在拿到一份数据准备做挖掘建模之前,首先需要进行初步的数据探索性分析,对数据探索性分析之后要先进行一系列的数据预处理步骤。因为拿到的原始数据存在不完整、不一致、有异常的数据,而这些“错误”数据会严重影响到数据挖掘建模的执行效率甚至导致挖掘结果出现偏差,因此首先要数据清洗。数据清洗完成之后接着进行或者同时进行数据集成、转换、归一化等一系列处理,该过程就是数据预处理。一方面是提高数据的质量,另一方面可以让数据更好的适应特定的挖掘模型,在实际工作中该部分的内容可能会占整个工作的70%甚至更多。
系列文章
第1章 Pandas基础操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第2章 精通pandas索引操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第3章 Pandas 分组(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第4章 精通pandas变形操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第5章 精通pandas合并操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第6章 pandas缺失数据(初学者需要掌握的几种基本的数据预处理方法_缺失)
第7章 pandas文本数据(初学者需要掌握的几种基本的数据预处理方法)
第8章 pandas分类数据(初学者必学)
文章目录
第9章 时序数据
import pandas as pd
import numpy as np
一、时序的创建
1. 四类时间变量
现在理解可能关于③和④有些困惑,后面会作出一些说明
| 名称 | 描述 | 元素类型 | 创建方式 |
|---|---|---|---|
| ① Date times(时间点/时刻) | 描述特定日期或时间点 | Timestamp | to_datetime或date_range |
| ② Time spans(时间段/时期) | 由时间点定义的一段时期 | Period | Period或period_range |
| ③ Date offsets(相对时间差) | 一段时间的相对大小(与夏/冬令时无关) | DateOffset | DateOffset |
| ④ Time deltas(绝对时间差) | 一段时间的绝对大小(与夏/冬令时有关) | Timedelta | to_timedelta或timedelta_range |
2. 时间点的创建
(a)to_datetime方法
Pandas在时间点建立的输入格式规定上给了很大的自由度,下面的语句都能正确建立同一时间点
pd.to_datetime('2020.1.1')
pd.to_datetime('2020 1.1')
pd.to_datetime('2020 1 1')
pd.to_datetime('2020 1-1')
pd.to_datetime('2020-1 1')
pd.to_datetime('2020-1-1')
pd.to_datetime('2020/1/1')
pd.to_datetime('1.1.2020')
pd.to_datetime('1.1 2020')
pd.to_datetime('1 1 2020')
pd.to_datetime('1 1-2020')
pd.to_datetime('1-1 2020')
pd.to_datetime('1-1-2020')
pd.to_datetime('1/1/2020')
pd.to_datetime('20200101')
pd.to_datetime('2020.0101')
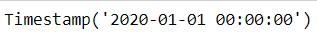
下面的语句都会报错
#pd.to_datetime('2020\\1\\1')
#pd.to_datetime('2020`1`1')
#pd.to_datetime('2020.1 1')
#pd.to_datetime('1 1.2020')
此时可利用format参数强制匹配
pd.to_datetime('2020\\1\\1',format='%Y\\%m\\%d')
pd.to_datetime('2020`1`1',format='%Y`%m`%d')
pd.to_datetime('2020.1 1',format='%Y.%m %d')
pd.to_datetime('1 1.2020',format='%d %m.%Y')
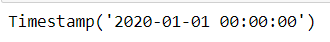
同时,使用列表可以将其转为时间点索引
pd.Series(range(2),index=pd.to_datetime(['2020/1/1','2020/1/2']))

type(pd.to_datetime(['2020/1/1','2020/1/2']))

对于DataFrame而言,如果列已经按照时间顺序排好,则利用to_datetime可自动转换
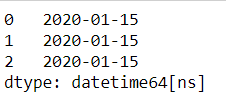
df = pd.DataFrame({'year': [2020, 2020],'month': [1, 1], 'day': [1, 2]})
pd.to_datetime(df)

(b)时间精度与范围限制
事实上,Timestamp的精度远远不止day,可以最小到纳秒ns
pd.to_datetime('2020/1/1 00:00:00.123456789')
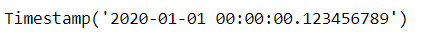
同时,它带来范围的代价就是只有大约584年的时间点是可用的
pd.Timestamp.min

pd.Timestamp.max

(c)date_range方法
一般来说,start/end/periods(时间点个数)/freq(间隔方法)是该方法最重要的参数,给定了其中的3个,剩下的一个就会被确定
pd.date_range(start='2020/1/1',end='2020/1/10',periods=3)

pd.date_range(start='2020/1/1',end='2020/1/10',freq='D')

pd.date_range(start='2020/1/1',periods=3,freq='D')

pd.date_range(end='2020/1/3',periods=3,freq='D')

其中freq参数有许多选项,下面将常用部分罗列如下,更多选项可看这里
| 符号 | D/B | W | M/Q/Y | BM/BQ/BY | MS/QS/YS | BMS/BQS/BYS | H | T | S |
|---|---|---|---|---|---|---|---|---|---|
| 描述 | 日/工作日 | 周 | 月末 | 月/季/年末日 | 月/季/年末工作日 | 月/季/年初日 | 月/季/年初工作日 | 小时 | 分钟 |
pd.date_range(start='2020/1/1',periods=3,freq='T')

pd.date_range(start='2020/1/1',periods=3,freq='M')

pd.date_range(start='2020/1/1',periods=3,freq='BYS')

bdate_range是一个类似与date_range的方法,特点在于可以在自带的工作日间隔设置上,再选择weekmask参数和holidays参数
它的freq中有一个特殊的’C’/‘CBM’/'CBMS’选项,表示定制,需要联合weekmask参数和holidays参数使用
例如现在需要将工作日中的周一、周二、周五3天保留,并将部分holidays剔除
weekmask = 'Mon Tue Fri'
holidays = [pd.Timestamp('2020/1/%s'%i) for i in range(7,13)]
#注意holidays
pd.bdate_range(start='2020-1-1',end='2020-1-15',freq='C',weekmask=weekmask,holidays=holidays)
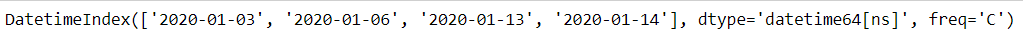
3. DateOffset对象
(a)DataOffset与Timedelta的区别
Timedelta绝对时间差的特点指无论是冬令时还是夏令时,增减1day都只计算24小时
DataOffset相对时间差指,无论一天是23\24\25小时,增减1day都与当天相同的时间保持一致
例如,英国当地时间 2020年03月29日,01:00:00 时钟向前调整 1 小时 变为 2020年03月29日,02:00:00,开始夏令时
ts = pd.Timestamp('2020-3-29 01:00:00', tz='Europe/Helsinki')
ts + pd.Timedelta(days=1)
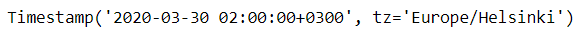
ts + pd.DateOffset(days=1)

这似乎有些令人头大,但只要把tz(time zone)去除就可以不用管它了,两者保持一致,除非要使用到时区变换
ts = pd.Timestamp('2020-3-29 01:00:00')
ts + pd.Timedelta(days=1)
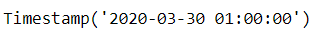
ts + pd.DateOffset(days=1)

(b)增减一段时间
DateOffset的可选参数包括years/months/weeks/days/hours/minutes/seconds
pd.Timestamp('2020-01-01') + pd.DateOffset(minutes=20) - pd.DateOffset(weeks=2)

(c)各类常用offset对象
| freq | D/B | W | (B)M/(B)Q/(B)Y | (B)MS/(B)QS/(B)YS | H | T | S | C |
|---|---|---|---|---|---|---|---|---|
| offset | DateOffset/BDay | Week | (B)MonthEnd/(B)QuarterEnd/(B)YearEnd | (B)MonthBegin/(B)QuarterBegin/(B)YearBegin | Hour | Minute | Second | CDay(定制工作日) |
pd.Timestamp('2020-01-01') + pd.offsets.Week(2)
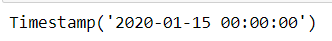
pd.Timestamp('2020-01-01') + pd.offsets.BQuarterBegin(1)

(d)序列的offset操作
利用apply函数
pd.Series(pd.offsets.BYearBegin(3).apply(i) for i in pd.date_range('20200101',periods=3,freq='Y'))
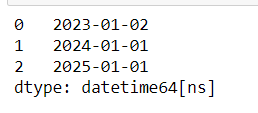
直接使用对象加减
pd.date_range('20200101',periods=3,freq='Y') + pd.offsets.BYearBegin(3)

定制offset,可以指定weekmask和holidays参数(思考为什么三个都是一个值)
pd.Series(pd.offsets.CDay(3,weekmask='Wed Fri',holidays='2020010').apply(i)
for i in pd.date_range('20200105',periods=3,freq='D'))
二、时序的索引及属性
- 索引切片
这一部分几乎与第二章的规则完全一致
rng = pd.date_range('2020','2021', freq='W')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts.head()

ts['2020-01-26']
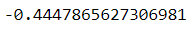
合法字符自动转换为时间点
ts['2020-01-26':'20200726'].head()

2. 子集索引
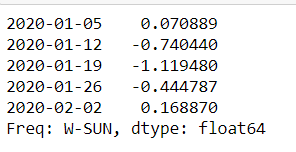
ts['2020-7'].head()

支持混合形态索引
ts['2011-1':'20200726'].head()
3. 时间点的属性
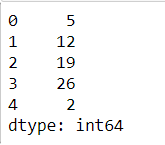
采用dt对象可以轻松获得关于时间的信息
pd.Series(ts.index).dt.week.head()

pd.Series(ts.index).dt.day.head()
利用strftime可重新修改时间格式
pd.Series(ts.index).dt.strftime('%Y-间隔1-%m-间隔2-%d').head()

对于datetime对象可以直接通过属性获取信息
pd.date_range('2020','2021', freq='W').month
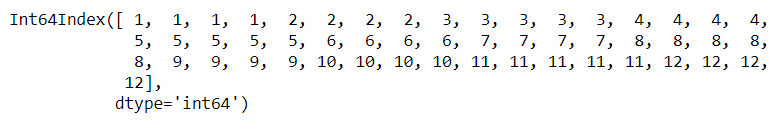
pd.date_range('2020','2021', freq='W').weekday

三、重采样
所谓重采样,就是指resample函数,它可以看做时序版本的groupby函数
- resample对象的基本操作
采样频率一般设置为上面提到的offset字符
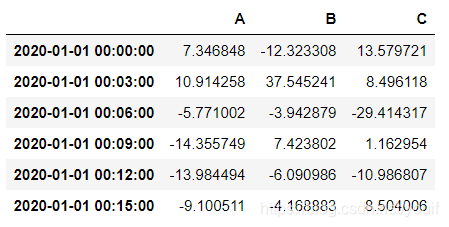
df_r = pd.DataFrame(np.random.randn(1000, 3),index=pd.date_range('1/1/2020', freq='S', periods=1000),
columns=['A', 'B', 'C'])
r = df_r.resample('3min')
r

r.sum()
df_r2 = pd.DataFrame(np.random.randn(200, 3),index=pd.date_range('1/1/2020', freq='D', periods=200),
columns=['A', 'B', 'C'])
r = df_r2.resample('CBMS')
r.sum()
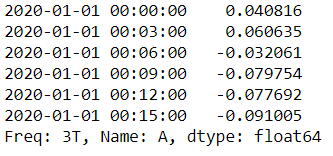
2. 采样聚合
r = df_r.resample('3T')
r['A'].mean()
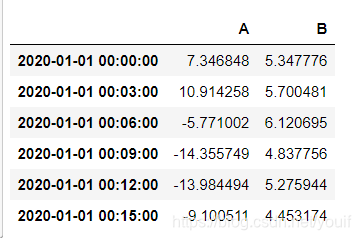
r['A'].agg([np.sum, np.mean, np.std])

类似地,可以使用函数/lambda表达式
r.agg({'A': np.sum,'B': lambda x: max(x)-min(x)})
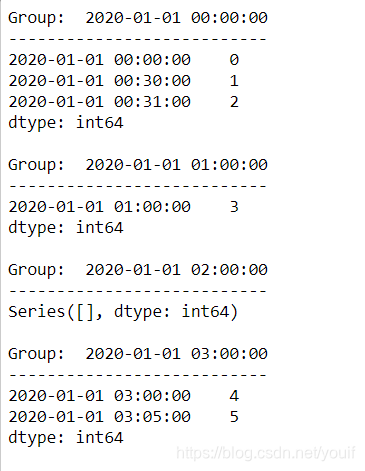
3. 采样组的迭代
采样组的迭代和groupby迭代完全类似,对于每一个组都可以分别做相应操作
small = pd.Series(range(6),index=pd.to_datetime(['2020-01-01 00:00:00', '2020-01-01 00:30:00'
, '2020-01-01 00:31:00','2020-01-01 01:00:00'
,'2020-01-01 03:00:00','2020-01-01 03:05:00']))
resampled = small.resample('H')
for name, group in resampled:
print("Group: ", name)
print("-" * 27)
print(group, end="\n\n")
四、窗口函数
下面主要介绍pandas中两类主要的窗口(window)函数:rolling/expanding
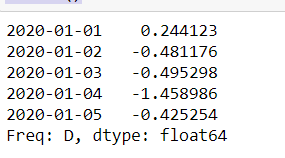
s = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2020', periods=1000))
s.head()
1. Rolling
(a)常用聚合
所谓rolling方法,就是规定一个窗口,它和groupby对象一样,本身不会进行操作,需要配合聚合函数才能计算结果
s.rolling(window=50)

s.rolling(window=50).mean()
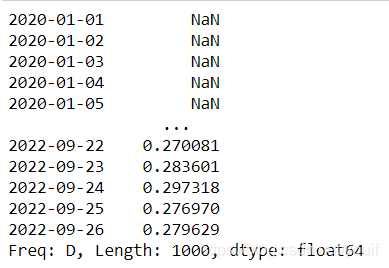
min_periods参数是指需要的非缺失数据点数量阀值
s.rolling(window=50,min_periods=3).mean().head()
count/sum/mean/median/min/max/std/var/skew/kurt/quantile/cov/corr都是常用的聚合函数
(b)rolling的apply聚合
使用apply聚合时,只需记住传入的是window大小的Series,输出的必须是标量即可,比如如下计算变异系数
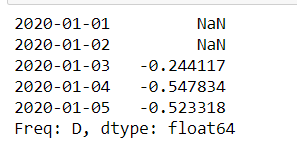
s.rolling(window=50,min_periods=3).apply(lambda x:x.std()/x.mean()).head()

(c)基于时间的rolling
s.rolling('15D').mean().head()

可选closed=‘right’(默认)‘left’‘both’'neither’参数,决定端点的包含情况
s.rolling('15D', closed='right').sum().head()
2. Expanding
(a)expanding函数
普通的expanding函数等价与rolling(window=len(s),min_periods=1),是对序列的累计计算
s.rolling(window=len(s),min_periods=1).sum().head()

s.expanding().sum().head()

apply方法也是同样可用的
s.expanding().apply(lambda x:sum(x)).head()

(b)几个特别的Expanding类型函数
cumsum/cumprod/cummax/cummin都是特殊expanding累计计算方法.
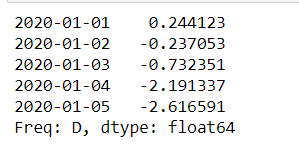
s.cumsum().head()
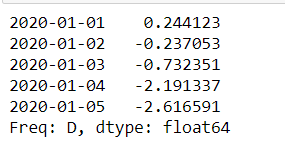
s.cumsum().head()

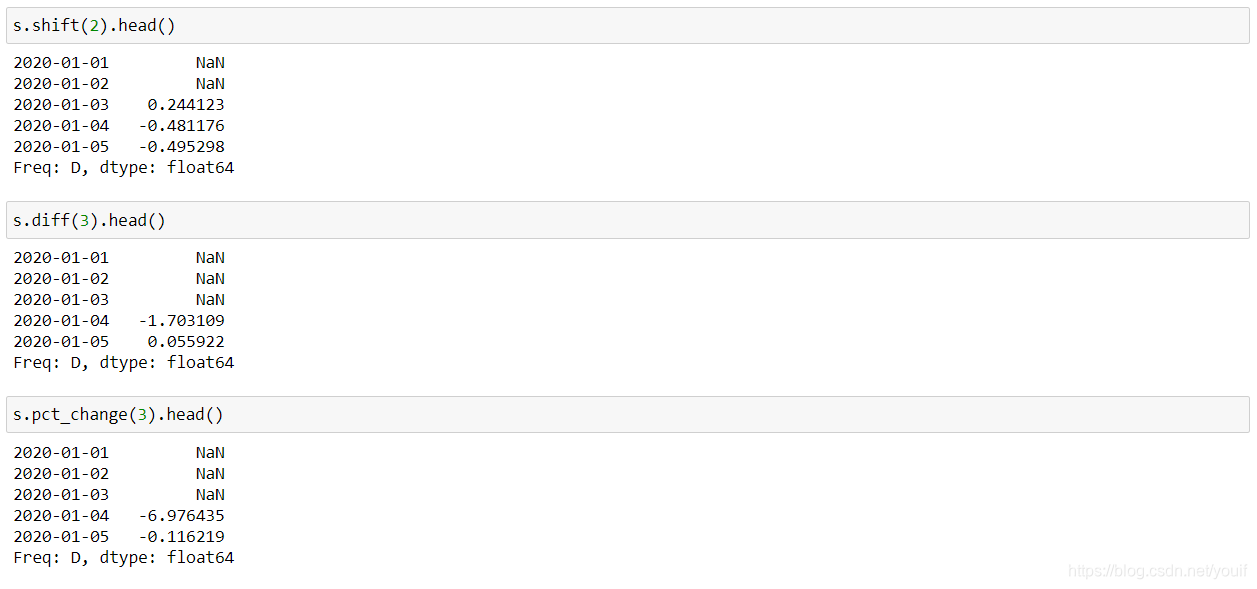
shift/diff/pct_change都是涉及到了元素关系
①shift是指序列索引不变,但值向后移动
②diff是指前后元素的差,period参数表示间隔,默认为1,并且可以为负
③pct_change是值前后元素的变化百分比,period参数与diff类似
代码和数据地址:https://github.com/XiangLinPro/pandas
另外博主收藏这些年来看过或者听过的一些不错的常用的上千本书籍,没准你想找的书就在这里呢,包含了互联网行业大多数书籍和面试经验题目等等。有人工智能系列(常用深度学习框架TensorFlow、pytorch、keras。NLP、机器学习,深度学习等等),大数据系列(Spark,Hadoop,Scala,kafka等),程序员必修系列(C、C++、java、数据结构、linux,设计模式、数据库等等)以下是部分截图
更多文章见本原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】即可领取哦。

给大家推荐一个Github,上面非常非常多的干货:https://github.com/XiangLinPro/IT_book
There is no such thing as a great talent without great will - power.——Balzac
「没有伟大的意志力,便没有雄才大略。——巴尔扎克」
关于Datawhale
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
2020.5.30 城口