问题
【问题一】 如何对date_range进行批量加帧操作或对某一时间段加大时间戳密度?
pd.date_range().append()
【问题二】 如何批量增加TimeStamp的精度?
【问题三】 对于超出处理时间的时间点,是否真的完全没有处理方法?
【问题四】 给定一组非连续的日期,怎么快速找出位于其最大日期和最小日期之间,且没有出现在该组日期中的日期?
练习
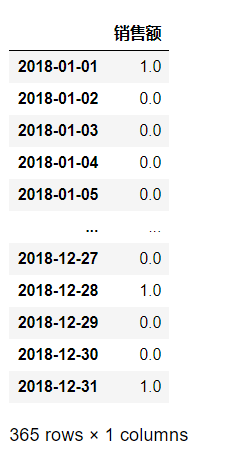
【练习一】 现有一份关于某超市牛奶销售额的时间序列数据,请完成下列问题:
(a)销售额出现最大值的是星期几?(提示:利用dayofweek函数)
# parse_dates可以解析日期
df_1 = pd.read_csv('../data/time_series_one.csv', parse_dates=['日期'])
df_1
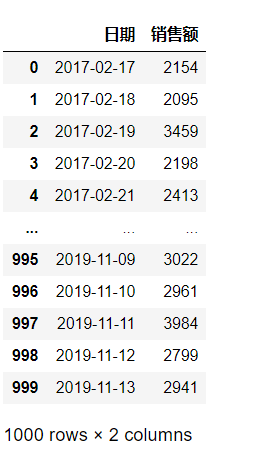
df_1.loc[df_1['销售额'].idxmax()]
日期 2019-09-01 00:00:00
销售额 4333
Name: 926, dtype: object
pd.Series(pd.to_datetime('2019-9-1')).dt.dayofweek
# 这里说明一下,在dayofweek中6表示的是星期天,0表示的是星期一,当然这里的0是索引不是表示星期一
0 6
dtype: int64
(b)计算除去春节、国庆、五一节假日的月度销售总额
holiday = pd.date_range(start='20170501', end='20170503').append(
pd.date_range(start='20171001', end='20171007')).append(
pd.date_range(start='20180215', end='20180221')).append(
pd.date_range(start='20180501', end='20180503')).append(
pd.date_range(start='20181001', end='20181007')).append(
pd.date_range(start='20190204', end='20190224')).append(
pd.date_range(start='20190501', end='20190503')).append(
pd.date_range(start='20191001', end='20191007'))
# MS表示月初
df_1.loc[~df_1['日期'].isin(holiday)].set_index('日期').resample('MS').sum()
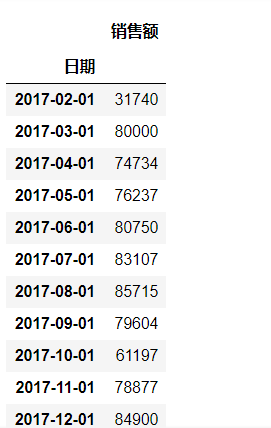
(c)按季度计算周末(周六和周日)的销量总额
date_weekday = pd.date_range('2017-2-17', end='2019-11-13', freq='B')
df_1.loc[~df_1['日期'].isin(date_weekday)].set_index('日期').resample('QS').sum()
扫描二维码关注公众号,回复:
13131606 查看本文章

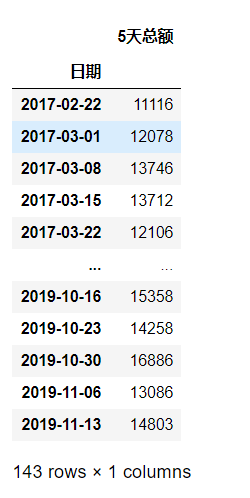
(d)从最后一天开始算起,跳过周六和周一,以5天为一个时间单位向前计算销售总和
df_temp = df_1.loc[~df_1['日期'].dt.dayofweek.isin([5, 0])].set_index('日期').iloc[::-1]
# L_temp是用来做分类的,date_temp是用来记录日期的
L_temp, date_temp = [], [0]*len(df_temp)
for i in range(df_temp.shape[0] // 5):
L_temp.extend([i]*5)
# 剩下的补上
L_temp.extend([df_temp.shape[0] // 5] * (df_temp.shape[0] - len(L_temp)))
date_temp = pd.Series(i%5 == 0 for i in range(len(df_temp)))
df_temp['num'] = L_temp
result = pd.DataFrame({
'5天总额':df_temp.groupby('num')['销售额'].sum().values}, index=df_temp.reset_index()[date_temp]['日期']).iloc[::-1]
result
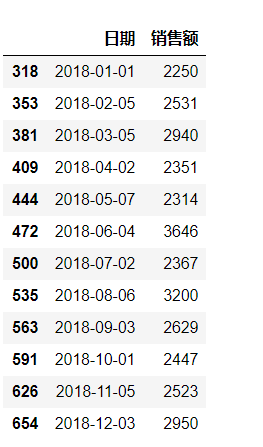
(e)假设现在发现数据有误,所有同一周里的周一与周五的销售额记录颠倒了,请计算2018年中每月第一个周一的销售额(如果该周没有周一或周五的记录就保持不动)
df_mon = df_1.loc[df_1['日期'].dt.dayofweek.isin([0])]
df_fri = df_1.loc[df_1['日期'].dt.dayofweek.isin([4])]
# 先验知识
df_mon.drop(index=997, inplace=True)
df_fri.drop(index=0, inplace=True)
df_fri['销售额'], df_mon['销售额'] = list(df_mon['销售额']), list(df_fri['销售额'])
df_1.loc[list(df_mon.index), '销售额'] = list(df_mon['销售额'])
df_1.loc[list(df_fri.index), '销售额'] = list(df_fri['销售额'])
df_temp = df_1.copy()
df_temp.loc[df_temp[df_temp['日期'].dt.year==2018]['日期'][
df_temp[df_temp['日期'].dt.year==2018]['日期'].apply(
lambda x:True if datetime.strptime(str(x).split()[0],'%Y-%m-%d').weekday() == 0
and 1 <= datetime.strptime(str(x).split()[0],'%Y-%m-%d').day <= 7 else False)].index,:]
【练习二】 继续使用上一题的数据,请完成下列问题:
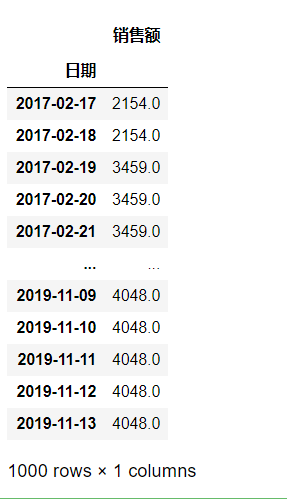
(a)以50天为窗口计算滑窗均值和滑窗最大值(min_periods设为1)
df_2 = pd.read_csv('../data/time_series_one.csv', index_col=['日期'], parse_dates=['日期'])
df_2.rolling(window=50, min_periods=1).mean()

df_2.rolling(window=50, min_periods=1).max()
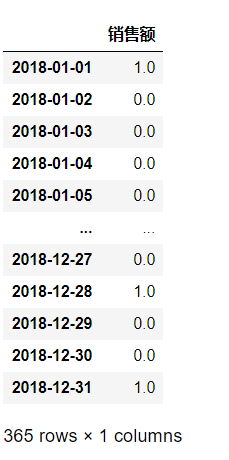
(b)现在有如下规则:若当天销售额超过向前5天的均值,则记为1,否则记为0,请给出2018年相应的计算结果
def f(x):
if len(x) == 6:
return 1 if x[-1] > np.mean(x[:-1]) else 0
else:
return 0
result_b = df_2.loc[pd.date_range(start='2017-12-27', end='2018-12-31')].rolling(window=6, min_periods=1).agg(f)[5:]
result_b
(c)将©中的“向前5天”改为“向前非周末5天”,请再次计算结果¶
def f1(x):
if len(x) == 8:
return 1 if x[-1] > np.mean(x[:-1].loc[pd.Series([False if i in [5, 6] else True for i in x[:-1].index.dayofweek], index=x[:-1].index)]) else 0
else:
return 0
result_c = df_2.loc[pd.date_range(start='2017-12-25', end='2018-12-31')].rolling(window=8, min_periods=1).agg(f1)[7:]
result_c