import pandas as pd
import numpy as np
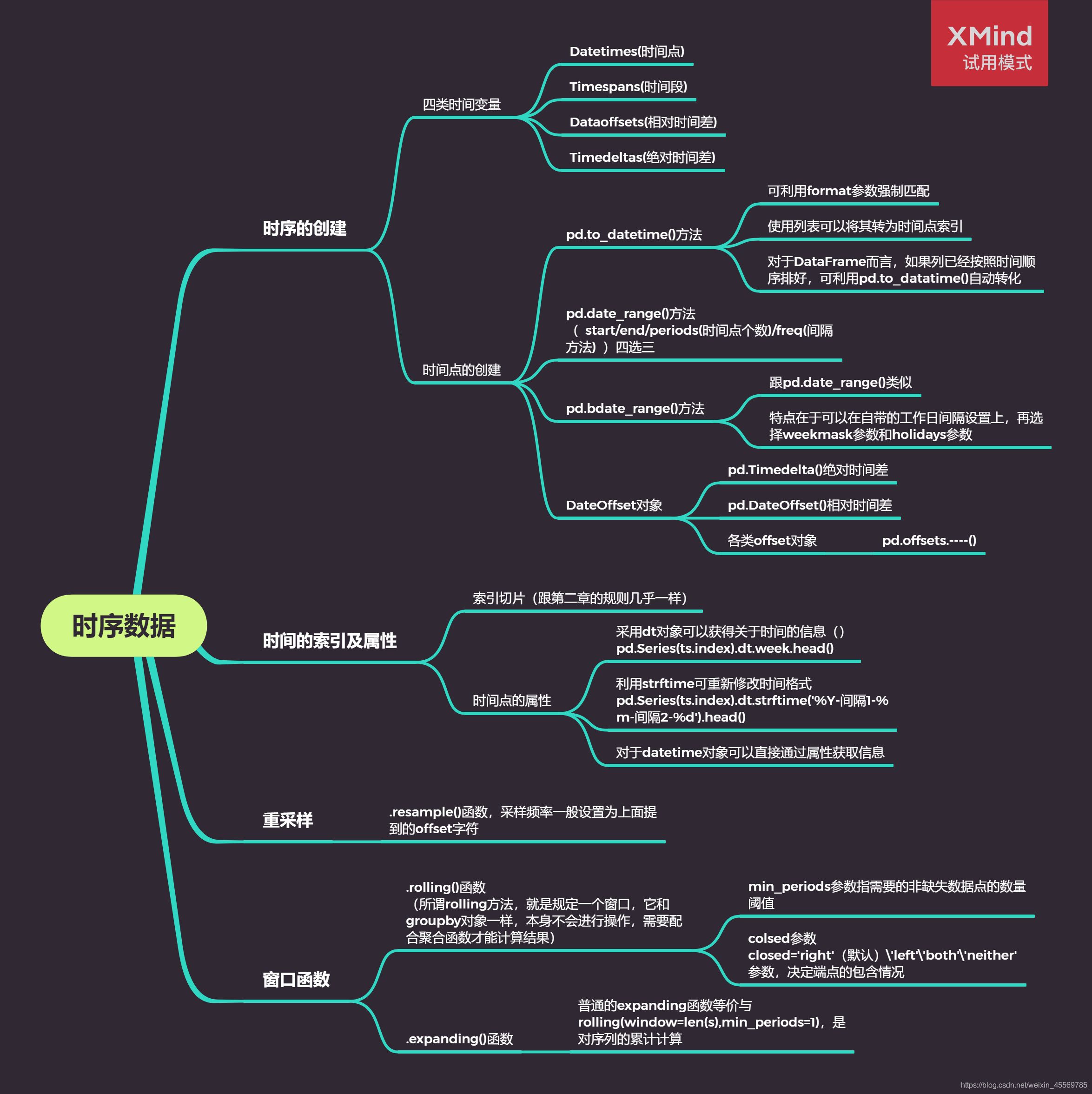
名称
描述
元素类型
创建方式
① Date times(时间点/时刻)
描述特定日期或时间点
Timestamp
to_datetime或date_range
② Time spans(时间段/时期)
由时间点定义的一段时期
Period
Period或period_range
③ Date offsets(相对时间差)
一段时间的相对大小(与夏/冬令时无关)
DateOffset
DateOffset
④ Time deltas(绝对时间差)
一段时间的绝对大小(与夏/冬令时有关)
Timedelta
to_timedelta或timedelta_range
pd. to_datetime( '2020.1.1' )
pd. to_datetime( '2020 1.1' )
pd. to_datetime( '2020 1 1' )
pd. to_datetime( '2020 1-1' )
pd. to_datetime( '2020-1 1' )
pd. to_datetime( '2020-1-1' )
pd. to_datetime( '2020/1/1' )
pd. to_datetime( '1.1.2020' )
pd. to_datetime( '1.1 2020' )
pd. to_datetime( '1 1 2020' )
pd. to_datetime( '1 1-2020' )
pd. to_datetime( '1-1 2020' )
pd. to_datetime( '1-1-2020' )
pd. to_datetime( '1/1/2020' )
pd. to_datetime( '20200101' )
pd. to_datetime( '2020.0101' )
Timestamp('2020-01-01 00:00:00')
pd. to_datetime( '2020\\1\\1' , format = '%Y\\%m\\%d' )
pd. to_datetime( '2020`1`1' , format = '%Y`%m`%d' )
pd. to_datetime( '2020.1 1' , format = '%Y.%m %d' )
pd. to_datetime( '1 1.2020' , format = '%d %m.%Y' )
Timestamp('2020-01-01 00:00:00')
pd. Series( range ( 2 ) , index= pd. to_datetime( [ '2020/1/1' , '2020/1/2' ] ) )
2020-01-01 0
2020-01-02 1
dtype: int64
type ( pd. to_datetime( [ '2020/1/1' , '2020/1/2' ] ) )
pandas.core.indexes.datetimes.DatetimeIndex
df = pd. DataFrame( { 'year' : [ 2020 , 2020 ] , 'month' : [ 1 , 1 ] , 'day' : [ 1 , 2 ] } )
pd. to_datetime( df)
0 2020-01-01
1 2020-01-02
dtype: datetime64[ns]
pd. to_datetime( '2020/1/1 00:00:00.123456789' )
Timestamp('2020-01-01 00:00:00.123456789')
pd. Timestamp. min
Timestamp('1677-09-21 00:12:43.145225')
pd. Timestamp. max
Timestamp('2262-04-11 23:47:16.854775807')
pd. date_range( start= '2020/1/1' , end= '2020/1/10' , periods= 3 )
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-05 12:00:00',
'2020-01-10 00:00:00'],
dtype='datetime64[ns]', freq=None)
pd. date_range( start= '2020/1/1' , end= '2020/1/10' , freq= 'D' )
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10'],
dtype='datetime64[ns]', freq='D')
pd. date_range( start= '2020/1/1' , periods= 3 , freq= 'D' )
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03'], dtype='datetime64[ns]', freq='D')
pd. date_range( end= '2020/1/3' , periods= 3 , freq= 'D' )
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03'], dtype='datetime64[ns]', freq='D')
这里
符号
D/B
W
M/Q/Y
BM/BQ/BY
MS/QS/YS
BMS/BQS/BYS
H
T
S
描述
日/工作日
周
月末
月/季/年末日
月/季/年末工作日
月/季/年初日
月/季/年初工作日
小时
分钟
pd. date_range( start= '2020/1/1' , periods= 3 , freq= 'T' )
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-01 00:01:00',
'2020-01-01 00:02:00'],
dtype='datetime64[ns]', freq='T')
pd. date_range( start= '2020/1/1' , periods= 3 , freq= 'M' )
DatetimeIndex(['2020-01-31', '2020-02-29', '2020-03-31'], dtype='datetime64[ns]', freq='M')
pd. date_range( start= '2020/1/1' , periods= 3 , freq= 'BYS' )
DatetimeIndex(['2020-01-01', '2021-01-01', '2022-01-03'], dtype='datetime64[ns]', freq='BAS-JAN')
weekmask = 'Mon Tue Fri'
holidays = [ pd. Timestamp( '2020/1/%s' % i) for i in range ( 7 , 13 ) ]
pd. bdate_range( start= '2020-1-1' , end= '2020-1-15' , freq= 'C' , weekmask= weekmask, holidays= holidays)
DatetimeIndex(['2020-01-03', '2020-01-06', '2020-01-13', '2020-01-14'], dtype='datetime64[ns]', freq='C')
ts = pd. Timestamp( '2020-3-29 01:00:00' , tz= 'Europe/Helsinki' )
ts + pd. Timedelta( days= 1 )
Timestamp('2020-03-30 02:00:00+0300', tz='Europe/Helsinki')
ts + pd. DateOffset( days= 1 )
Timestamp('2020-03-30 01:00:00+0300', tz='Europe/Helsinki')
ts = pd. Timestamp( '2020-3-29 01:00:00' )
ts + pd. Timedelta( days= 1 )
Timestamp('2020-03-30 01:00:00')
ts + pd. DateOffset( days= 1 )
Timestamp('2020-03-30 01:00:00')
pd. Timestamp( '2020-01-01' ) + pd. DateOffset( minutes= 20 ) - pd. DateOffset( weeks= 2 )
Timestamp('2019-12-18 00:20:00')
freq
D/B
W
(B)M/(B)Q/(B)Y
(B)MS/(B)QS/(B)YS
H
T
S
C
offset
DateOffset/BDay
Week
(B)MonthEnd/(B)QuarterEnd/(B)YearEnd
(B)MonthBegin/(B)QuarterBegin/(B)YearBegin
Hour
Minute
Second
CDay(定制工作日)
pd. Timestamp( '2020-01-01' ) + pd. offsets. Week( 2 )
Timestamp('2020-01-15 00:00:00')
pd. Timestamp( '2020-01-01' ) + pd. offsets. BQuarterBegin( 1 )
Timestamp('2020-03-02 00:00:00')
pd. Series( pd. offsets. BYearBegin( 3 ) . apply ( i) for i in pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) )
0 2023-01-02
1 2024-01-01
2 2025-01-01
dtype: datetime64[ns]
pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) + pd. offsets. BYearBegin( 3 )
DatetimeIndex(['2023-01-02', '2024-01-01', '2025-01-01'], dtype='datetime64[ns]', freq='A-DEC')
pd. date_range( '20200105' , periods= 3 , freq= 'D' )
DatetimeIndex(['2020-01-05', '2020-01-06', '2020-01-07'], dtype='datetime64[ns]', freq='D')
pd. Series( pd. offsets. CDay( 3 , weekmask= 'Wed Fri' , holidays= '20200116' ) . apply ( i)
for i in pd. date_range( '20200105' , periods= 4 , freq= 'D' ) )
0 2020-01-15
1 2020-01-15
2 2020-01-15
3 2020-01-17
dtype: datetime64[ns]
因为刚好holidays='2020010’是周五
rng = pd. date_range( '2020' , '2021' , freq= 'W' )
ts = pd. Series( np. random. randn( len ( rng) ) , index= rng)
ts. head( )
2020-01-05 -0.275349
2020-01-12 2.359218
2020-01-19 -0.447633
2020-01-26 -0.479830
2020-02-02 0.517587
Freq: W-SUN, dtype: float64
ts[ '2020-01-26' ]
-0.47982974619679947
ts[ '2020-01-26' : '20200726' ] . head( )
2020-01-26 -0.479830
2020-02-02 0.517587
2020-02-09 -0.575879
2020-02-16 0.952187
2020-02-23 0.554098
Freq: W-SUN, dtype: float64
ts[ '2020-7' ] . head( )
2020-07-05 -0.088912
2020-07-12 0.153852
2020-07-19 1.670324
2020-07-26 0.568214
Freq: W-SUN, dtype: float64
ts[ '2011-1' : '20200726' ] . head( )
2020-01-05 -0.275349
2020-01-12 2.359218
2020-01-19 -0.447633
2020-01-26 -0.479830
2020-02-02 0.517587
Freq: W-SUN, dtype: float64
pd. Series( ts. index) . dt. week. head( )
0 1
1 2
2 3
3 4
4 5
dtype: int64
pd. Series( ts. index) . dt. day. head( )
0 5
1 12
2 19
3 26
4 2
dtype: int64
pd. Series( ts. index) . dt. strftime( '%Y-间隔1-%m-间隔2-%d' ) . head( )
0 2020-间隔1-01-间隔2-05
1 2020-间隔1-01-间隔2-12
2 2020-间隔1-01-间隔2-19
3 2020-间隔1-01-间隔2-26
4 2020-间隔1-02-间隔2-02
dtype: object
pd. date_range( '2020' , '2021' , freq= 'W' ) . month
Int64Index([ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4,
5, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7, 7, 7, 8, 8, 8, 8,
8, 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 11, 12, 12, 12,
12],
dtype='int64')
pd. date_range( '2020' , '2021' , freq= 'W' ) . weekday
Int64Index([6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6],
dtype='int64')
df_r = pd. DataFrame( np. random. randn( 1000 , 3 ) , index= pd. date_range( '1/1/2020' , freq= 'S' , periods= 1000 ) ,
columns= [ 'A' , 'B' , 'C' ] )
df_r. head( )
A
B
C
2020-01-01 00:00:00
-1.343925
1.184322
-0.540354
2020-01-01 00:00:01
1.003050
0.343605
1.541366
2020-01-01 00:00:02
-1.955152
-1.223350
-0.447216
2020-01-01 00:00:03
-1.164559
0.220829
2.008356
2020-01-01 00:00:04
-0.662060
0.339157
0.666090
r = df_r. resample( '3min' )
r
<pandas.core.resample.DatetimeIndexResampler object at 0x0000020F9A7D6F98>
r. sum ( )
A
B
C
2020-01-01 00:00:00
-8.772685
-27.074716
2.134617
2020-01-01 00:03:00
3.822484
8.912459
-15.448955
2020-01-01 00:06:00
2.744722
-8.055139
-11.364361
2020-01-01 00:09:00
4.655620
-11.524496
-10.536002
2020-01-01 00:12:00
-10.546811
5.063887
11.776490
2020-01-01 00:15:00
8.795150
-12.828809
-8.393950
df_r2 = pd. DataFrame( np. random. randn( 200 , 3 ) , index= pd. date_range( '1/1/2020' , freq= 'D' , periods= 200 ) ,
columns= [ 'A' , 'B' , 'C' ] )
r = df_r2. resample( 'CBMS' )
r. sum ( )
A
B
C
2020-01-01
5.278470
1.688588
5.904806
2020-02-03
-3.581797
7.515267
0.205308
2020-03-02
-5.021605
-4.441066
5.433917
2020-04-01
0.671702
3.840042
4.922487
2020-05-01
4.613352
9.702408
-4.928112
2020-06-01
-0.598191
7.387416
8.716921
2020-07-01
-0.327200
-1.577507
-3.956079
r = df_r. resample( '3T' )
r[ 'A' ] . mean( )
2020-01-01 00:00:00 -0.048737
2020-01-01 00:03:00 0.021236
2020-01-01 00:06:00 0.015248
2020-01-01 00:09:00 0.025865
2020-01-01 00:12:00 -0.058593
2020-01-01 00:15:00 0.087952
Freq: 3T, Name: A, dtype: float64
r[ 'A' ] . agg( [ np. sum , np. mean, np. std] )
sum
mean
std
2020-01-01 00:00:00
-8.772685
-0.048737
0.939954
2020-01-01 00:03:00
3.822484
0.021236
1.004048
2020-01-01 00:06:00
2.744722
0.015248
1.018865
2020-01-01 00:09:00
4.655620
0.025865
1.020881
2020-01-01 00:12:00
-10.546811
-0.058593
0.954328
2020-01-01 00:15:00
8.795150
0.087952
1.199379
r. agg( { 'A' : np. sum , 'B' : lambda x: max ( x) - min ( x) } )
A
B
2020-01-01 00:00:00
-8.772685
4.950006
2020-01-01 00:03:00
3.822484
5.711679
2020-01-01 00:06:00
2.744722
6.923072
2020-01-01 00:09:00
4.655620
6.370589
2020-01-01 00:12:00
-10.546811
4.544878
2020-01-01 00:15:00
8.795150
5.244546
small = pd. Series( range ( 6 ) , index= pd. to_datetime( [ '2020-01-01 00:00:00' , '2020-01-01 00:30:00'
, '2020-01-01 00:31:00' , '2020-01-01 01:00:00'
, '2020-01-01 03:00:00' , '2020-01-01 03:05:00' ] ) )
resampled = small. resample( 'H' )
for name, group in resampled:
print ( "Group: " , name)
print ( "-" * 27 )
print ( group, end= "\n\n" )
Group: 2020-01-01 00:00:00
---------------------------
2020-01-01 00:00:00 0
2020-01-01 00:30:00 1
2020-01-01 00:31:00 2
dtype: int64
Group: 2020-01-01 01:00:00
---------------------------
2020-01-01 01:00:00 3
dtype: int64
Group: 2020-01-01 02:00:00
---------------------------
Series([], dtype: int64)
Group: 2020-01-01 03:00:00
---------------------------
2020-01-01 03:00:00 4
2020-01-01 03:05:00 5
dtype: int64
s = pd. Series( np. random. randn( 1000 ) , index= pd. date_range( '1/1/2020' , periods= 1000 ) )
s. head( )
2020-01-01 0.305974
2020-01-02 0.185221
2020-01-03 -0.646472
2020-01-04 -1.430293
2020-01-05 -0.956094
Freq: D, dtype: float64
s. rolling( window= 50 )
Rolling [window=50,center=False,axis=0]
s. rolling( window= 50 ) . mean( )
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 NaN
2020-01-05 NaN
...
2022-09-22 0.160743
2022-09-23 0.136296
2022-09-24 0.147523
2022-09-25 0.133087
2022-09-26 0.130841
Freq: D, Length: 1000, dtype: float64
s. rolling( window= 50 , min_periods= 3 ) . mean( ) . head( )
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 -0.051759
2020-01-04 -0.396392
2020-01-05 -0.508333
Freq: D, dtype: float64
s. rolling( window= 50 , min_periods= 3 ) . apply ( lambda x: x. std( ) / x. mean( ) ) . head( )
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 -10.018809
2020-01-04 -2.040720
2020-01-05 -1.463460
Freq: D, dtype: float64
s. rolling( '15D' ) . mean( ) . head( )
2020-01-01 0.305974
2020-01-02 0.245598
2020-01-03 -0.051759
2020-01-04 -0.396392
2020-01-05 -0.508333
Freq: D, dtype: float64
s. rolling( '15D' , closed= 'right' ) . sum ( ) . head( )
2020-01-01 0.305974
2020-01-02 0.491195
2020-01-03 -0.155277
2020-01-04 -1.585570
2020-01-05 -2.541664
Freq: D, dtype: float64
s. rolling( window= len ( s) , min_periods= 1 ) . sum ( ) . head( )
2020-01-01 0.305974
2020-01-02 0.491195
2020-01-03 -0.155277
2020-01-04 -1.585570
2020-01-05 -2.541664
Freq: D, dtype: float64
s. expanding( ) . sum ( ) . head( )
2020-01-01 0.305974
2020-01-02 0.491195
2020-01-03 -0.155277
2020-01-04 -1.585570
2020-01-05 -2.541664
Freq: D, dtype: float64
s. expanding( ) . apply ( lambda x: sum ( x) ) . head( )
2020-01-01 0.305974
2020-01-02 0.491195
2020-01-03 -0.155277
2020-01-04 -1.585570
2020-01-05 -2.541664
Freq: D, dtype: float64
s. cumsum( ) . head( )
2020-01-01 0.305974
2020-01-02 0.491195
2020-01-03 -0.155277
2020-01-04 -1.585570
2020-01-05 -2.541664
Freq: D, dtype: float64
s. cumsum( ) . head( )
2020-01-01 0.305974
2020-01-02 0.491195
2020-01-03 -0.155277
2020-01-04 -1.585570
2020-01-05 -2.541664
Freq: D, dtype: float64
s. shift( 2 ) . head( )
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 0.305974
2020-01-04 0.185221
2020-01-05 -0.646472
Freq: D, dtype: float64
s. diff( 3 ) . head( )
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 -1.736267
2020-01-05 -1.141316
Freq: D, dtype: float64
s. pct_change( 3 ) . head( )
2020-01-01 NaN
2020-01-02 NaN
2020-01-03 NaN
2020-01-04 -5.674559
2020-01-05 -6.161897
Freq: D, dtype: float64
pd. Series( pd. offsets. BYearBegin( 3 ) . apply ( i) for i in pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) )
0 2023-01-02
1 2024-01-01
2 2025-01-01
dtype: datetime64[ns]
pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) + pd. offsets. BYearBegin( 3 )
DatetimeIndex(['2023-01-02', '2024-01-01', '2025-01-01'], dtype='datetime64[ns]', freq='A-DEC')
pd. Timestamp( '2020-01-01' ) + pd. offsets. Second( 0 )
Timestamp('2020-01-01 00:00:00')
pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) + pd. offsets. Second( 1 )
DatetimeIndex(['2020-12-31 00:00:01', '2021-12-31 00:00:01',
'2022-12-31 00:00:01'],
dtype='datetime64[ns]', freq='A-DEC')
pd. Series( pd. offsets. Second( 1 ) . apply ( i) for i in pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) )
0 2020-12-31 00:00:01
1 2021-12-31 00:00:01
2 2022-12-31 00:00:01
dtype: datetime64[ns]
个人觉得可以单独索引出再处理时间内的时间点,进行处理,对于超出处理时间的时间点,我们可以使用apply函数对其时间进行长尾截断,或者用其他的值来替换都可以
pd. Series( pd. offsets. Second( 1 ) . apply ( i) for i in pd. date_range( '20200101' , periods= 3 , freq= 'Y' ) ) . apply ( lambda x: x- pd. offsets. Second( 1 ) if x> ( pd. Timestamp( '2021-01-01' ) + pd. offsets. Second( 1 ) ) else x)
0 2020-12-31 00:00:01
1 2021-12-31 00:00:00
2 2022-12-31 00:00:00
dtype: datetime64[ns]
pd. date_range( '20200101' , periods= 3 , freq= 'D' ) . min ( )
Timestamp('2020-01-01 00:00:00', freq='D')
a= pd. to_datetime( [ '2020/1/1' , '2020/1/3' , '2020/1/6' ] )
pd. Series( pd. date_range( start= a. min ( ) , end= a. max ( ) , freq= 'D' ) ) . apply ( lambda x: x if x not in a else None ) . dropna( )
1 2020-01-02
3 2020-01-04
4 2020-01-05
dtype: datetime64[ns]
pd. read_csv( 'data/time_series_one.csv' ) . head( )
日期
销售额
0
2017/2/17
2154
1
2017/2/18
2095
2
2017/2/19
3459
3
2017/2/20
2198
4
2017/2/21
2413
== 这周考试周只能先去复习数据结构了,等考完试一定会来补上。==