在拿到一份数据准备做挖掘建模之前,首先需要进行初步的数据探索性分析,对数据探索性分析之后要先进行一系列的数据预处理步骤。因为拿到的原始数据存在不完整、不一致、有异常的数据,而这些“错误”数据会严重影响到数据挖掘建模的执行效率甚至导致挖掘结果出现偏差,因此首先要数据清洗。数据清洗完成之后接着进行或者同时进行数据集成、转换、归一化等一系列处理,该过程就是数据预处理。一方面是提高数据的质量,另一方面可以让数据更好的适应特定的挖掘模型,在实际工作中该部分的内容可能会占整个工作的70%甚至更多。
系列文章
第1章 Pandas基础操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第2章 精通pandas索引操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第3章 Pandas 分组(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第4章 精通pandas变形操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第5章 精通pandas合并操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第6章 pandas缺失数据(初学者需要掌握的几种基本的数据预处理方法_缺失)
文章目录
- 要求
- 1. 熟练掌握多种单层索引方式及其异同
- 2.掌握和理解多级索引操作
- 3.熟悉常用索引设定方法及其区别
- 4.掌握索引函数、去重函数和抽样函数
- 一、单级索引
- 1. loc方法、iloc方法、[]操作符
- (a)loc方法(注意:所有在loc中使用的切片全部包含右端点!)
- ① 单行索引:
- ② 多行索引:
- ③ 单列索引:
- ④ 多列索引:
- ⑤ 联合索引:
- ⑥ 函数式索引:
- ⑦ 布尔索引(将重点在第2节介绍)
- (b)iloc方法(注意与loc不同,切片右端点不包含)
- ① 单行索引:
- ② 多行索引:
- ③ 单列索引:
- ④ 多列索引:
- ⑤ 混合索引:
- ⑥ 函数式索引:
- (c) []操作符
- (c.1)Series的[]操作
- ① 单元素索引:
- ② 多行索引:
- ③ 函数式索引:
- ④ 布尔索引:
- (c.2)DataFrame的[]操作
- ① 单行索引:
- ② 多行索引:
- ③ 单列索引:
- ④ 多列索引:
- ⑤函数式索引
- ⑥ 布尔索引:
- 2. 布尔索引
- 3. 快速标量索引
- 4. 区间索引
- 二、多级索引
- 1. 创建多级索引
- (a)通过from_tuple或from_arrays
- ① 直接创建元组
- ② 利用zip创建元组
- ③ 通过Array创建
- (b)通过from_product
- (c)指定df中的列创建(set_index方法)
- 2. 多层索引切片
- 3. 多层索引中的slice对象
- 4. 索引层的交换
- 三、索引设定
- 四、常用索引型函数
- 五、重复元素处理
- 六、抽样函数
要求
1. 熟练掌握多种单层索引方式及其异同
2.掌握和理解多级索引操作
3.熟悉常用索引设定方法及其区别
4.掌握索引函数、去重函数和抽样函数

import numpy as np
import pandas as pd
df = pd.read_csv('data/table.csv',index_col='ID')
df.head()

一、单级索引
1. loc方法、iloc方法、[]操作符
最常用的索引方法可能就是这三类,其中iloc表示位置索引,loc表示标签索引,[]也具有很大的便利性,各有特点
(a)loc方法(注意:所有在loc中使用的切片全部包含右端点!)
① 单行索引:
df.loc[1103]

② 多行索引:
df.loc[[1102,2304]]
df.loc[1304:].head()

df.loc[2402::-1].head()
③ 单列索引:
df.loc[:,'Height'].head()

④ 多列索引:
df.loc[:,['Height','Math']].head()
df.loc[:,'Height':'Math'].head()
⑤ 联合索引:
df.loc[1102:2401:3,'Height':'Math'].head()

⑥ 函数式索引:
df.loc[lambda x:x['Gender'] == 'M'].head()
def f(x):
return [1101,1103]
df.loc[f]
⑦ 布尔索引(将重点在第2节介绍)
df.loc[df['Address'].isin(['street_7','street_4'])].head()
df.loc[[True if i[-1] == '4' or i[-1] == '7' else False for i in df['Address'].values]]

小节:本质上说,loc中能传入的只有布尔列表和索引子集构成的列表,只要把握这个原则就很容易理解上面那些操作
(b)iloc方法(注意与loc不同,切片右端点不包含)
① 单行索引:
df.iloc[3]

② 多行索引:
df.iloc[3:5]
③ 单列索引:
df.iloc[:,3].head()

④ 多列索引:
df.iloc[:,7::-2].head()
⑤ 混合索引:
df.iloc[3::4,7::-2].head()
⑥ 函数式索引:
df.iloc[lambda x:[3]]

小节:由上所述,iloc中接收的参数只能为整数或整数列表,不能使用布尔索引
(c) []操作符
如果不想陷入困境,请不要在行索引为浮点时使用[]操作符,因为在Series中的浮点[]并不是进行位置比较,而是值比较,非常特殊
(c.1)Series的[]操作
① 单元素索引:
s = pd.Series(df['Math'],index = df.index)
s[1102]
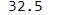
② 多行索引:
s[0:4]
#使用的是绝对位置的整数切片,与元素无关,这里容易混淆
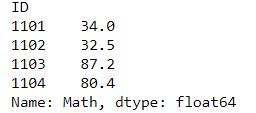
③ 函数式索引:
s[lambda x:x.index[16::-6]]
#注意使用lambda函数时,直接切片(如:s[lambda x: 16::-6])就报错,此时使用的不是绝对位置切片,而是元素切片,非常易错

④ 布尔索引:
s[s>80]

(c.2)DataFrame的[]操作
① 单行索引:
df[1:2]
#这里非常容易写成df['label'],会报错
#同Series使用了绝对位置切片
#如果想要获得某一个元素,可用如下get_loc方法:

row = df.index.get_loc(1102)
df[row:row+2]

② 多行索引:
#用切片,如果是选取指定的某几行,推荐使用loc,否则很可能报错
df[3:5]
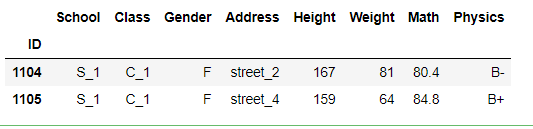
③ 单列索引:
df['School'].head()

④ 多列索引:
df[['School','Math']].head()
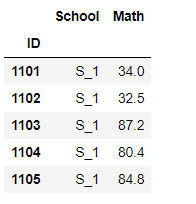
⑤函数式索引
df[lambda x:['Math','Physics']].head()
⑥ 布尔索引:
df[df['Gender'] == 'F'].head()
小节:一般来说,[]操作符常用于列选择或布尔选择,尽量避免行的选择
2. 布尔索引
(a)布尔符号:’&’,’|’,’~’:分别代表和and,或or,取反not
df[(df["Gender"] == 'M')&(df["Address"]=='street_1')]

df[(df['Math']>85)|(df['Address']=='street_1')]

df[~((df['Math']>55)|(df['Address']=='street_2'))]

loc和[]中相应位置都能使用布尔列表选择:
df.loc[df['Math']>90,(df[:8]['Address'] == 'street_6').values]
#如果不加values就会索引对齐发生错误,Pandas中的索引对齐是一个重要特征,很多时候非常使用
#但是若不加以留意,就会埋下隐患
(b) isin方法
df[df['Address'].isin(['street_1','street_4'])&df['Physics'].isin(['A','A-'])]
#上面也可以用字典方式写:
df[df[['Address','Physics']].isin({'Address':['street_1','street_4'],'Physics':['A','A-']}).all(1)]
#all与&的思路是类似的,其中的1代表按照跨列方向判断是否全为True

3. 快速标量索引
当只需要取一个元素时,at和iat方法能够提供更快的实现:
display(df.at[1101,'School'])
display(df.loc[1101,'School'])
display(df.iat[19,0])
display(df.iloc[0,0])
#可尝试去掉注释对比时间
#%timeit df.at[1101,'School']
#%timeit df.loc[1101,'School']
#%timeit df.iat[0,0]
#%timeit df.iloc[0,0]

4. 区间索引
此处介绍并不是说只能在单级索引中使用区间索引,只是作为一种特殊类型的索引方式,在此处先行介绍
(a)利用interval_range方法
pd.interval_range(start=0,end = 5)
#closed参数可选'left''right''both''neither',默认左开右闭

pd.interval_range(start=0,periods=8,freq=5)
#periods参数控制区间个数,freq控制步长
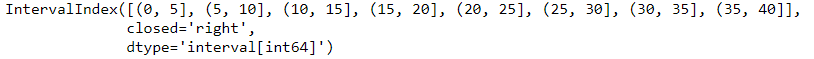
(b)利用cut将数值列转为区间为元素的分类变量,例如统计数学成绩的区间情况:
math_interval = pd.cut(df['Math'],bins=[0,40,60,80,100])
#注意,如果没有类型转换,此时并不是区间类型,而是category类型
math_interval.head()

(c)区间索引的选取
df_i = df.join(math_interval,rsuffix='_interval')[['Math','Math_interval']]\
.reset_index().set_index('Math_interval')
df_i.head()
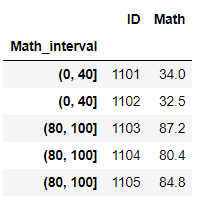
df_i.loc[65].head()
#包含该值就会被选中
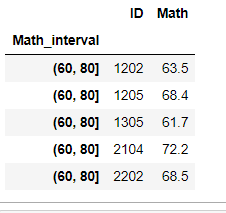
df_i.loc[[65,90]].head()

如果想要选取某个区间,先要把分类变量转为区间变量,再使用overlap方法:
#df_i.loc[pd.Interval(70,75)].head() 报错
df_i[df_i.index.astype('interval').overlaps(pd.Interval(70, 85))].head()
二、多级索引
1. 创建多级索引
(a)通过from_tuple或from_arrays
① 直接创建元组
tuples = [('A','a'),('A','b'),('B','a'),('B','b')]
mul_index = pd.MultiIndex.from_tuples(tuples, names=('Upper', 'Lower'))
mul_index

pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
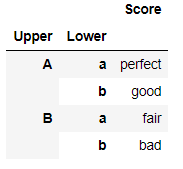
② 利用zip创建元组
L1 = list('AABB')
L2 = list('abab')
tuples = list(zip(L1,L2))
mul_index = pd.MultiIndex.from_tuples(tuples, names=('Upper', 'Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)

③ 通过Array创建
arrays = [['A','a'],['A','b'],['B','a'],['B','b']]
mul_index = pd.MultiIndex.from_tuples(arrays, names=('Upper', 'Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)
mul_index
#由此看出内部自动转成元组

(b)通过from_product
L1 = ['A','B']
L2 = ['a','b']
pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
#两两相乘
(c)指定df中的列创建(set_index方法)
df_using_mul = df.set_index(['Class','Address'])
df_using_mul.tail()

2. 多层索引切片
df_using_mul.head()
(a)一般切片
#df_using_mul.loc['C_2','street_5']
#当索引不排序时,单个索引会报出性能警告
#df_using_mul.index.is_lexsorted()
#该函数检查是否排序
df_using_mul.sort_index().loc['C_2','street_5']
#df_using_mul.sort_index().index.is_lexsorted()
#df_using_mul.loc[('C_2','street_5'):] 报错
#当不排序时,不能使用多层切片
df_using_mul.sort_index().loc[('C_2','street_6'):('C_3','street_4')]
#注意此处由于使用了loc,因此仍然包含右端点

df_using_mul.sort_index().loc[('C_2','street_7'):'C_3']
#非元组也是合法的,表示选中该层所有元素

(b)第一类特殊情况:由元组构成列表
df_using_mul.sort_index().loc[[('C_2','street_7'),('C_3','street_2')]]
#表示选出某几个元素,精确到最内层索引
3. 多层索引中的slice对象
L1,L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3,L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_s = pd.DataFrame(np.random.rand(9,9),index=mul_index1,columns=mul_index2)
df_s

idx=pd.IndexSlice
索引Slice的使用非常灵活:
df_s.loc[idx['B':,df_s['D']['d']>0.3],idx[df_s.sum()>4]]
#df_s.sum()默认为对列求和,因此返回一个长度为9的数值列表

4. 索引层的交换
(a)swaplevel方法(两层交换)
df_using_mul.head()

df_using_mul.swaplevel(i=1,j=0,axis=0).sort_index().head()

(b)reorder_levels方法(多层交换)
df_muls = df.set_index(['School','Class','Address'])
df_muls.head()

df_muls.reorder_levels([2,0,1],axis=0).sort_index().head()

#如果索引有name,可以直接使用name
df_muls.reorder_levels(['Address','School','Class'],axis=0).sort_index().head()
三、索引设定
1. index_col参数
index_col是read_csv中的一个参数,而不是某一个方法:
pd.read_csv('data/table.csv',index_col=['Address','School']).head()

2. reindex和reindex_like
reindex是指重新索引,它的重要特性在于索引对齐,很多时候用于重新排序
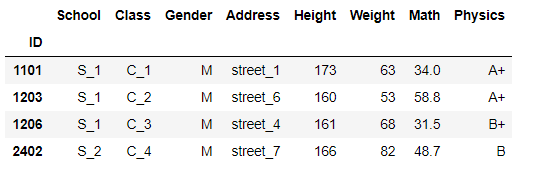
df.head()

df.reindex(index=[1101,1203,1206,2402])
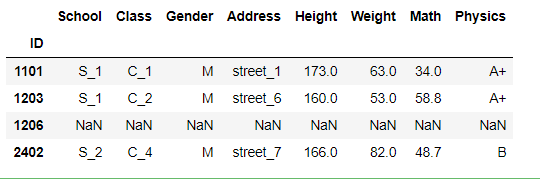
df.reindex(columns=['Height','Gender','Average']).head()
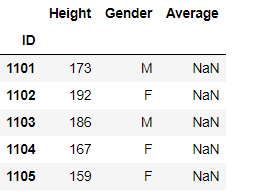
可以选择缺失值的填充方法
fill_value和method(bfill/ffill/nearest),其中method参数必须索引单调
df.reindex(index=[1101,1203,1206,2402],method='bfill')
#bfill表示用所在索引1206的后一个有效行填充,ffill为前一个有效行,nearest是指最近的
df.reindex(index=[1101,1203,1206,2402],method='nearest')
#数值上1205比1301更接近1206,因此用前者填充
reindex_like的作用为生成一个横纵索引完全与参数列表一致的DataFrame,数据使用被调用的表,reindex_like的作用为生成一个横纵索引完全与参数列表一致的DataFrame,数据使用被调用的表
df_temp = pd.DataFrame({'Weight':np.zeros(5),
'Height':np.zeros(5),
'ID':[1101,1104,1103,1106,1102]}).set_index('ID')
df_temp.reindex_like(df[0:5][['Weight','Height']])
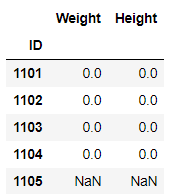
如果df_temp单调还可以使用method参数:
df_temp = pd.DataFrame({'Weight':range(5),
'Height':range(5),
'ID':[1101,1104,1103,1106,1102]}).set_index('ID').sort_index()
df_temp.reindex_like(df[0:5][['Weight','Height']],method='bfill')
#可以自行检验这里的1105的值是否是由bfill规则填充

3. set_index和reset_index
先介绍set_index:从字面意思看,就是将某些列作为索引
使用表内列作为索引:
df.head()

df.set_index('Class').head()

利用append参数可以将当前索引维持不变
df.set_index('Class',append=True).head()

当使用与表长相同的列作为索引(需要先转化为Series,否则报错):
df.set_index(pd.Series(range(df.shape[0]))).head()
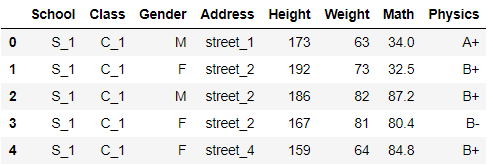
可以直接添加多级索引:
df.set_index([pd.Series(range(df.shape[0])),pd.Series(np.ones(df.shape[0]))]).head()
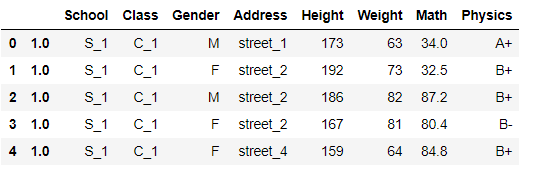
下面介绍reset_index方法,它的主要功能是将索引重置
默认状态直接恢复到自然数索引:
df.reset_index().head()

用level参数指定哪一层被reset,用col_level参数指定set到哪一层:
L1,L2 = ['A','B','C'],['a','b','c']
mul_index1 = pd.MultiIndex.from_product([L1,L2],names=('Upper', 'Lower'))
L3,L4 = ['D','E','F'],['d','e','f']
mul_index2 = pd.MultiIndex.from_product([L3,L4],names=('Big', 'Small'))
df_temp = pd.DataFrame(np.random.rand(9,9),index=mul_index1,columns=mul_index2)
df_temp.head()

df_temp1 = df_temp.reset_index(level=1,col_level=1)
df_temp1.head()

df_temp1.columns
#看到的确插入了level2

df_temp1.index
#最内层索引被移出

4. rename_axis和rename
rename_axis是针对多级索引的方法,作用是修改某一层的索引名,而不是索引标签
df_temp.rename_axis(index={'Lower':'LowerLower'},columns={'Big':'BigBig'})

rename方法用于修改列或者行索引标签,而不是索引名:
df_temp.rename(index={'A':'T'},columns={'e':'changed_e'}).head()

四、常用索引型函数
1. where函数
当对条件为False的单元进行填充:
df.head()

df.where(df['Gender']=='M').head()
#不满足条件的行全部被设置为NaN

通过这种方法筛选结果和[]操作符的结果完全一致:
df.where(df['Gender']=='M').dropna().head()

第一个参数为布尔条件,第二个参数为填充值:
df.where(df['Gender']=='M',np.random.rand(df.shape[0],df.shape[1])).head()
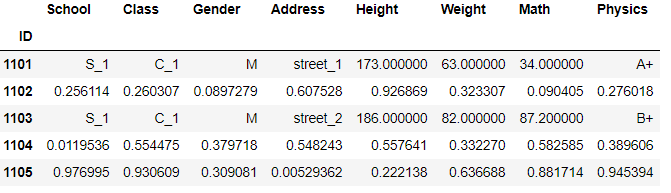
2. mask函数
mask函数与where功能上相反,其余完全一致,即对条件为True的单元进行填充
df.mask(df['Gender']=='M').dropna().head()

df.mask(df['Gender']=='M',np.random.rand(df.shape[0],df.shape[1])).head()

3. query函数
df.head()

query函数中布尔表达式
下面的符号都是合法的:行列索引名、字符串、and/not/or/&/|/~/not in/in/==/!=、四则运算符
df.query('(Address in ["street_6","street_7"])&(Weight>(70+10))&(ID in [1303,2304,2402])')
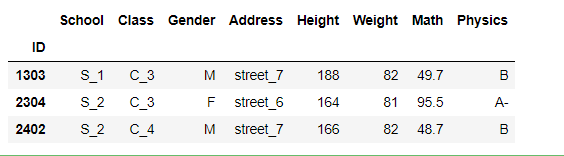
五、重复元素处理
1. duplicated方法
该方法返回了是否重复的布尔列表
df.duplicated('Class').head()

可选参数
keep默认为first,即首次出现设为不重复,若为last,则最后一次设为不重复,若为False,则所有重复项为False
df.duplicated('Class',keep='last').tail()

df.duplicated('Class',keep=False).head()
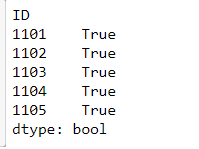
2. drop_duplicates方法
从名字上看出为剔除重复项,这在后面章节中的分组操作中可能是有用的,例如需要保留每组的第一个值:
df.drop_duplicates('Class')
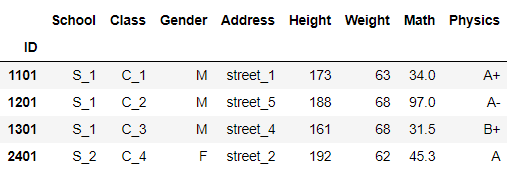
参数与duplicate函数类似:
df.drop_duplicates('Class',keep='last')
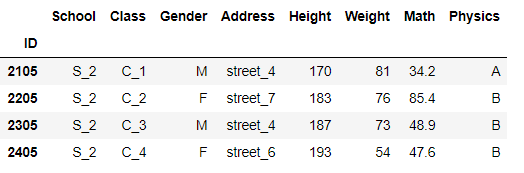
在传入多列时等价于将多列共同视作一个多级索引,比较重复项:
df.drop_duplicates(['School','Class'])

六、抽样函数
这里的抽样函数指的就是sample函数
(a)n为样本量
df.sample(n=5)

(b)frac为抽样比
df.sample(frac=0.05)
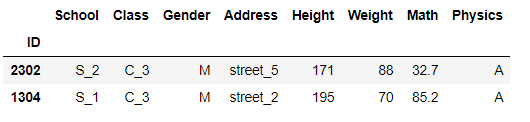
(c)replace为是否放回
df.sample(n=df.shape[0],replace=True).head()
df.sample(n=35,replace=True).index.is_unique
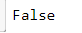
(d)axis为抽样维度,默认为0,即抽行
df.sample(n=3,axis=1).head()
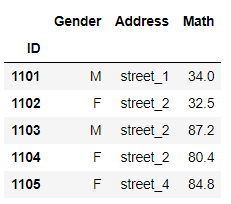
(e)weights为样本权重,自动归一化
df.sample(n=3,weights=np.random.rand(df.shape[0])).head()
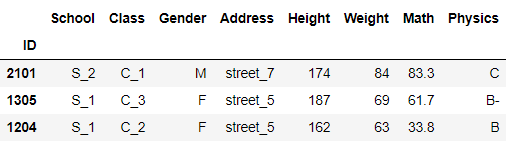
#以某一列为权重,这在抽样理论中很常见
df.sample(n=3,weights=df['Math'])
代码和数据地址:https://github.com/XiangLinPro/pandas
另外博主收藏这些年来看过或者听过的一些不错的常用的上千本书籍,没准你想找的书就在这里呢,包含了互联网行业大多数书籍和面试经验题目等等。有人工智能系列(常用深度学习框架TensorFlow、pytorch、keras。NLP、机器学习,深度学习等等),大数据系列(Spark,Hadoop,Scala,kafka等),程序员必修系列(C、C++、java、数据结构、linux,设计模式、数据库等等)以下是部分截图
更多文章见本原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】即可领取哦。

给大家推荐一个Github,上面非常非常多的干货:https://github.com/XiangLinPro/IT_book
There is no such thing as a great talent without great will - power.——Balzac
「没有伟大的意志力,便没有雄才大略。——巴尔扎克」
关于Datawhale
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。