
图片来自Unsplash上的Dave
0.本教程包含以下内容
特征分解
对称矩阵的特征分解
奇异值分解(The Singular Value Decomposition,SVD)
主成分分析(Principal Component Analysis ,PCA)——特征提取
1.特征分解
首先,我们简单回顾下特征值和特征向量的定义。在几何学中,矩阵A的特征向量是指一个经过与矩阵A变换后方向保持不变的向量(其中,假设特征值均为实数)。而特征值为在这个变化中特征向量的比例因子。具体可表示如下:

矩阵A与特征向量x的变换等于特征向量x与特征值λ的乘积
对于一个3×3维的矩阵A,我们可以将矩阵A与其特征向量x的变换理解为将矩阵A与另一个矩阵x的乘积。这是因为矩阵A与其特征向量x的变换等同于矩阵A的每一行与特征向量x的变换,从而矩阵之间的乘积可以表示为其特征值与特征向量的乘积。此时我们便能够分离出矩阵的特征值和特征值向量,并将其放在两个矩阵之中。具体过程如下:

通过上面等式,我们可以推出以下等式:
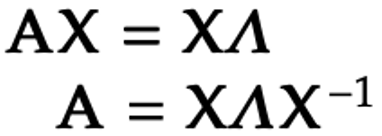
如果一个n×n维矩阵的n个特征向量均是线性无关的,则这个矩阵能够被对角化
观察上式,我们能够看到一个n×n维的矩阵可以由三个独立的矩阵构成,即一个由特征向量组成的n×n维的矩阵X和矩阵X的逆,以及一个由特征值组成的n×n维的对角矩阵Λ。而这个过程也被称为矩阵的特征分解。
2.对称矩阵的特征分解
对称矩阵有一个非常重要的性质:他的特征向量是正交向量。为了证明这个性质,我们首先假设有以下两个互不相等的特征值和特征向量,如下:

通过下面的等式,我们能够推出λ1(x1*x2)= λ2(x1*x2):
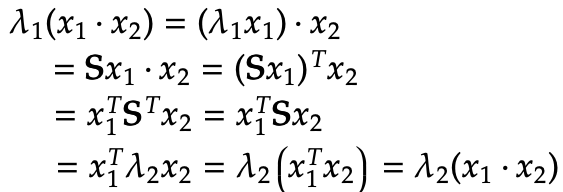
根据前面步骤的结果,我们可以得到如下等式:

我们一开始便假设特征值λ1与λ2并不相等。因此特征值λ1与λ2均不为0,从而x1*x2也不可能等于0——所以这个特征向量是正交的。这揭示了一个重要的结论:对称矩阵能够被分解为两个正交特征向量组成的矩阵与对角矩阵的乘积。并且,对称矩阵的特征值均为实数。

对称矩阵的特征向量具有正交性
3.奇异值分解(SVD)
特征分解适用于n×n维的方形矩阵,而由于m×n维的矩形矩阵在变换过程中会改变矩阵原本的维数,从而对于矩形矩阵并没有对其特征值进行过定义。
![]()
因此对于一个m×n维的矩形矩阵,我们能够使用下面的方法对其进行特征分解——即奇异值分解:
![]()
其中,矩阵U和V是正交矩阵,Σ表示一个包含有奇异值的对角阵。需要说明的是,V和U中的列向量分别作为矩阵A的行空间和列空间中的基向量。
接下来,我们将对其细节进行深入介绍。其实SVD的主要目标就是为了找到三个参数:矩阵v,矩阵u和奇异值σ,其中矩阵v和u都是正交向量且满足下面等式:

一个n维的列向量v经过矩阵A的变换等于一个m维的行向量u经过奇异值σ的缩放。
与之前在特征分解部分的步骤相似,我们也可以将上面的方程用矩阵形式表示出来,从而可以得到矩阵A奇异值分解的表达式。
但是,矩阵v,矩阵u和奇异值σ应该如何求取呢?我们可以通过矩阵乘积(AAᵀ和AᵀA)的方式从方程的两边来分别消除V和U来获得,具体方法如下:


这些步骤看起来是不是很熟悉…
的确,通过对对称矩阵AAᵀ和AᵀA进行奇异值分解,这个结果看起来几乎与对对称矩阵进行特征分解是相同的。因此,找到了矩阵U和矩阵V,那么矩阵AAᵀ和AᵀA的特征分解就能很容易被执行了,并且相应的矩阵Q也能够被找到。对于σ,他们即是矩阵AAᵀ也是矩阵AᵀA的均方根特征值,如下所示:
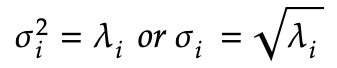
其中值得注意的是,按照习惯奇异值σ在矩阵Σ中总是按递减的顺序进行排列——即第一行放最大的奇异值,最小的奇异值放在最后一行。如果需要与矩阵Σ中的σ一一对应,那么就需要对矩阵U和矩阵V中的列进行重新排列。
现在,我们有了一件非常令人兴奋的事,我们得到了一种可以分解任何矩阵的方法,而不仅仅局限于对方阵进行特征分解。我们现在可以将任何矩阵分解成两个正交矩阵和一个对角矩阵,其中矩阵U的维度为m×r,对角阵Σ的维度为r×r和矩阵V的维度为r×n,其并且矩阵A的秩为r。
4.主成分分析法(PCA)——特征提取
PCA在机器学习中是一种常用的无监督学习算法,它通过构建一种被称为主成分的变量,并将所用到的所有向量映射到由主成分变量构建的空间上去,从而能够减少数据的维度。
主成分分析优点:
1. 减少模型的训练时间——使用了更少的数据集;
2. 数据更容易可视化——对于高维数据,通过人工的方式去实现可视化是比较困难的。
3. 一些情况下能减小过拟合度——通过减少变量来降低模型的过拟合度。
对于实例,我们使用主成分分析法对一个统计包进行了分析。这里为了介绍理论基础,以一个小数据集作为例子进行讲解:

矩阵A有5行3列
我们测试了矩阵A的相关性,从中我们能够发现矩阵A的相关矩阵为一个对称阵:

矩阵A的相关性分析
对矩阵A进行SVD,能够得到矩阵U,Σ和V。需要额外说明的是:所有奇异值的平方和与数据集的总体方差相等。



对协方差矩阵A采用下式进行计算:
1.矩阵A是经过标准化后的矩阵,它的均值为0;2.m是样本数量
从直观上可看出,总方差=协方差矩阵AᵀA的迹=矩阵AᵀA的特征值之和=奇异值平方之和。通过奇异值分解得到的u即是n维空间中的主成分,第i个主成分的重要性可由下式计算所得(通过计算在方差中的比例来确定):

奇异值越大=得到的方差越多=包含的信息就越多
回顾我们例子中的对角矩阵Σ:u1对应的最大奇异值为17.7631,占数据集中方差的比例为74%。因此,通过把5个样本向量映射到u1,在没有损失任何信息的情况下,所需分析矩阵A的维度从3维下降到了1维。
作者:李爱(Li Ai)