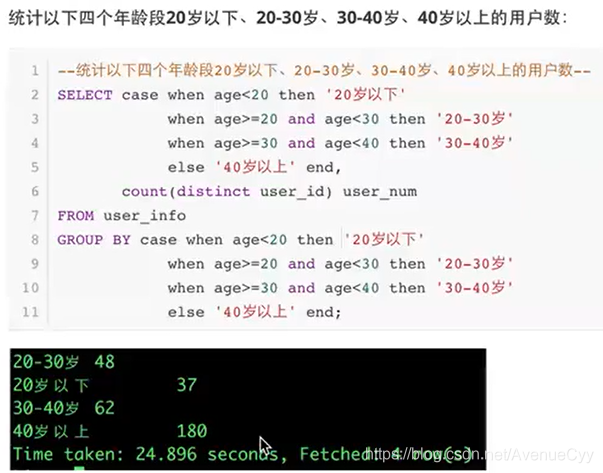
1.case when
例子:
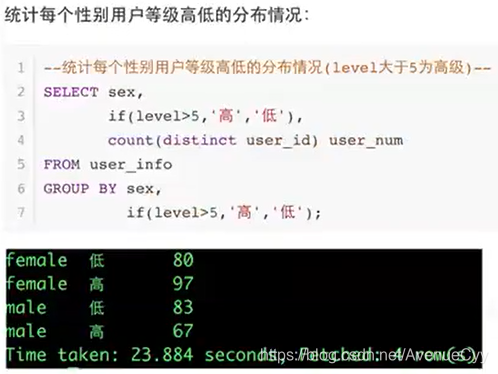
2.if
例子:
3.字符串函数
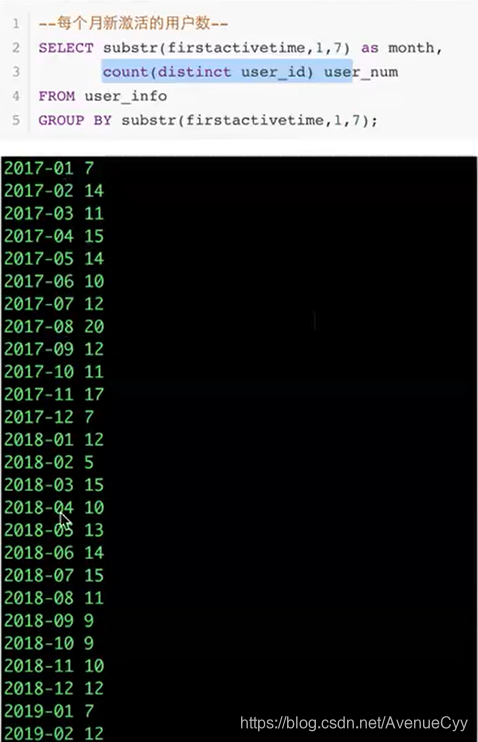
substr()

从1开始。
例子:
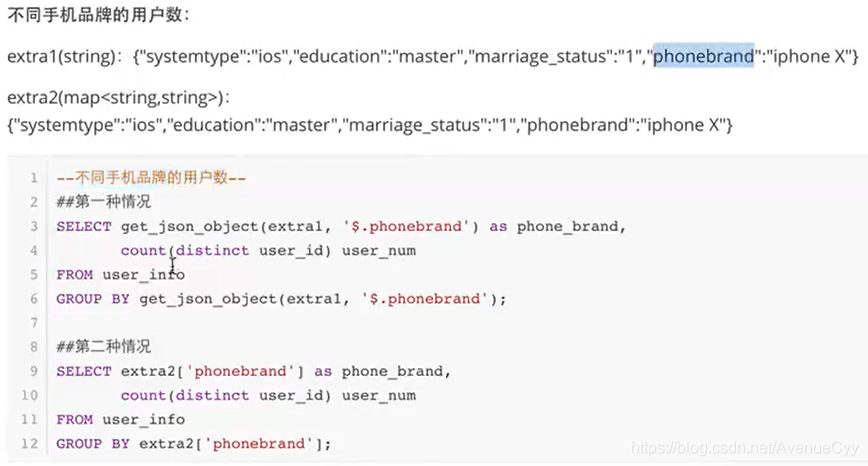
不同数据存储形式的提取方式。string和map。
#1.string
get_json_object()
#2.map
extra2[]
#利用[]直接提取value

4.聚合统计函数
即ORDER BY中介绍的函数。
注:不许嵌套avg(count(*))

5.其他函数
1.nvl
NVL:给值为NULL的数据赋值,它的格式是NVL( string1, replace_with)。
它的功能是如果string1为NULL,则NVL函数返回replace_with的值,否则返回string1的值,如果两个参数都为NULL ,则返回NULL。
#如果员工的comm为NULL,则用-1代替
select nvl(comm,-1) from emp;
2.行转列
行转列: 一列多行变一列一行
相关函数:
-
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
-
CONCAT_WS(separator, str1, str2,…):它是一个特殊形式的 CONCAT()。separator是分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。如果不是 NULL分隔符将被加到被连接的字符串之间;
-
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。

select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;

3.列转行
列转行:一列一行变一列多行
相关函数:
- EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
- LATERAL VIEW
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。

select
movie,
category_name
from
movie_info lateral view explode(category) table_tmp as category_name;

4.coalesce
若expression_1中有NULL值,则用expression_2对应的非NULL值进行填充;
若expression_1和expression_2中都存在NULL值,则用后面的expression_3进行填充,依次递推。

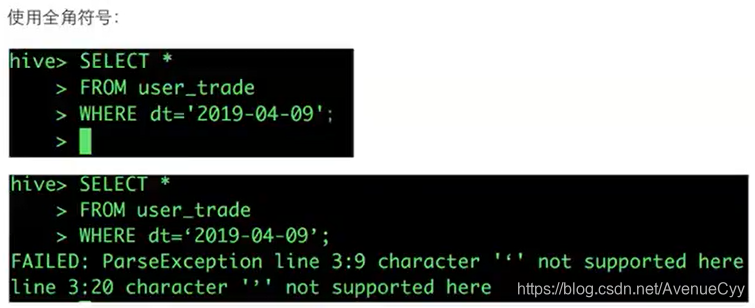
5常见错误及处理方法
1.标点符号错误
2.没有对子查询的表进行重命名

3.使用错误的字段名

4.丢了逗号分隔符
