一、简介Yolo
Yolo是一个实时目标检测,全称 You only look once。在Pascal Titan X处理图片可达30FPS,在COCO目标检测测试指标 平均准确度mAP达到 57.9%。
演示视频:
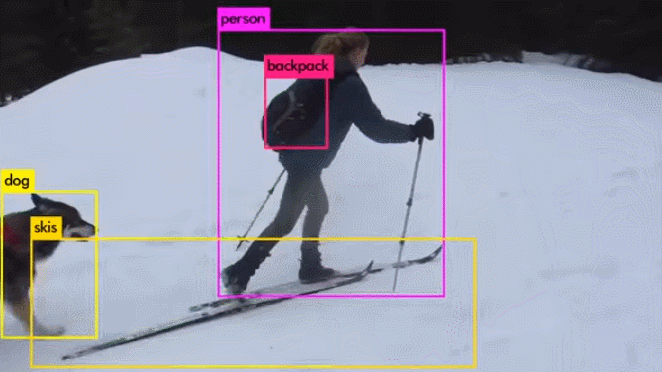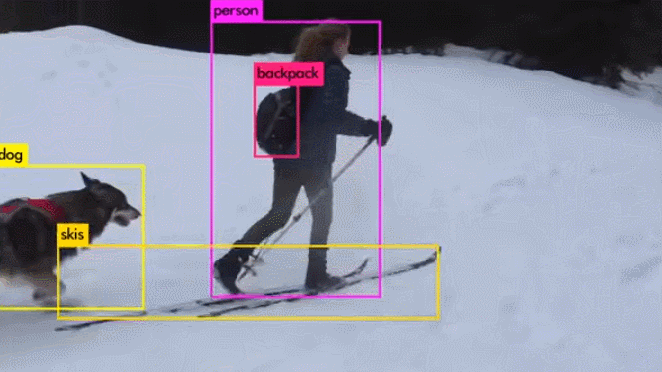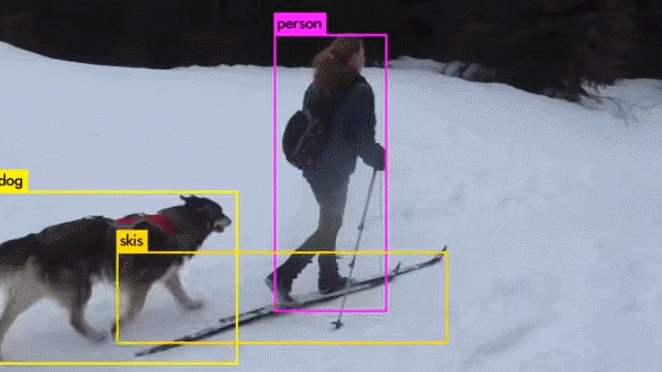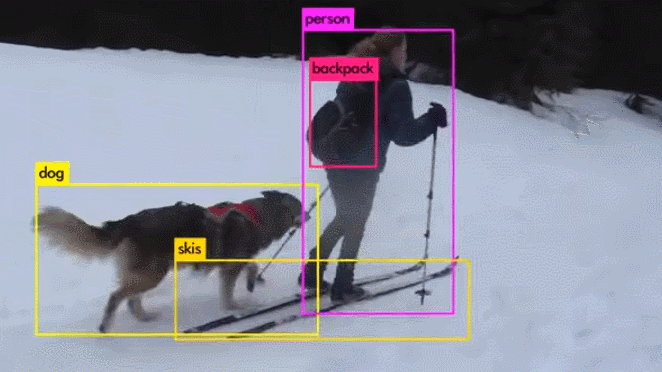
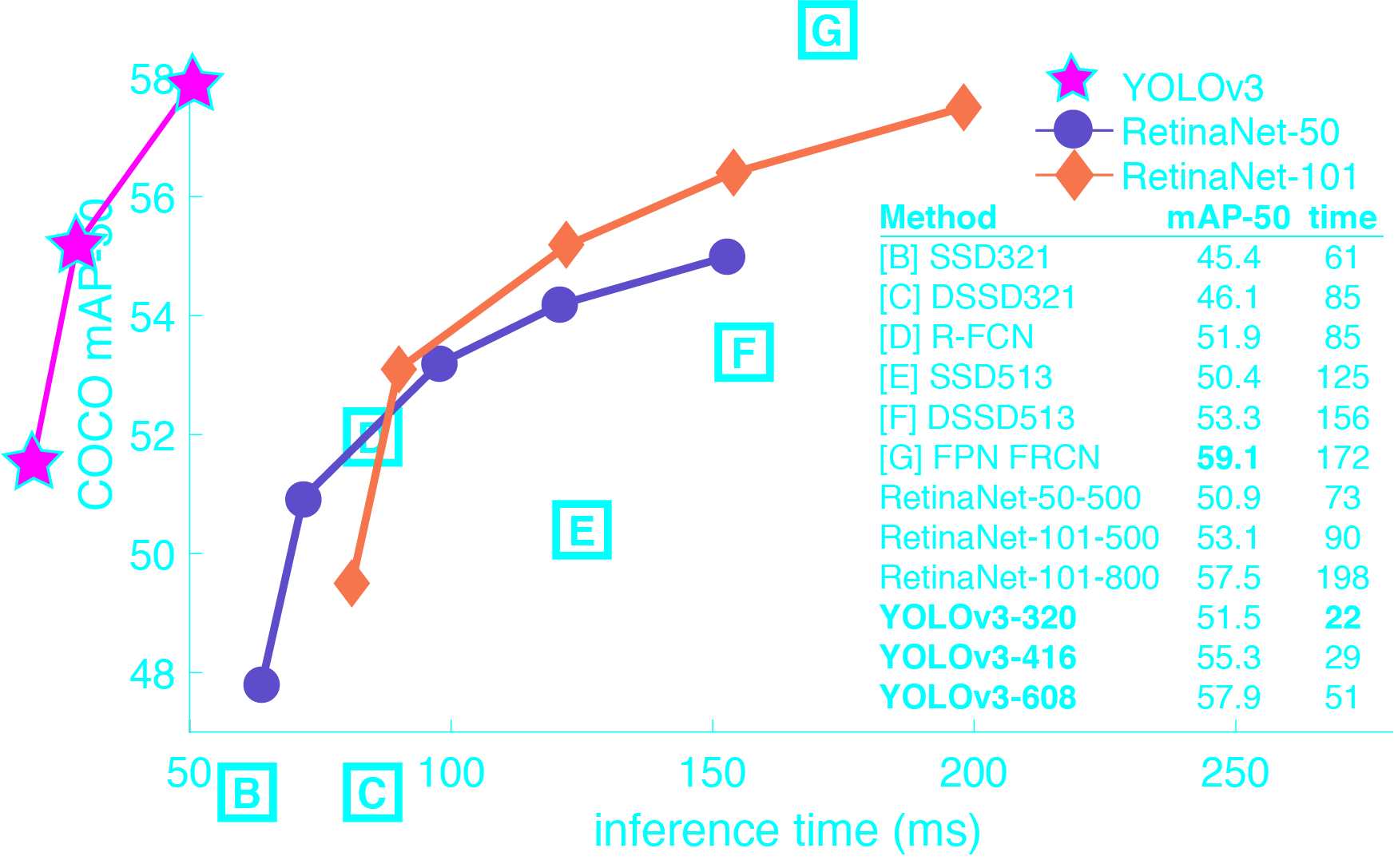
与其它目标检测算法的比较:
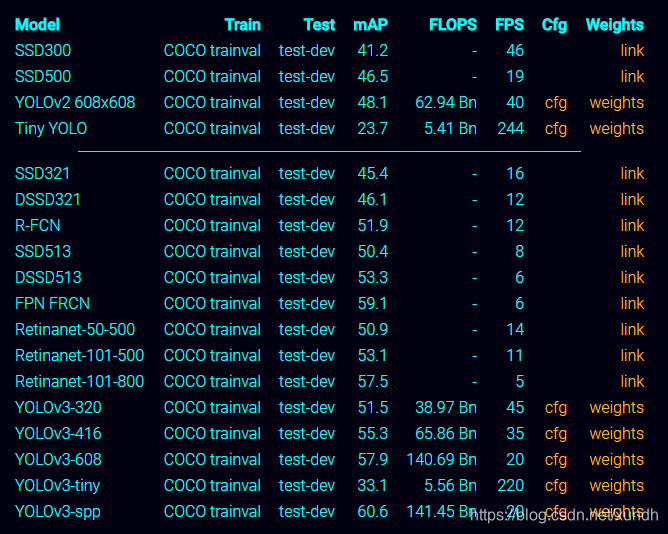
在COCO数据集上的表现:
实现原理
从R-CNN到FasterR-CNN利用分类器或定位器来执行检测,将模型用于多个位置和比例,高分值的区域作为检测区域。
YoloV3使用了不同的策略,将单一的神经网络应用于整个图片。神经网络将图片分成若干区域,对每个区域进行预测和评分。边界框由预测的概率值加权而来。
与基于分类器的系统相比,Yolo模型有几个优点:它在测试整个图像,因此它的预测可以感知整个图像区域;它用单一的网络评估来预测,不像R-CNN这样的系统需要数千张单一的图像。这使得它非常快,比R-CNN快1000倍,比Faster R-CNN快100倍。
YoloV3 使用了一些技巧来改进训练和提高性能,包括:多尺度预测、更好的分类器等。
https://pjreddie.com/darknet/yolo/
https://www.bilibili.com/video/av38639970/
https://machinelearningmastery.com/how-to-perform-object-detection-with-yolov3-in-keras/
https://github.com/calmisential/YOLOv3_TensorFlow2
https://github.com/zzh8829/yolov3-tf2
https://github.com/syou2020/tensorflow2.0-yolo3
二、下载官方程序运行测试
1. 基本使用
git clone https://github.com/pjreddie/darknet
cd darknet
make
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
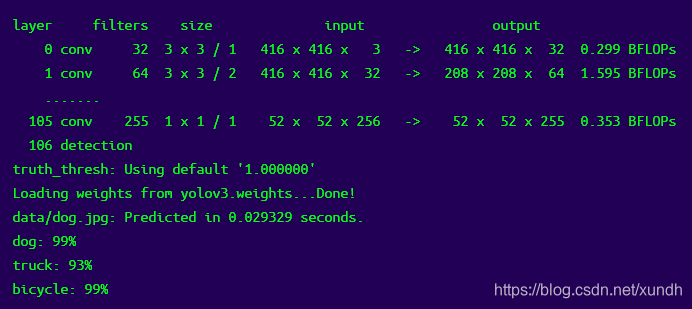
darknet程序没有显示图片功能,图片生成在predictions.png,可以手工打开查看:

2. 其它命令:
# detect是命令的缩写,完整写法:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
# 检测多个图片,手工挨个输入图片地址
./darknet detect cfg/yolov3.cfg yolov3.weights
# 改变测试阈值
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
3. yolov3有个精简版的模型:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
4. 使用摄像头
需要使用OpenCV和CUDA重新编译Darknet。编译时修改Makefile文件,将下面内容修改:
GPU=1
OPENCV=1
官方文档位置:https://pjreddie.com/darknet/install/#cuda
执行检测命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
对一个视频文件进行测试
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
5. 训练VOC数据集
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛, PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。很多模型都基于此数据集推出.比如目标检测领域的yolo,ssd等等。
训练的过程在这里大致写一些,本文内容来自官网,下面代码未测试。
# 获取数据集
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
ls
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tar
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
修改cfg/voc.data,把path-to-voc改为自己的VOC数据集地址
1 classes= 20
2 train = <path-to-voc>/train.txt
3 valid = <path-to-voc>2007_test.txt
4 names = data/voc.names
5 backup = backup
下载预训练权重
wget https://pjreddie.com/media/files/darknet53.conv.74
训练模型
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
6. 训练COCO数据集
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
修改cfg/coco.data,把path-to-coco改为自己的coco数据集地址。
1 classes= 80
2 train = <path-to-coco>/trainvalno5k.txt
3 valid = <path-to-coco>/5k.txt
4 names = data/coco.names
5 backup = backup
修改cfg/yolo.cfg:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
....
训练:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
可以在多个GPU上执行:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
7. 训练OpenImages数据集
wget https://pjreddie.com/media/files/yolov3-openimages.weights
./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
Yolov3版权信息:
@article{yolov3,
title={YOLOv3: An Incremental Improvement},
author={Redmon, Joseph and Farhadi, Ali},
journal = {arXiv},
year={2018}
}