最近在跑py-faster-rcnn的代码,终于大概弄懂了结构
caffe的可视化网页为指路
前期得到feature maps的方法结构主要有ZF和VGG16两种,ZF结构较小,VGG16较大,精度差不多,所以选择占显存小的ZF。两者的区别是conv层不同。
faster rcnn由三部分构成:特征提取+RPN+ROI Pooling+Classifier

本文以ZF为特征提取网络讲解。
参考:链接
1)、Conv layers提取特征图:
作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取input image的feature maps,该feature maps会用于后续的RPN层和全连接层
2)、RPN(Region Proposal Networks):
RPN网络主要用于生成region proposals,首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
3)、Roi Pooling:
该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位
4)、Classifier:
会将Roi Pooling层形成固定大小的feature map进行全连接操作,利用Softmax进行具体类别的分类,同时,利用L1 Loss完成bounding box regression回归操作获得物体的精确位置.
rpn网络:
用来生成检测框
参考:https://zhuanlan.zhihu.com/p/31426458
参考:https://www.cnblogs.com/houkai/p/6824455.html

- rpn_conv/3*3
将卷积得到的feature maps做3*3的卷积
2. rpn_cls_score_reshape
是一个reshape,caffe中的blob结构为[batch_size,channel,height,width],为了二分类,存储形式为[batch_size,2,9*height,width]
3.rpn_cls_prob
是softmax,用来分类fg和bg
4. rpn_cls_prob_reshape
是一个reshape, 这个reshape为了保存anchors,在feature maps上的每个点有9个anchors,且每个分为fg和bg,所以为了保存fg、bg的anchors,它的储存形式为[batch_size,2*9,height,width]
5.rpn_bbox_pred
是一个1*1卷积,输出维度为36,它的存储形式为[1,4*9,h,w],9个anchors,每个有4个算出来的变量,对应bounding box和gt的回归。
6.proposal
综合所有的4个变换量和fg anchors,按照im_info的信息,将图像大小映射到原图大学,计算出proposals送给ROI。
- 再次生成anchors,并对所有的anchors做bbox reg位置回归(注意这里的anchors生成顺序和之前是即完全一致的)
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors。即提取修正位置后的foreground anchors
- 利用feat_stride和im_info将anchors映射回原图,判断fg anchors是否大范围超过边界,剔除严重超出边界fg anchors。
- 进行nms(nonmaximum suppression,非极大值抑制)
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
补充:
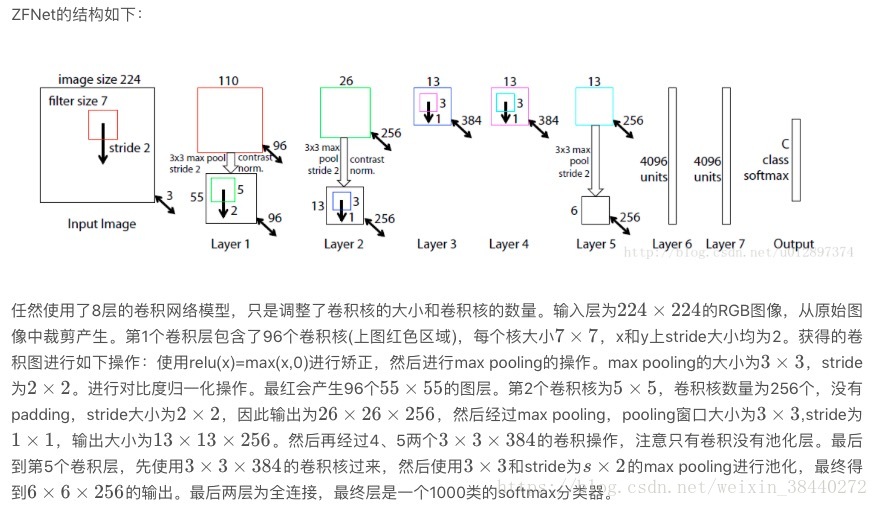
1.权值共享:
权值共享就是同一个Feature Map中神经元权值共享,该Feature Map中的所有神经元使用同一组权值
参考:https://blog.csdn.net/denghecsdn/article/details/77848246
2.pooling层作用
对输入的特征图进行压缩。
- 使特征图变小,简化网络计算复杂度
- 进行特征压缩,提取主要特征
pooling操作使特征图变小,可能影响网络准确度,因此可以通过增加特征图的深度来弥补
3.卷积层作用
用来提取特征。使用多层次的卷积可以得到更深层次的特征。在CNN中比较重要的是权值共享,每个filter上的每个channel是共享的
4.LRN层作用
局部响应归一化层。一般是在激活后进行的一种操作。
LRN仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制)
好处有以下两点:
- 归一化有助于快速收敛
- 对局部神经元的活动创建竞争机制,是的其中响应比较大的值变得更大,并抑制相对响应较小的神经元,增强了模型泛化能力
5.filter
是感受野
6.feature map计算方法:
在CNN网络中roi从原图映射到feature map中的计算方法:
INPUT为32*32,filter的大小即kernel size为5*5,stride = 1,pading=0,卷积后得到的feature maps边长的计算公式是:
output_h =(originalSize_h+padding*2-kernelSize_h)/stride +1
所以,卷积层的feature map的变长为:conv1_h=(32-5)/1 + 1 = 28
卷积层的feature maps尺寸为28*28.
由于同一feature map共享权值,所以总共有6*(5*5+1)=156个参数。
卷积层之后是pooling层,也叫下采样层或子采样层(subsampling)。它是利用图像局部相关性的原理,对图像进行子抽样,这样在保留有用信息的同时可以减少数据处理量。pooling层不会减少feature maps的数量,只会缩减其尺寸。常用的pooling方法有两种,一种是取最大值,一种是取平均值。
pooling过程是非重叠的,S2中的每个点对应C1中2*2的区域(也叫感受野),也就是说kernelSize=2,stride=2,所以pool1_h = (onv1_h - kernelSize_h)/stride +1 = (28-2)/2+1=14。pooling后的feature map尺寸为14*14.
fast rcnn以及faster rcnn做检测任务的时候,涉及到从图像的roi区域到feature map中roi的映射,然后再进行roi_pooling之类的操作。
比如图像的大小是(600,800),在经过一系列的卷积以及pooling操作之后在某一个层中得到的feature map大小是(38,50),那么在原图中roi是(30,40,200,400),
在feature map中对应的roi区域应该是
roi_start_w = round(30 * spatial_scale);
roi_start_h = round(40 * spatial_scale);
roi_end_w = round(200 * spatial_scale);
roi_end_h = round(400 * spatial_scale);
其中spatial_scale的计算方式是spatial_scale=round(38/600)=round(50/800)=0.0625,所以在feature map中的roi区域[roi_start_w,roi_start_h,roi_end_w,roi_end_h]=[2,3,13,25];
具体的代码可以参见caffe中roi_pooling_layer.cpp
6.ROI Pooling 和 ROI Align
参考:链接