文章目录
声明:
本博客是本人在学习《大话数据结构》后整理的笔记,旨在方便复习和回顾,并非用作商业用途。
本博客已标明出处,如有侵权请告知,马上删除。
9.1 开场白
略
9.2 排序的基本概念与分类
排序是我们生活中经常会面对的问题。同学们做操时会按照从矮到高排列;老师查看上课出勤情况时,会按学生学号顺序点名;高考录取时,会按成绩总分降序依次录取等。那排序的严格定义是什么呢?
假设含有 n 个记录的序列为 {r1,r2,……,rn},其相应的关键字分别为 {k1,k2,……,kn},需确定 1,2,……,n 的一种排列 p1,p2,……,pn,使其相应的关键字满足 kp1≤kp2≤……≤kpn(非递减或非递增)关系,即使得序列成为一个按关键字有序的序列 {rp1,rp2,……,rpn},这样的操作就称为排序。
注意我们在排序问题中,通常将数据元素称为记录。显然我们输入的是一个记录集合,输出的也是一个记录集合,所以说,可以将排序看成是线性表的一种操作。
排序的依据是关键字之间的大小关系,那么,对同一个记录集合,针对不同的关键字进行排序,可以得到不同序列。
这里关键字 ki 可以是记录 r 的主关键字,也可以是次关键字,甚至是若干数据项的组合。比如我们某些大学为了选拔在主科上更优秀的学生,要求对所有学生的所有科目总分降序排名,并且在同样总分的情况下将语数外总分做降序排名。这就是对总分和语数外总分两个次关键字的组合排序。如图 9-2-1 所示,对于组合排序的问题, 当然可以先排序总分,若总分相等的情况下,再排序语数外总分,但这是比较土的办法。我们还可以应用一个技巧来实现一次排序即完成组合排序问题,例如,把总分与语数外都当成字符串首尾连接在一起( 注意语数外总分如果位数不够三位,需要在前面补零 ),很容易可以得到令狐冲的 “753229” 要小于张无忌的 “753236” ,于是张无忌就排在了令狐冲的前面。
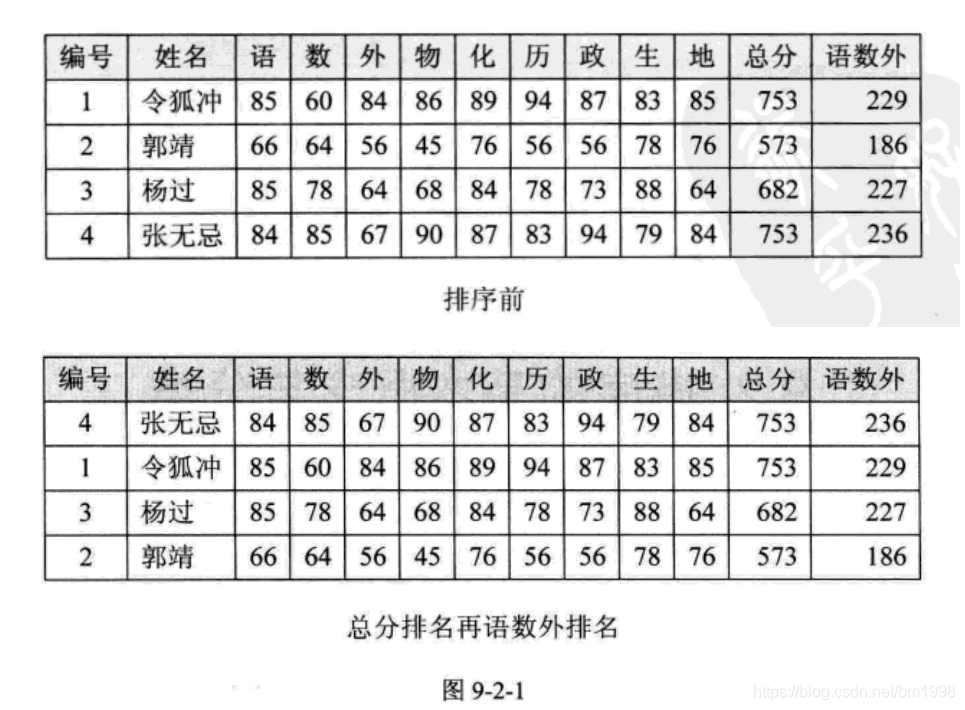
从这个例子也可看出,多个关键字的排序最终都可以转化为单个关键字的排序, 因此,我们这里主要讨论的是单个关键字的排序。
9.2.1 排序的稳定性
也正是由于排序不仅是针对主关键字,那么对于次关键字,因为待排序的记录序列中可能存在两个或两个以上的关键字相等的记录,排序结果可能会存在不唯一的情况,我们给出了稳定与不稳定排序的定义。
假设 ki=kj(1≤i≤n, 1≤j≤n, i≠j),且在排序前的序列中 ri 领先于 rj(即 i<j)。如果排序后 ri 仍领先于 rj,则称所用的排序方法是稳定的;反之,若可能使得排序后的序列中 rj 领先 ri,则称所用的排序方法是不稳定的。
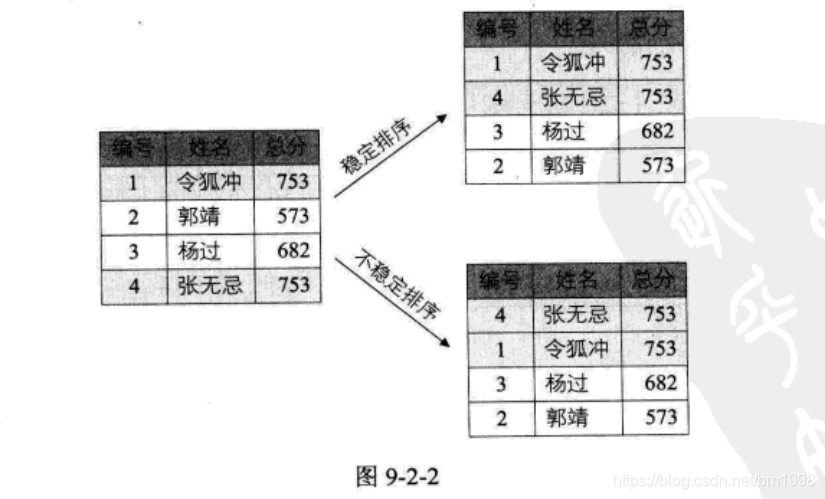
如图 9-2-2 所示,经过对总分的降序排序后,总分高的排在前列。此时对于令狐冲和张无忌而言,未排序时是令狐冲在前,那么它们总分排序后,分数相等的令狐冲依然应该在前,这样才算是稳定的排序,如果他们二者颠倒了,则此排序是不稳定的了。只要有一组关键字实例发生类似情况, 就可认为此排序方法是不稳定的。排序算法是否稳定的,要通过分析后才能得出。
9.2.2 内排序与外排序
根据在排序过程中待排序的记录是否全部被放置在内存中,排序分为:内排序和外排序。
内排序是在排序整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。我们这里主要就介绍内排序的多种方法。
对于内排序来说,排序算法的性能主要是受 3 个方面影响:
-
时间性能
排序是数据处理中经常执行的一种操作,往往属于系统的核心部分,因此排序算法的时间开销是衡量其好坏的最重要的标志。在内排序中,主要进行两种操作:比较和移动。比较指关键字之间的比较,这是要做排序最起码的操作。移动指记录从一个位置移动到另一个位置,事实上,移动可以通过改变记录的存储方式来予以避免。总之,高效率的内排序算法应该是具有尽可能少的关键字比较次数和尽可能少的记录移动次数。
-
辅助空间
评价排序算法的另一个主要标准是执行算法所需要的辅助存储空间。辅助存储空间是除了存放待排序所占用的存储空间之外,执行算法所需要的其他存储空间。
-
算法的复杂性
注意这里指的是算法本身的复杂度,而不是指算法的时间复杂度。显然算法过于复杂也会影响排序的性能。
根据排序过程中借助的主要操作,我们把内排序分为:插入排序、交换排序、选择排序和归并排序。可以说,这些都是比较成熟的排序技术,已经被广泛地应用于许许多多的程序语言或数据库当中,甚至它们都已经封装了关于排序算法的实现代码。 因此,我们学习这些排序算法的目的更多并不是为了去在现实中编程排序算法,而是通过学习来提高我们编写算法的能力,以便于去解决更多复杂和灵活的应用性问题。
接下来一共要讲解七种排序的算法,按照算法的复杂度分为两大类,冒泡排序、简单选择排序和直接插入排序属于简单算法,而希尔排序、堆排序、归并排序、快速排序属于改进算法。后面将依次讲解。
9.2.3 排序用到的结构与函数
为了讲清楚排序算法的代码,我先提供一个用于排序用的顺序表结构,此结构也将用于之后我们要讲的所有排序算法。
#define MAXSIZE 10 /* 用于要排序数组个数最大值,可根据需要修改 */
typedef struct
{
int r[MAXSIZE + 1]; /* 用于存储要排序数组,r[0] 用作哨兵或临时变量 */
int length; /* 用于记录顺序表的长度 */
}SqList;
另外,由于排序最最常用到的操作是数组两元素的交换,我们将它写成函数,在之后的讲解中会大量的用到。
/* 交换 L 中数组 r 的下标为 i 和 j 的值 */
void swap(SqList *L, int i, int j)
{
int temp = L->r[i];
L->r[i] = L->r[j];
L->r[j] = temp;
}
好了,说了这么多,我们来看第一个排序算法。
9.3 冒泡排序
9.3.1 最简单排序实现
冒泡排序(Bubble Sort)一种交换排序,它的基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止。
冒泡的实现在细节上可以有很多种变化,我们将分别就 3 种不同的冒泡实现代码,来讲解冒泡排序的思想。这里,我们就先来看看比较容易理解的一段。
/* 对顺序表 L 作交换排序(冒泡排序初级版)*/
void BubbleSort0(SqList *L)
{
int i, j;
for (i = 1; i<L->length; i++)
{
for (j = i + 1; j <= L->length; j++)
{
if (L->r[i] > L->r[j])
{
swap(L, i, j); /* 交換 L->r[i] 与 L->r[j] 的值 */
}
}
}
}
这段代码严格意义上说,不算是标准的冒泡排序算法,因为它不满足 “两两比较相邻记录” 的冒泡排序思想,它更应该是最最简单的交换排序而已。它的思路就是让每一个关键字,都和它后面的每一个关键字比较,如果大则交换,这样第一位置的关键字在一次循环后一定变成最小值。如图 9-3-2 所示,假设我们待排序的关键字序列是 {9, 1, 5, 8, 3, 7, 4, 6, 2},当 i=1 时,9 与 1 交换,在第一位置的 1 与后面的关键字比较都小,因此它就是最小值。当 i=2 时,第二位置先后由 9 换为 5,换为 3,换为 2,完成了第二小的数字交换。后面的数字交换类似,不再介绍。
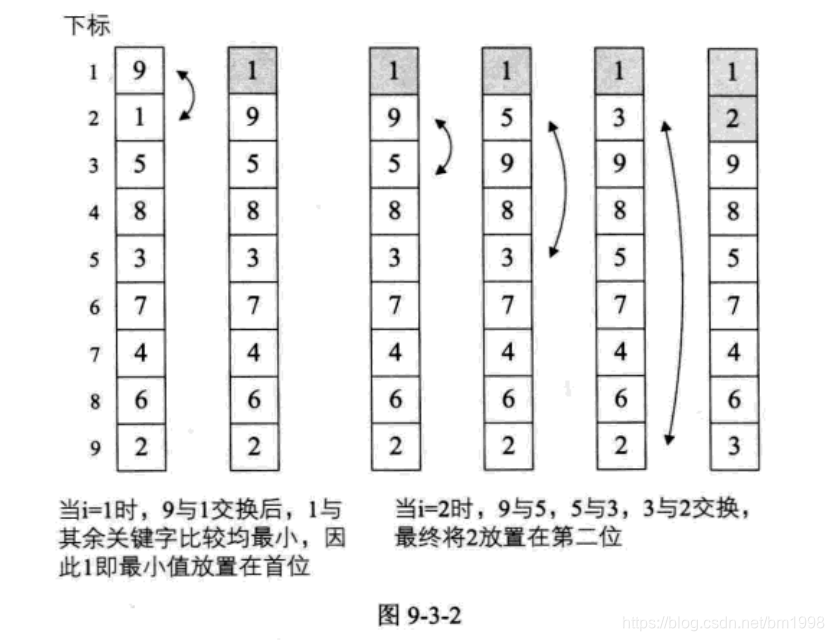
它应该算是最最容易写出的排序代码了,不过这个简单易懂的代码,却是有缺陷的。观察后发现,在排序好 1 和 2 的位置后,对其余关键字的排序没有什么帮助( 数字 3 反而还被换到了最后一位 )。也就是说,这个算法的效率是非常低的。
9.3.2 冒泡排序算法
我们来看看正宗的冒泡算法,有没有什么改进的地方。
/* 对顺序表 L 作冒泡排序 */
void BubbleSort(SqList *L)
{
int i, j;
for (i = 1; i<L->length; i++)
{
for (j = L->length - 1; j >= i; j--) /* 注意 j 是从后往前循环 */
{
if (L->r[j] > L->r[j + 1]) /* 若前者大于后者(注意这里与上一算法差异)*/
{
swap(L, j, j + 1); /* 交换 L->r[j] 与 L->r[j+1] 的值 */
}
}
}
}
依然假设我们待排序的关键字序列是 { 9, 1, 5, 8, 3, 7, 4, 6, 2} ,当 i=1 时,变量 j 由 8 反向循环到 1,逐个比较,将较小值交换到前面,直到最后找到最小值放置在了第 1 的位置。如图 9-3-3 所示,当 i=1、j=8 时,我们发现 6>2 ,因此交换了它们的位置,j=7 时,4>2 ,所以交换 …… 直到 j=2 时,因为 1<2 ,所以不交换。j=1 时,9>1 ,交换, 最终得到最小值 1 放置第一的位置。事实上,在不断循环的过程中,除了将关键字 1 放到第一的位置,我们还将关键字 2 从第九位置提到了第三的位置,显然这一算法比前面的要有进步,在上十万条数据的排序过程中,这种差异会体现出来。图中较小的数字如同气泡般慢慢浮到上面,因此就将此算法命名为冒泡算法。

当 i=2 时,变量 j 由 8 反向循环到 2 ,逐个比较,在将关键字 2 交换到第二位置的同时,也将关键字 4 和 3 有所提升。
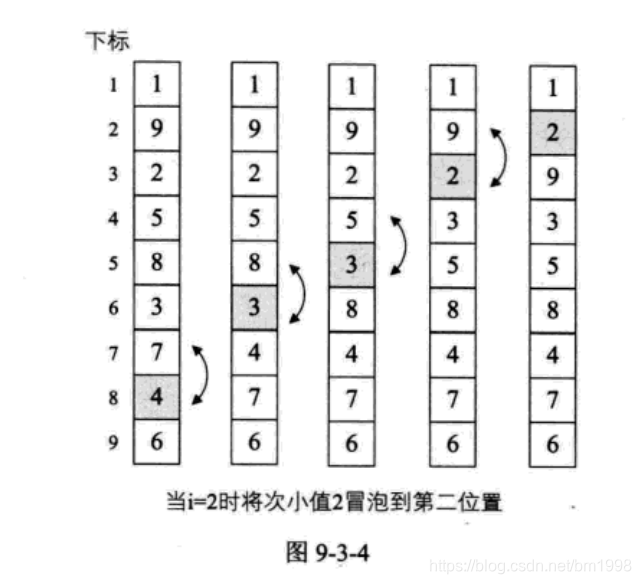
后面的数字变换很简单,这里就不在详述了。
9.3.3 冒泡排序优化
这样的冒泡程序是否还可以优化呢?答案是肯定的。试想一下,如果我们待排序的序列是 { 2, 1, 3, 4, 5, 6, 7, 8, 9 } ,也就是说,除了第一和第二的关键字需要交换外,别的都已经是正常的顺序。当 i=1 时,交换了 2 和 1 ,此时序列已经有序,但是算法仍然不依不饶地将 i=2 到 9 以及每个循环中的 j 循环都执行了一遍,尽管并没有交换数据,但是之后的大量比较还是大大地多余了,如图 9-3-5 所示。
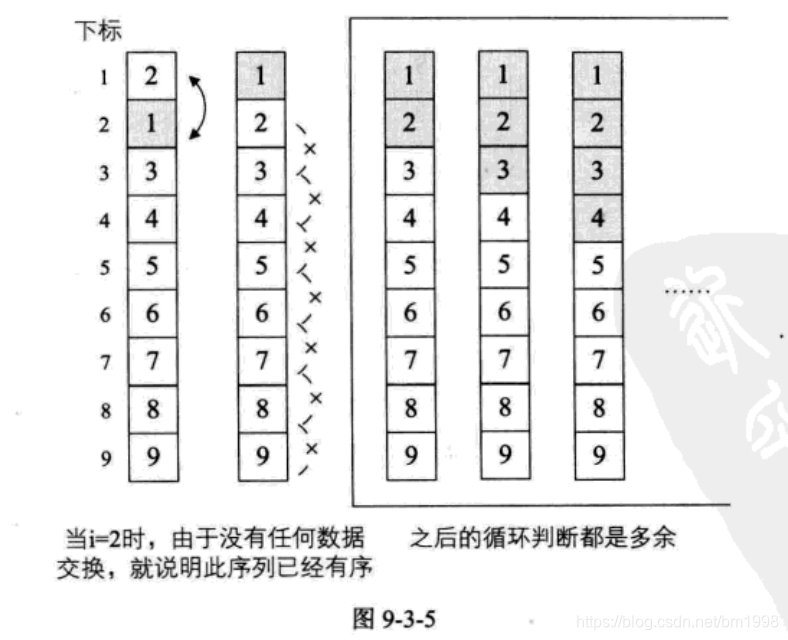
当 i=2 时,我们已经对 9 与 8,8 与 7,……,3 与 2 作了比较,没有任何数据交换,这就说明此序列已经有序,不需要再继续后面的循环判断工作了。为了实现这个想法,我们需要改进一下代码,增加一个标记变量 flag 来实现这一算法的改进。
/* 对顺序表 L 作改进冒泡算法 */
void BubbleSort2(SqList *L)
{
int i, j;
Status flag = TRUE; /* flag 用来作为标记 */
for (i = 1; i<L->length && flag; i++) /* 若 flag 为 true 则退出循环 */
{
flag = FALSE; /* 初始为 false */
for (j = L->length - 1; j >= i; j--)
{
if (L->r[j]>L->r[j + 1])
{
swap(L, j, j + 1); /* 交换 L->r[j] 与 L->r[j + l] 的值 */
flag = TRUE; /* 如果有数据交换,则 flag 为 true */
}
}
}
}
代码改动的关键就是在 i 变量的 for 循环中,增加了对 flag 是否为 true 的判断。 经过这样的改进,冒泡排序在性能上就有了一些提升,可以避免因已经有序的情况下的无意义循环判断。
9.3.4 冒泡排序复杂度分析

9.4 简单选择排序
爱炒股票短线的人,总是喜欢不断的买进卖出,想通过价差来实现盈利。但通常这种频繁操作的人,即使失误不多,也会因为操作的手续费和印花税过高而获利很少。还有一种做股票的人,他们很少出手,只是在不断的观察和判断,等到时机一到,果断买进或卖出。他们因为冷静和沉着,以及交易的次数少,而最终收益颇丰。
冒泡排序的思想就是不断的在交换,通过交换完成最终的排序,这和做股票短线频繁操作的人是类似的。我们可不可以像只有在时机非常明确到来时才出手的股票高手一样,也就是在排序时找到合适的关键字再做交换,并且只移动一次就完成相应关键字的排序定位工作呢?这就是选择排序法的初步思想。
选择排序的基本思想是每一趟在 n-i+1(i=1,2,…,n-1) 个记录中选取关键字最小的记录作为有序序列的第 i 个记录。我们这里先介绍的是简单选择排序法。
9.4.1 简单选择排序算法
简单选择排序法(Simple Selection Sort)就是通过 n-i 次关键字间的比较,从 n-i+1 个记录中选出关键字最小的记录,并和第 i (1≤i≤n) 个记录交换之。
我们来看代码。
/* 对顺序表L作简单选择排序 */
void SelectSort(SqList *L)
{
int i,j,min;
for(i=1;i<L->length;i++)
{
min = i; /* 将当前下标定义为最小值下标 */
for (j = i+1;j<=L->length;j++) /* 循环之后的数据 */
{
if (L->r[min]>L->r[j]) /* 如果有小于当前最小值的关键字 */
min = j; /* 将此关键字的下标赋值给min */
}
if(i!=min) /* 若min不等于i,说明找到最小值,交换 */
swap(L,i,min); /* 交换L->r[i]与L->r[min]的值 */
}
}
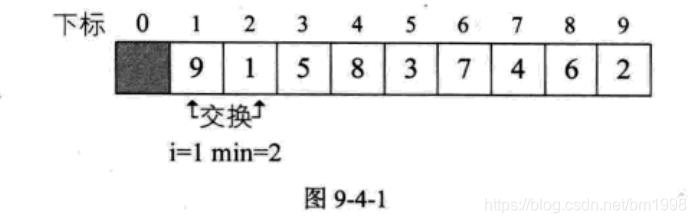
代码应该说不难理解,针对待排序的关键字序列是 { 9, 1, 5, 8, 3, 7, 4, 6, 2 } ,对 i 从 1 循环到 8 。当 i=1 时,L.r[i]=9 ,min 开始是 1 ,然后与 j=2 到 9 比较 L.r[min] 与 L.r[j] 的大小,因为 j=2 时最小,所以 min=2 。最终交换了 L.r[2] 与 L.r[1] 的值。如图 9-4-1 所示,注意,这里比较了 8 次,却只交换数据操作一次。
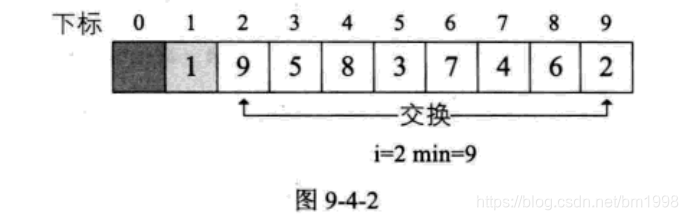
当 i=2 时,L.r[i]=9 ,min 开始是 2,经过比较后,min=9 ,交换 L.r[min] 与 L.r[i] 的值。如图 9-4-2 所示,这样就找到了第二位置的关键字。
当 i=3 时,L.r[i]=5,min 开始是 3,经过比较后,min=5,交换 L.r[min] 与 L.r[i] 的值。如图 9-4-3 所示。

之后的数据比较和交换完全雷同,最多经过 8 次交换,就可完成排序工作。
9.4.2 简单选择排序复杂度分析

9.5 直接插入排序
扑克牌是我们几乎每个人都可能玩过的游戏。最基本的扑克玩法都是一边摸牌, 一边理牌。假如我们拿到了这样一手牌,如图 9-5-1 所示。啊,似乎是同花顺呀,别急,我们得理一理顺序才知道是否是真的同花顺。请问,如果是你,应该如何理牌呢?
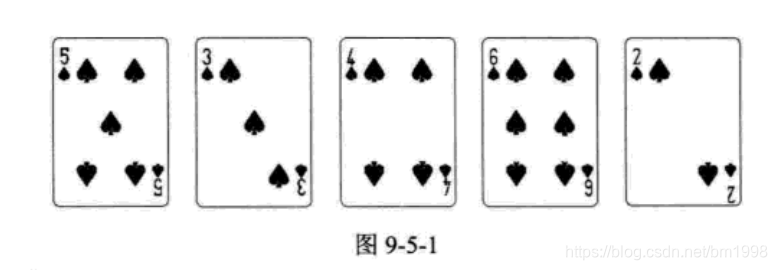
应该说,哪怕你是第一次玩扑克牌,只要认识这些数字,理牌的方法都是不用教 的。将 3 和 4 移动到 5 的左侧,再将 2 移动到最左侧,顺序就算是理好了。这里,我们的理牌方法,就是直接插入排序法。
9.5.1 直接插入排序算法
直接插入排序( Straight Insertion Sort )的基本操作是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增 1 的有序表。
顾名思义,从名称上也可以知道它是一种插入排序的方法。我们来看直接插入排序法的代码。
/* 对顺序表 L 作直接插入排序 */
void InsertSort(SqList *L)
{
int i, j;
for (i = 2; i <= L->length; i++)
{
if (L->r[i]<L->r[i - 1]) /* 需将 L->r[i] 插入有序子表 */
{
L->r[0] = L->r[i]; /* 设置哨兵 */
for (j = i - 1; L->r[j]>L->r[0]; j--)
{
L->r[j + 1] = L->r[j]; /* 记录后移 */
}
L->r[j + 1] = L->r[0]; /* 插入到正确位置 */
}
}
}
-
程序开始运行,此时我们传入的 SqList 参数的值为 length=6 ,r[6]= {0, 5, 3, 4, 6, 2 } ,其中 r[0]=0 将用于后面起到哨兵的作用。
-
第 5〜16 行就是排序的主循环。i 从 2 开始的意思是我们假设 r[1]=5 已经放好位置,后面的牌其实就是插入到它的左侧还是右侧的问题。
-
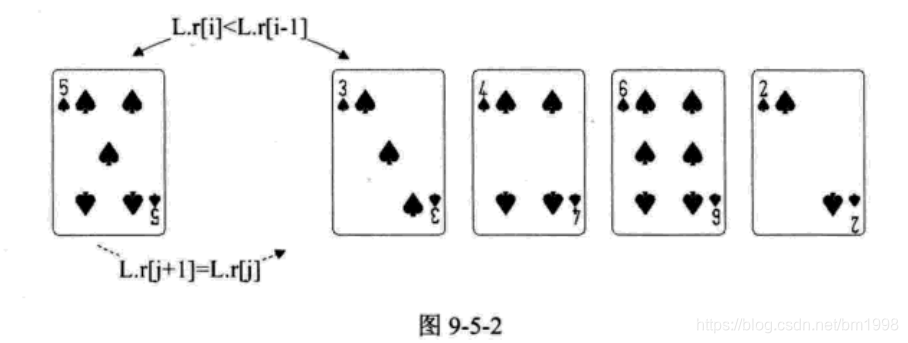
第 7 行,此时 i=2 ,L.r[i]=3 比 L.r[i-1]=5 要小,因此执行第 9〜14 行的操作。第 9 行,我们将 L.r[0] 赋值为 L.r[i]=3 的目的是为了起到第 10〜13 行的循环终止的判断依如图 9-5-2 所示。图中下方的虚线箭头,就是第 12 行, L.r[j-1]=L.r[j] 的过程,将 5 右移一位。
-
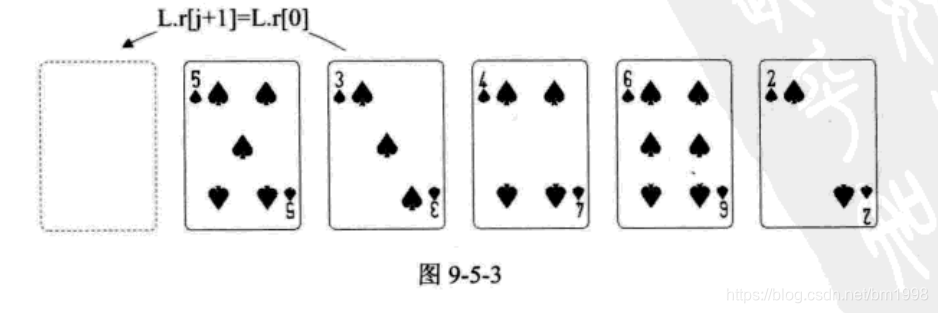
此时,第 12 行就是在移动完成后,空出了空位,然后第 14 行 L.r[j+1]=L.r[0] ,将哨兵的 3 赋值给 j=0 时的 L.r[j+1] ,也就是说,将扑克牌 3 放置到 L.r[1] 的位置,如图 9-5-3 所示。
-
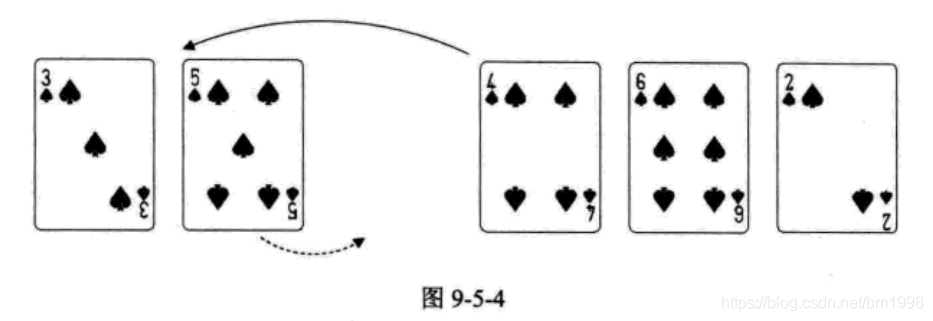
继续循环,第 7 行,因为此时 i=3 , L.r[i]=4 比 L.r[i-1]=5 要小,因此执行第 9〜14 行的操作,将 5 再右移一位,将 4 放置到当前 5 所在位置,如图 9-5-4 所示。
-
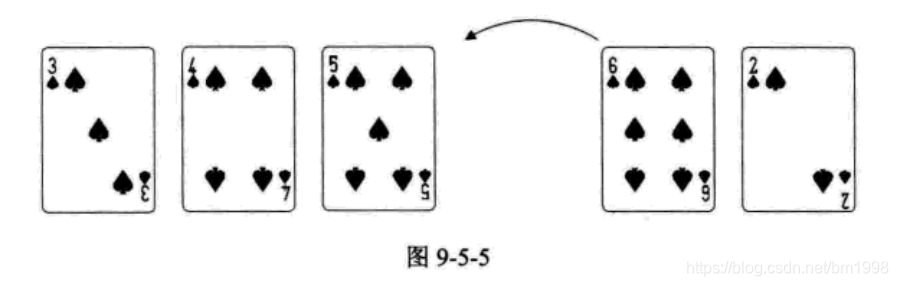
再次循环,此时 i=4 。因为 L.r[i]=6 比 L.r[i-1]=5 要大,于是第9〜14 行代码不执行,此时前三张牌的位置没有变化,如图 9-5-5 所示。
-
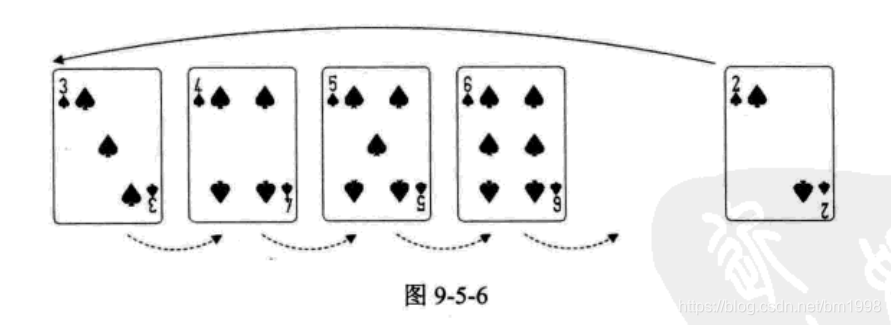
再次循环,此时 i=5 ,因为 L.r[i]=2 比 L.r[i-1]=6 要小,因此执行第 9〜14 行的操作。由于 6、5、4、3 都比 2 小,它们都将右移一位,将 2 放置到当前 3 所在位置。如图 9-5-6 所示。此时我们的排序也就完成了。
9.5.2 直接插入排序复杂度分析
