faster RCNN简介
- faster rcnn属于两阶段目标检测,所谓两阶段目标检测,指的就是对检测框做两次边框回归,首先使用RPN网络,生成anchor,挑选出positive anchors,并对这些anchor进行第一次回归,再经过nms,得到初步的proposal;在RCNN阶段,对于这些proposal,提取对应区域的feature map,并使用RoiAlign或者RoiPooling等方法,将这些proposal变成统一的大小(否则之后没法接FC等层了),经过各种卷积或者fc操作之后,对proposal进行再一次地回归。整个过程回归了2次边框,因此是两阶段的目标检测。
- 关于faster rcnn更加具体的解释可以参考这篇知乎文章:https://zhuanlan.zhihu.com/p/31426458
ancho generator分析
- 训练时,在RPN中,使用anchor generation的方法生成anchor,但是在这个过程中,由于生成了大量的anchor,因此会有非常严重的正负样本不均衡的问题,怎样保证生成anchor与gt bbox有尽可能大的IOU,其实是非常重要的问题,在FPN中,短边800训练时,常规的RP配置如下。
FPNRPNHead:
anchor_generator:
anchor_sizes: [32, 64, 128, 256, 512]
aspect_ratios: [0.5, 1.0, 2.0]
stride: [16.0, 16.0]
variance: [1.0, 1.0, 1.0, 1.0]
anchor_start_size: 32
max_level: 6
min_level: 2
num_chan: 256
在移动端如果希望能够跑两阶段目标检测,那么一般都是需要减少输入图像的尺度的,但是这时候,如果使用原始的anchor size,则可能会导致anchor的[email protected](iou)太低。这样有3个主要问题
- 一方面进一步增加了目标检测的正负样本
- 另一方面也增加了网络学习的难度(召回的anchor不够多,网络需要学习更多的偏移量)。
- 不同大小的anchor在不同anchor size的情况下,召回也是不同的(如果anchor size很大的话,则大物体的召回情况会改善,但是这会带来大小物体召回不平衡的问题)。
因此,需要对anchor size进行一些调整,否则难以召回。
anchor start size修改
在320x320下,分析了anchor_start_size对召回的影响,默认32和修改为16之后的情况下,召回如下,
| anchor start size | 训练尺度 | [email protected] for small | [email protected] for medium | [email protected] for large |
|---|---|---|---|---|
| 32 | 320x320 | 0.814 | 18.371 | 23.069 |
| 16 | 320x320 | 2.468 | 4.960 | 5.627 |
上面可以看出,训练尺度为320x320anchor start size=32时,大小anchor的召回差距较大,这带来了不平衡的问题,而使用16的时候,不同尺度的anchor召回比较平衡,基于mobilenetv3模型,实验证明,32->16的改进,可以直接带来1.7%的coco mAP提升。
FPN level修改
- 检测中默认的backbone一般都是
C2~C5,FPN输出P2~P6,而这其实会带来很大的计算量,如果通过减少backbone stage的方式(如C2~C4,FPN输出P2~P4)这可以减少计算量,但是又会带来召回不足的问题。分析不FPN leve情况下的召回,具体信息如下。 - 注意:在这里,anchor start size均为16。
| FPN level | 训练尺度 | [email protected] for small | [email protected] for medium | [email protected] for large |
|---|---|---|---|---|
| P2~P4 | 320x320 | 2.468 | 4.928 | 1.922 |
| P2~P5 | 320x320 | 2.468 | 4.960 | 4.952 |
| P2~P6 | 320x320 | 2.468 | 4.960 | 5.627 |
由上面可以看出,其实P2~P6的FPN level还是非常有意义的,很大程度上提升了大物体的anchor阶段的召回情况。那既然直接使用backbone生成feature map很耗时,我们完全可以使用降采样卷积的方式生成更多的FPN feature map,这样在计算量很小的情况下,也可以保证anchor generator的正常运行。
下面可视化了P2~P4作为FPN feature map时的召回情况.

下面可视化了P2~P6作为FPN feature map时的召回情况。

其中,绿色框是可以被召回的anchor,红色框是gt bbox,很明显可以看出,更多的FPN level带来了更多可以用于回归的正样本。
使用P2~P6相比于P2~P4,coco mAP涨了1.3%。特别需要注意的是,大物体的mAP涨了2.5%,这个也验证了之前我们的分析结论。
实现
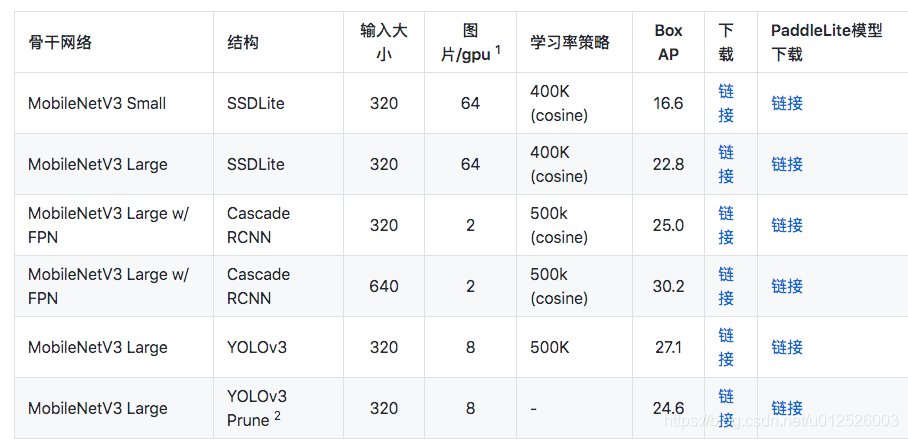
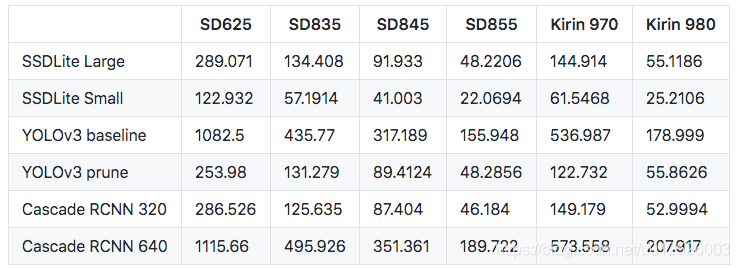
PaddleDetection中基于该种思路,提供了移动端的实用目标检测算法,COCO mAP可以达到25.0%,速度和精度都是可以与YOLO与SSD匹敌的。下面给出了精度和预测速度的情况,更加具体的可以参考PaddleDetection的github地址:https://github.com/PaddlePaddle/PaddleDetection/blob/master/configs/mobile/README.md