(感觉跟上一篇看的可解释cnn没什么差别,都是在高层的卷积层中的每个卷积核加一个loss,查看代码,所加的loss就logistic或者softmax,正在学习中,如果理解有误的地方,敬请谅解并欢迎指出)
摘要:
为了解释高层卷积层CNN中的知识表示,本文在传统CNN基础上提出可解释CNN。可解释CNN,能够在高层卷积层的每个卷积核代表一个特定的目标部件(比如猫头,猫脚等).可解释CNN,使用传统的训练集训练,不作任何部件标注,能够在学习阶段给高层卷积层的卷积核自动分配每个特定部件。可以将可解释CNN应用在任何网络架构中。可解释CNN能够帮助人们理解CNN内部逻辑,比如哪些模式被CNN用于预测的?实验证明可解释CNN比传统CNN在语义上更加有意义。
引文:
我们关注的问题:在没有任何额外的人工监督的情况下,我们可以修改一个CNN,在其转换层中获得可解释的知识表示?

上图中,传统CNN在高层卷积层中,模式比较混乱,比如一个卷积核同时被猫头和猫脚同时激活,相比可解释CNN,一个卷积核只被一个特定的部件(比如猫头)激活。
目标:
① 我们对传统CNN稍加修改,提高其可解释性,这可以广泛应用于不同结构的CNN。
② 我们不需要任何标注,我们的方法能够自动地将每个卷积核的表示推向目标部件。
③ 可解释CNN不改变最后的loss函数,训练集也与训练传统CNN一样。
④ 可解释CNN在区分度上可能会有所下降,但是我们会控制在一个范围内。
方法:

在高层卷积层CNN上,我们对每个卷积核加一个loss,用来推动卷积核向目标部件的表示。如上图所示,我们为输出层的feature map 上的每个卷积核加一个loss。这种loss鼓励了类间激活和神经网络空间分布激活的低熵,每个卷积核必须由单个目标部件激活,不是重复出现在不同的对象区域上。比如猫左眼和猫右眼需要被2个不同的卷积核所表示。
相关工作:
目前分析CNN特征的方法有:
① 可视化网络:CNN中卷积核的可视化是探索隐藏在神经单元中的模式的最直接方法。比如量化神经元得分。
② 模式检索:一些研究超越了被动的可视化,主动地从CNN中检索特定的单元,用于不同的应用。检索filter中的模式。
③ 模型诊断:人们开发了许多方法来诊断黑箱模型的表示。LIME,Grad-Cam。
④ 学习更好的表现形式:与预先训练的CNN的诊断和/或可视化不同,开发了一些方法来学习更有意义的表现形式。比如在训练过程中增加一些规则和标注等。
算法:
给定一个目标高层CNN,我们期望每个卷积核能够只被特定的目标部件所激活,图像中其他目标不被激活。我们假设,I表示训练样本,则Ic表示属于c类的样本。像图2那样,在ReLu操作后,我们给卷积核f的特征映射 feature map x添加一个损失,feature map x是一个nn的矩阵,由于f对应的目标部件可能出现在不同图像中的不同类别中,因此我们为f设计一个n * n大小的模板。像图3那样

每个模板T也是一个nn的矩阵,这个模板描述了当目标部件主要触发特征图x中的第i个单元时,特征图x的激活的理想分布。
前向传播:给出每个输出图像I,CNN从n * n个模板候选中选择一个特定的模板作为mask从特征图x中过滤掉有噪音的激活值。
mask的操作是为了端到端支持梯度反向传播,对于不同的图像输入,CNN节点会选择不能的模板。
如图4所示,对于不同的图像,选择的mask模板不同。

反向传播:
给定一个类别为c的输入图像I,我们期望的是特征图x=f(I)只在目标部件位置上激活,其他地方不激活。换句话说,如果输入图像I的类别是c,特征图x被期望分配给模板T+,如果输入图像不属于类别c,我们分配一个负模板T-,同时希望特征图x匹配上。在正向传播过程中, 所以的特征图,都只选择正模板作为mask。
所以,每个特征图都会在n*n+1个候选模板中很好的匹配上其中一个。
对每个卷积核,加一个loss:
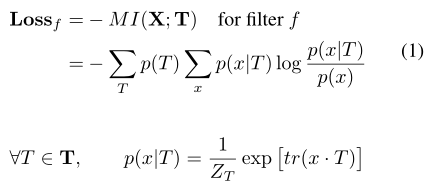
3.1 学习
在可解释CNN中,前向传播跟传统CNN一样,每个卷积核都是自底向上传播信息,在反向传播中,可解释CNN中的每个卷积核接收来自两个方向的梯度,一方面来自最终loss的,一方面来自它本身的loss,总的梯度如下:

4 理解loss

Interpretable Convolutional Neural Networks研读
猜你喜欢
转载自blog.csdn.net/jiafeier_555/article/details/112312691
今日推荐
周排行