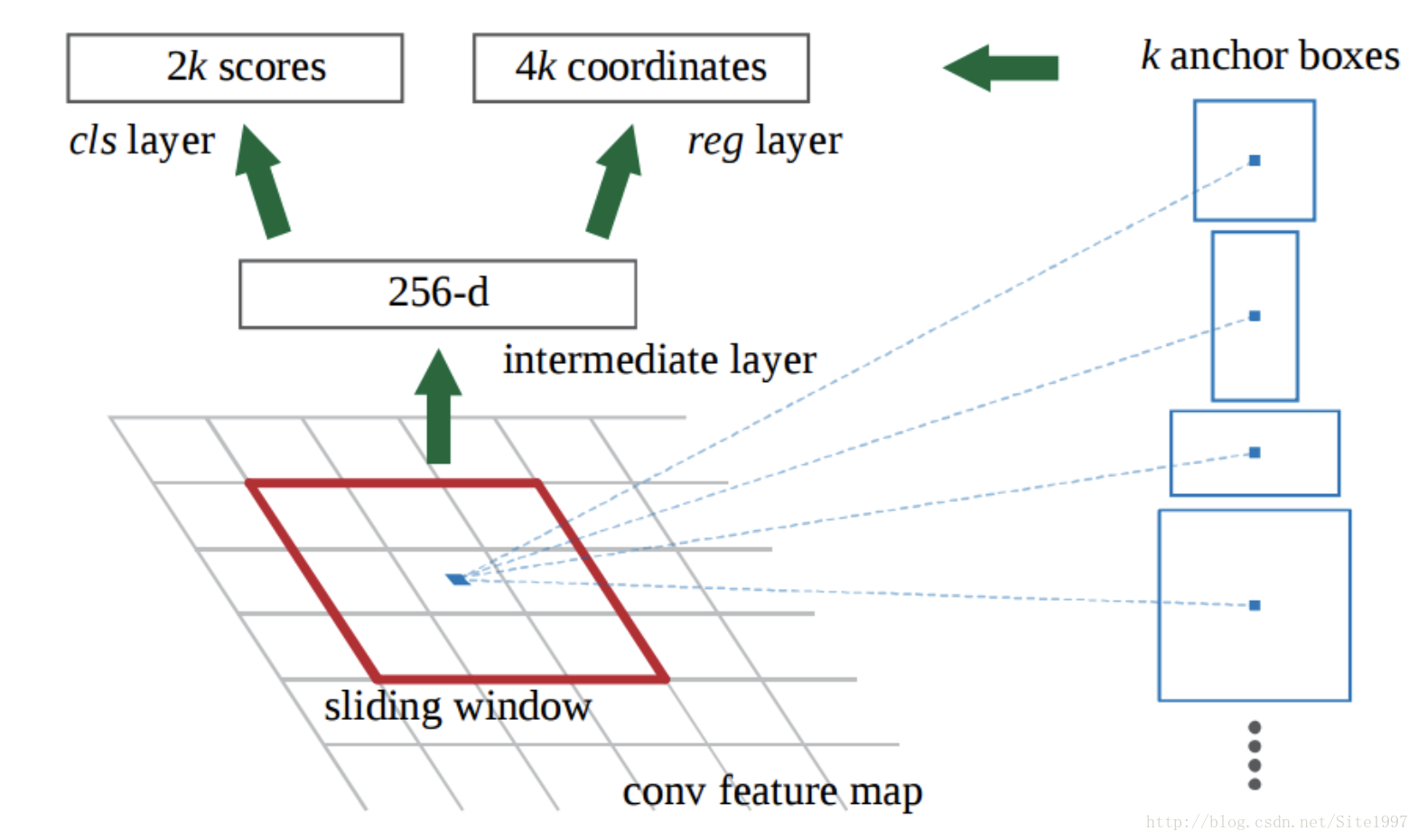
首先,RPN是怎么选出候选区域的?见上面示意图。在VGG网络提取整个特征图像后,我们使用一个3*3的滑窗在这个图像上滑动,对于每一个位置,我们同时预测k个不同region proposals,所以左上角的分类层含有2k个输出(表明是否为物体的概率),右上角的边框回归层有4k个输出(表示region的坐标到groundtruth的坐标的四个矫正量)。其中,这k个proposals分别对应原图中k个框框里面object的大致位置。
其次,为什么一个卷积出来的256-d向量能对应k个anchors?个人理解,anchor boxes的size是我们人为固定好了的(anchor boxes的大小对应的是原图像的,它中心点是原图像上anchor boxes的中心点,对应到示意图里就是那个蓝点点),但是实际上神经网络中并没有把这k个anchor boxed坐标当做神经网络里的参数。而是,神经网络在训练的过程中,每个anchor会根据它对应的k个boxes学出4*k个坐标矫正量(坐标矫正量是根据,“anchor对应的anchor boxes的坐标与物体的groundtruth的坐标,这二者的偏差量”得到的loss来学习)。(如果理解有误,还望在评论中批评指出,谢谢!)
