pandas的groupby功能,可以计算 分组统计和生成透视表,可对数据集进行灵活的切片、切块、摘要等操作
GroupBy技术
“split-apply-comebine”(拆分-应用-合并)
import numpy as np
from pandas import DataFrame,Series
df=DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
|
data1 |
data2 |
key1 |
key2 |
| 0 |
1.160760 |
0.360555 |
a |
one |
| 1 |
-0.992606 |
-0.120562 |
a |
two |
| 2 |
-0.616727 |
0.856179 |
b |
one |
| 3 |
-1.921879 |
-0.690846 |
b |
two |
| 4 |
-0.458540 |
-0.093610 |
a |
one |
grouped=df['data1'].groupby(df['key1'])
grouped
grouped.mean()
key1 a -0.096796 b -1.269303 Name: data1, dtype: float64
means=df['data1'].groupby([df['key1'],df['key2']]).mean()
means
key1 key2 a one 0.351110 two -0.992606 b one -0.616727 two -1.921879 Name: data1, dtype: float64
means.unstack()
| key2 |
one |
two |
| key1 |
|
|
| a |
0.351110 |
-0.992606 |
| b |
-0.616727 |
-1.921879 |
states=np.array(['Ohio','Colifornia','Colifornia','Ohio','Ohio'])
years=np.array([2005,2005,2006,2005,2006])
df['data1'].groupby([states,years]).mean()
Colifornia 2005 -0.992606 2006 -0.616727 Ohio 2005 -0.380560 2006 -0.458540 Name: data1, dtype: float64
df.groupby(['key1']).mean()
|
data1 |
data2 |
| key1 |
|
|
| a |
-0.096796 |
0.048794 |
| b |
-1.269303 |
0.082666 |
df.groupby(['key1','key2']).mean()
|
|
data1 |
data2 |
| key1 |
key2 |
|
|
| a |
one |
0.351110 |
0.133473 |
| two |
-0.992606 |
-0.120562 |
| b |
one |
-0.616727 |
0.856179 |
| two |
-1.921879 |
-0.690846 |
df.groupby(['key1','key2']).size()
key1 key2 a one 2 two 1 b one 1 two 1 dtype: int64
对分组进行迭代
for name,group in df.groupby('key1'):
print(name)
print(group)
a data1 data2 key1 key2 0 1.160760 0.360555 a one 1 -0.992606 -0.120562 a two 4 -0.458540 -0.093610 a one b data1 data2 key1 key2 2 -0.616727 0.856179 b one 3 -1.921879 -0.690846 b two
for (k1,k2),group in df.groupby(['key1','key2']):
print(k1,k2)
print(group)
a one data1 data2 key1 key2 0 1.16076 0.360555 a one 4 -0.45854 -0.093610 a one a two data1 data2 key1 key2 1 -0.992606 -0.120562 a two b one data1 data2 key1 key2 2 -0.616727 0.856179 b one b two data1 data2 key1 key2 3 -1.921879 -0.690846 b two
pieces=dict(list(df.groupby('key1')))
pieces['b']
|
data1 |
data2 |
key1 |
key2 |
| 2 |
-0.616727 |
0.856179 |
b |
one |
| 3 |
-1.921879 |
-0.690846 |
b |
two |
df.dtypes
data1 float64 data2 float64 key1 object key2 object dtype: object
grouped=df.groupby(df.dtypes,axis=1)
dict(list(grouped))
{dtype(‘float64’): data1 data2 0 1.160760 0.360555 1 -0.992606 -0.120562 2 -0.616727 0.856179 3 -1.921879 -0.690846 4 -0.458540 -0.093610, dtype(‘O’): key1 key2 0 a one 1 a two 2 b one 3 b two 4 a one}
选取一个或一组列
df.groupby('key1')['data1']
df.groupby('key1')[['data2']]
df['data1'].groupby(df['key1'])
df[['data2']].groupby(df['key1'])
df.groupby(['key1','key2'])[['data2']].mean()
|
|
data2 |
| key1 |
key2 |
|
| a |
one |
0.133473 |
| two |
-0.120562 |
| b |
one |
0.856179 |
| two |
-0.690846 |
s_grouped=df.groupby(['key1','key2'])['data2']
s_grouped
s_grouped.mean()
key1 key2 a one 0.133473 two -0.120562 b one 0.856179 two -0.690846 Name: data2, dtype: float64
通过字典或Series进行分组
除数组外,分组信息还可以其他形式存着
people=DataFrame(np.random.randn(5,5),
columns=['a','b','c','d','e'],
index=['Joe','Steve','Wes','Jim','Travis'])
people.ix[2:3,['b','c']]=np.nan
people
|
a |
b |
c |
d |
e |
| Joe |
0.246182 |
0.556642 |
0.530663 |
0.072457 |
0.769930 |
| Steve |
-0.735543 |
-0.046147 |
0.092191 |
0.659066 |
0.563112 |
| Wes |
-0.671631 |
NaN |
NaN |
0.351555 |
0.320022 |
| Jim |
0.730654 |
-0.554864 |
-0.013574 |
-0.238270 |
-1.276084 |
| Travis |
-0.246124 |
0.494404 |
0.782177 |
-1.856125 |
0.838289 |
mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
by_column=people.groupby(mapping,axis=1)
by_column.sum()
|
blue |
red |
| Joe |
0.603120 |
1.572753 |
| Steve |
0.751258 |
-0.218579 |
| Wes |
0.351555 |
-0.351610 |
| Jim |
-0.251844 |
-1.100294 |
| Travis |
-1.073948 |
1.086570 |
map_series=Series(mapping)
map_series
a red b red c blue d blue e red f orange dtype: object
people.groupby(map_series,axis=1).count()
|
blue |
red |
| Joe |
2 |
3 |
| Steve |
2 |
3 |
| Wes |
1 |
2 |
| Jim |
2 |
3 |
| Travis |
2 |
3 |
通过函数进行分组
people.groupby(len).sum()
|
a |
b |
c |
d |
e |
| 3 |
0.305204 |
0.001778 |
0.517089 |
0.185742 |
-0.186132 |
| 5 |
-0.735543 |
-0.046147 |
0.092191 |
0.659066 |
0.563112 |
| 6 |
-0.246124 |
0.494404 |
0.782177 |
-1.856125 |
0.838289 |
key_list=['one','one','one','two','two']
people.groupby([len,key_list]).min()
|
|
a |
b |
c |
d |
e |
| 3 |
one |
-0.671631 |
0.556642 |
0.530663 |
0.072457 |
0.320022 |
| two |
0.730654 |
-0.554864 |
-0.013574 |
-0.238270 |
-1.276084 |
| 5 |
one |
-0.735543 |
-0.046147 |
0.092191 |
0.659066 |
0.563112 |
| 6 |
two |
-0.246124 |
0.494404 |
0.782177 |
-1.856125 |
0.838289 |
根据索引级别分组
import pandas as pd
columns=pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],
[1,3,5,1,3]],names=['city','tenor'])
hier_df=DataFrame(np.random.randn(4,5),columns=columns)
hier_df
| city |
US |
JP |
| tenor |
1 |
3 |
5 |
1 |
3 |
| 0 |
-0.729876 |
-0.490356 |
1.200420 |
-1.594183 |
-0.571277 |
| 1 |
-1.336457 |
-2.033271 |
-0.356616 |
0.915616 |
-0.234895 |
| 2 |
-0.065620 |
-0.102485 |
0.605027 |
-0.518972 |
1.190415 |
| 3 |
0.985298 |
0.923531 |
1.784194 |
1.815795 |
-1.261107 |
hier_df.groupby(level='city',axis=1).count()
| city |
JP |
US |
| 0 |
2 |
3 |
| 1 |
2 |
3 |
| 2 |
2 |
3 |
| 3 |
2 |
3 |
数据聚合
df
|
data1 |
data2 |
key1 |
key2 |
| 0 |
1.160760 |
0.360555 |
a |
one |
| 1 |
-0.992606 |
-0.120562 |
a |
two |
| 2 |
-0.616727 |
0.856179 |
b |
one |
| 3 |
-1.921879 |
-0.690846 |
b |
two |
| 4 |
-0.458540 |
-0.093610 |
a |
one |
grouped=df.groupby('key1')
grouped['data1'].quantile(0.9)
key1 a 0.836900 b -0.747242 Name: data1, dtype: float64
def peak_to_peak(arr):
return arr.max()-arr.min()
grouped.agg(peak_to_peak)
|
data1 |
data2 |
| key1 |
|
|
| a |
2.153366 |
0.481117 |
| b |
1.305152 |
1.547025 |
grouped.describe()
|
|
data1 |
data2 |
| key1 |
|
|
|
| a |
count |
3.000000 |
3.000000 |
| mean |
-0.096796 |
0.048794 |
| std |
1.121334 |
0.270329 |
| min |
-0.992606 |
-0.120562 |
| 25% |
-0.725573 |
-0.107086 |
| 50% |
-0.458540 |
-0.093610 |
| 75% |
0.351110 |
0.133473 |
| max |
1.160760 |
0.360555 |
| b |
count |
2.000000 |
2.000000 |
| mean |
-1.269303 |
0.082666 |
| std |
0.922882 |
1.093912 |
| min |
-1.921879 |
-0.690846 |
| 25% |
-1.595591 |
-0.304090 |
| 50% |
-1.269303 |
0.082666 |
| 75% |
-0.943015 |
0.469422 |
| max |
-0.616727 |
0.856179 |
tips=pd.read_csv('ch08/tips.csv')
tips.head()
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
| 0 |
16.99 |
1.01 |
Female |
No |
Sun |
Dinner |
2 |
| 1 |
10.34 |
1.66 |
Male |
No |
Sun |
Dinner |
3 |
| 2 |
21.01 |
3.50 |
Male |
No |
Sun |
Dinner |
3 |
| 3 |
23.68 |
3.31 |
Male |
No |
Sun |
Dinner |
2 |
| 4 |
24.59 |
3.61 |
Female |
No |
Sun |
Dinner |
4 |
tips['tip_pct']=tips['tip']/tips['total_bill']
tips[:6]
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
tip_pct |
| 0 |
16.99 |
1.01 |
Female |
No |
Sun |
Dinner |
2 |
0.059447 |
| 1 |
10.34 |
1.66 |
Male |
No |
Sun |
Dinner |
3 |
0.160542 |
| 2 |
21.01 |
3.50 |
Male |
No |
Sun |
Dinner |
3 |
0.166587 |
| 3 |
23.68 |
3.31 |
Male |
No |
Sun |
Dinner |
2 |
0.139780 |
| 4 |
24.59 |
3.61 |
Female |
No |
Sun |
Dinner |
4 |
0.146808 |
| 5 |
25.29 |
4.71 |
Male |
No |
Sun |
Dinner |
4 |
0.186240 |
面向列的多函数应用
grouped=tips.groupby(['sex','smoker'])
grouped_pct=grouped['tip_pct']
grouped_pct.agg('mean')
sex smoker Female No 0.156921 Yes 0.182150 Male No 0.160669 Yes 0.152771 Name: tip_pct, dtype: float64
grouped_pct.agg(['mean','std',peak_to_peak])
|
|
mean |
std |
peak_to_peak |
| sex |
smoker |
|
|
|
| Female |
No |
0.156921 |
0.036421 |
0.195876 |
| Yes |
0.182150 |
0.071595 |
0.360233 |
| Male |
No |
0.160669 |
0.041849 |
0.220186 |
| Yes |
0.152771 |
0.090588 |
0.674707 |
grouped_pct.agg([('foo','mean'),('bar',np.std)])
|
|
foo |
bar |
| sex |
smoker |
|
|
| Female |
No |
0.156921 |
0.036421 |
| Yes |
0.182150 |
0.071595 |
| Male |
No |
0.160669 |
0.041849 |
| Yes |
0.152771 |
0.090588 |
functions=['count','mean','max']
result=grouped['tip_pct','total_bill'].agg(functions)
result
|
|
tip_pct |
total_bill |
|
|
count |
mean |
max |
count |
mean |
max |
| sex |
smoker |
|
|
|
|
|
|
| Female |
No |
54 |
0.156921 |
0.252672 |
54 |
18.105185 |
35.83 |
| Yes |
33 |
0.182150 |
0.416667 |
33 |
17.977879 |
44.30 |
| Male |
No |
97 |
0.160669 |
0.291990 |
97 |
19.791237 |
48.33 |
| Yes |
60 |
0.152771 |
0.710345 |
60 |
22.284500 |
50.81 |
result['tip_pct']
|
|
count |
mean |
max |
| sex |
smoker |
|
|
|
| Female |
No |
54 |
0.156921 |
0.252672 |
| Yes |
33 |
0.182150 |
0.416667 |
| Male |
No |
97 |
0.160669 |
0.291990 |
| Yes |
60 |
0.152771 |
0.710345 |
ftuples=[('Durchschnitt','mean'),('Abweichung',np.var)]
grouped['tip_pct','total_bill'].agg(ftuples)
|
|
tip_pct |
total_bill |
|
|
Durchschnitt |
Abweichung |
Durchschnitt |
Abweichung |
| sex |
smoker |
|
|
|
|
| Female |
No |
0.156921 |
0.001327 |
18.105185 |
53.092422 |
| Yes |
0.182150 |
0.005126 |
17.977879 |
84.451517 |
| Male |
No |
0.160669 |
0.001751 |
19.791237 |
76.152961 |
| Yes |
0.152771 |
0.008206 |
22.284500 |
98.244673 |
grouped.agg({'tip':np.max,'size':'sum'})
|
|
size |
tip |
| sex |
smoker |
|
|
| Female |
No |
140 |
5.2 |
| Yes |
74 |
6.5 |
| Male |
No |
263 |
9.0 |
| Yes |
150 |
10.0 |
grouped.agg({'tip_pct':['min','max','mean','std'],'size':'sum'})
|
|
size |
tip_pct |
|
|
sum |
min |
max |
mean |
std |
| sex |
smoker |
|
|
|
|
|
| Female |
No |
140 |
0.056797 |
0.252672 |
0.156921 |
0.036421 |
| Yes |
74 |
0.056433 |
0.416667 |
0.182150 |
0.071595 |
| Male |
No |
263 |
0.071804 |
0.291990 |
0.160669 |
0.041849 |
| Yes |
150 |
0.035638 |
0.710345 |
0.152771 |
0.090588 |
以”无索引”的形式返回聚合数据
tips.groupby(['sex','smoker'],as_index=False).mean()
|
sex |
smoker |
total_bill |
tip |
size |
tip_pct |
| 0 |
Female |
No |
18.105185 |
2.773519 |
2.592593 |
0.156921 |
| 1 |
Female |
Yes |
17.977879 |
2.931515 |
2.242424 |
0.182150 |
| 2 |
Male |
No |
19.791237 |
3.113402 |
2.711340 |
0.160669 |
| 3 |
Male |
Yes |
22.284500 |
3.051167 |
2.500000 |
0.152771 |
分组级运算和转换
聚合只不过是分组运算的其中一种而已。它能够接受将一维数组简化为标量值的函数。本节介绍transform和apply方法,他们能执行更多其他的分组运算
df
|
data1 |
data2 |
key1 |
key2 |
| 0 |
1.160760 |
0.360555 |
a |
one |
| 1 |
-0.992606 |
-0.120562 |
a |
two |
| 2 |
-0.616727 |
0.856179 |
b |
one |
| 3 |
-1.921879 |
-0.690846 |
b |
two |
| 4 |
-0.458540 |
-0.093610 |
a |
one |
k1_means=df.groupby('key1').mean().add_prefix('mean_')
k1_means
|
mean_data1 |
mean_data2 |
| key1 |
|
|
| a |
-0.096796 |
0.048794 |
| b |
-1.269303 |
0.082666 |
pd.merge(df,k1_means,left_on='key1',right_index=True)
|
data1 |
data2 |
key1 |
key2 |
mean_data1 |
mean_data2 |
| 0 |
1.160760 |
0.360555 |
a |
one |
-0.096796 |
0.048794 |
| 1 |
-0.992606 |
-0.120562 |
a |
two |
-0.096796 |
0.048794 |
| 4 |
-0.458540 |
-0.093610 |
a |
one |
-0.096796 |
0.048794 |
| 2 |
-0.616727 |
0.856179 |
b |
one |
-1.269303 |
0.082666 |
| 3 |
-1.921879 |
-0.690846 |
b |
two |
-1.269303 |
0.082666 |
key=['one','two','one','two','one']
people.groupby(key).mean()
|
a |
b |
c |
d |
e |
| one |
-0.223858 |
0.525523 |
0.656420 |
-0.477371 |
0.642747 |
| two |
-0.002445 |
-0.300505 |
0.039309 |
0.210398 |
-0.356486 |
people.groupby(key).transform(np.mean)
|
a |
b |
c |
d |
e |
| Joe |
-0.223858 |
0.525523 |
0.656420 |
-0.477371 |
0.642747 |
| Steve |
-0.002445 |
-0.300505 |
0.039309 |
0.210398 |
-0.356486 |
| Wes |
-0.223858 |
0.525523 |
0.656420 |
-0.477371 |
0.642747 |
| Jim |
-0.002445 |
-0.300505 |
0.039309 |
0.210398 |
-0.356486 |
| Travis |
-0.223858 |
0.525523 |
0.656420 |
-0.477371 |
0.642747 |
def demean(arr):
return arr-arr.mean()
demeaned=people.groupby(key).transform(demean)
demeaned
|
a |
b |
c |
d |
e |
| Joe |
0.470039 |
0.031119 |
-0.125757 |
0.549828 |
0.127183 |
| Steve |
-0.733099 |
0.254358 |
0.052883 |
0.448668 |
0.919598 |
| Wes |
-0.447773 |
NaN |
NaN |
0.828926 |
-0.322725 |
| Jim |
0.733099 |
-0.254358 |
-0.052883 |
-0.448668 |
-0.919598 |
| Travis |
-0.022266 |
-0.031119 |
0.125757 |
-1.378754 |
0.195542 |
demeaned.groupby(key).mean()
|
a |
b |
c |
d |
e |
| one |
1.850372e-17 |
-5.551115e-17 |
0.000000e+00 |
0.000000e+00 |
1.110223e-16 |
| two |
0.000000e+00 |
2.775558e-17 |
-3.469447e-18 |
-2.775558e-17 |
0.000000e+00 |
apply:一般性的“拆分-应用-合并”
跟aggregate一样,transform是一个有着严格条件的特殊函数:传入的函数只能产生两种结果,要么产生一个可以广播的标量值
如(np.mean),要么产生一个相同大小的结果数组。最一般化的GroupBy方法是apply,本节重点演示它。
apply会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。
def top(df,n=5,column='tip_pct'):
return df.sort_values(by=column)[-n:]
top(tips,n=6)
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
tip_pct |
| 109 |
14.31 |
4.00 |
Female |
Yes |
Sat |
Dinner |
2 |
0.279525 |
| 183 |
23.17 |
6.50 |
Male |
Yes |
Sun |
Dinner |
4 |
0.280535 |
| 232 |
11.61 |
3.39 |
Male |
No |
Sat |
Dinner |
2 |
0.291990 |
| 67 |
3.07 |
1.00 |
Female |
Yes |
Sat |
Dinner |
1 |
0.325733 |
| 178 |
9.60 |
4.00 |
Female |
Yes |
Sun |
Dinner |
2 |
0.416667 |
| 172 |
7.25 |
5.15 |
Male |
Yes |
Sun |
Dinner |
2 |
0.710345 |
tips.groupby('smoker').apply(top)
|
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
tip_pct |
| smoker |
|
|
|
|
|
|
|
|
|
| No |
88 |
24.71 |
5.85 |
Male |
No |
Thur |
Lunch |
2 |
0.236746 |
| 185 |
20.69 |
5.00 |
Male |
No |
Sun |
Dinner |
5 |
0.241663 |
| 51 |
10.29 |
2.60 |
Female |
No |
Sun |
Dinner |
2 |
0.252672 |
| 149 |
7.51 |
2.00 |
Male |
No |
Thur |
Lunch |
2 |
0.266312 |
| 232 |
11.61 |
3.39 |
Male |
No |
Sat |
Dinner |
2 |
0.291990 |
| Yes |
109 |
14.31 |
4.00 |
Female |
Yes |
Sat |
Dinner |
2 |
0.279525 |
| 183 |
23.17 |
6.50 |
Male |
Yes |
Sun |
Dinner |
4 |
0.280535 |
| 67 |
3.07 |
1.00 |
Female |
Yes |
Sat |
Dinner |
1 |
0.325733 |
| 178 |
9.60 |
4.00 |
Female |
Yes |
Sun |
Dinner |
2 |
0.416667 |
| 172 |
7.25 |
5.15 |
Male |
Yes |
Sun |
Dinner |
2 |
0.710345 |
tips.groupby(['smoker','day']).apply(top,n=1,column='total_bill')
|
|
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
tip_pct |
| smoker |
day |
|
|
|
|
|
|
|
|
|
| No |
Fri |
94 |
22.75 |
3.25 |
Female |
No |
Fri |
Dinner |
2 |
0.142857 |
| Sat |
212 |
48.33 |
9.00 |
Male |
No |
Sat |
Dinner |
4 |
0.186220 |
| Sun |
156 |
48.17 |
5.00 |
Male |
No |
Sun |
Dinner |
6 |
0.103799 |
| Thur |
142 |
41.19 |
5.00 |
Male |
No |
Thur |
Lunch |
5 |
0.121389 |
| Yes |
Fri |
95 |
40.17 |
4.73 |
Male |
Yes |
Fri |
Dinner |
4 |
0.117750 |
| Sat |
170 |
50.81 |
10.00 |
Male |
Yes |
Sat |
Dinner |
3 |
0.196812 |
| Sun |
182 |
45.35 |
3.50 |
Male |
Yes |
Sun |
Dinner |
3 |
0.077178 |
| Thur |
197 |
43.11 |
5.00 |
Female |
Yes |
Thur |
Lunch |
4 |
0.115982 |
除了基本用法之外,能否发挥apply的威力很大程度取决于你的创造力,传入的函数能做什么全由你说了算,只需要返回一个pandas对象或者标量即可。
result=tips.groupby('smoker')['tip_pct'].describe()
result
smoker No count 151.000000 mean 0.159328 std 0.039910 min 0.056797 25% 0.136906 50% 0.155625 75% 0.185014 max 0.291990 Yes count 93.000000 mean 0.163196 std 0.085119 min 0.035638 25% 0.106771 50% 0.153846 75% 0.195059 max 0.710345 Name: tip_pct, dtype: float64
result.unstack('smoker')
| smoker |
No |
Yes |
| count |
151.000000 |
93.000000 |
| mean |
0.159328 |
0.163196 |
| std |
0.039910 |
0.085119 |
| min |
0.056797 |
0.035638 |
| 25% |
0.136906 |
0.106771 |
| 50% |
0.155625 |
0.153846 |
| 75% |
0.185014 |
0.195059 |
| max |
0.291990 |
0.710345 |
f=lambda x:x.describe()
grouped.apply(f)
禁止分组键
从上面的例子可以看出,分组键会跟原始的索引共同构成结果中的层次化索引,将group_keys=Flase传入groupby即可禁止该效果
tips.groupby('smoker',group_keys=False).apply(top)
|
total_bill |
tip |
sex |
smoker |
day |
time |
size |
tip_pct |
| 88 |
24.71 |
5.85 |
Male |
No |
Thur |
Lunch |
2 |
0.236746 |
| 185 |
20.69 |
5.00 |
Male |
No |
Sun |
Dinner |
5 |
0.241663 |
| 51 |
10.29 |
2.60 |
Female |
No |
Sun |
Dinner |
2 |
0.252672 |
| 149 |
7.51 |
2.00 |
Male |
No |
Thur |
Lunch |
2 |
0.266312 |
| 232 |
11.61 |
3.39 |
Male |
No |
Sat |
Dinner |
2 |
0.291990 |
| 109 |
14.31 |
4.00 |
Female |
Yes |
Sat |
Dinner |
2 |
0.279525 |
| 183 |
23.17 |
6.50 |
Male |
Yes |
Sun |
Dinner |
4 |
0.280535 |
| 67 |
3.07 |
1.00 |
Female |
Yes |
Sat |
Dinner |
1 |
0.325733 |
| 178 |
9.60 |
4.00 |
Female |
Yes |
Sun |
Dinner |
2 |
0.416667 |
| 172 |
7.25 |
5.15 |
Male |
Yes |
Sun |
Dinner |
2 |
0.710345 |
分位数和桶分析
pandas有一些能根据指定面元或者样本分位数将数据拆分成多块的工具(比如cut和qcut)。将这些函数跟groupby结合其阿里,能
轻松实现对数据集的桶(bucket)或者分位数(quantile)分析了。
frame=DataFrame({'data1':np.random.randn(100),
'data2':np.random.randn(100)})
frame.head()
|
data1 |
data2 |
| 0 |
1.421652 |
-0.133642 |
| 1 |
1.663593 |
1.570306 |
| 2 |
0.072588 |
1.445291 |
| 3 |
-1.117481 |
0.485219 |
| 4 |
0.673224 |
-0.565916 |
factor=pd.cut(frame.data1,4)
factor[:10]
0 (0.592, 1.913] 1 (0.592, 1.913] 2 (-0.73, 0.592] 3 (-2.0564, -0.73] 4 (0.592, 1.913] 5 (0.592, 1.913] 6 (0.592, 1.913] 7 (-0.73, 0.592] 8 (-0.73, 0.592] 9 (-2.0564, -0.73] Name: data1, dtype: category Categories (4, object): [(-2.0564, -0.73]
def get_stats(group):
return{'min':group.min(),'max':group.max(),'count':group.count()
,'mean':group.mean()}
grouped=frame.data2.groupby(factor)
grouped.apply(get_stats).unstack()
|
count |
max |
mean |
min |
| data1 |
|
|
|
|
| (-2.0564, -0.73] |
22.0 |
1.656349 |
-0.048650 |
-2.129592 |
| (-0.73, 0.592] |
50.0 |
2.118117 |
0.006637 |
-2.178494 |
| (0.592, 1.913] |
25.0 |
2.893815 |
0.525179 |
-2.531124 |
| (1.913, 3.234] |
3.0 |
1.423038 |
-0.643547 |
-2.888465 |
grouping=pd.qcut(frame.data1,10,labels=False)
grouped=frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()
|
count |
max |
mean |
min |
| data1 |
|
|
|
|
| 0 |
10.0 |
1.656349 |
0.200332 |
-2.129592 |
| 1 |
10.0 |
0.892938 |
-0.161470 |
-1.448465 |
| 2 |
10.0 |
0.936595 |
-0.502936 |
-1.486019 |
| 3 |
10.0 |
1.225042 |
-0.136442 |
-1.471110 |
| 4 |
10.0 |
2.118117 |
0.223633 |
-2.178494 |
| 5 |
10.0 |
1.445291 |
-0.010989 |
-1.145924 |
| 6 |
10.0 |
1.166204 |
0.230245 |
-0.578312 |
| 7 |
10.0 |
1.582353 |
0.491112 |
-0.565916 |
| 8 |
10.0 |
2.893815 |
0.183646 |
-2.531124 |
| 9 |
10.0 |
2.215117 |
0.528908 |
-2.888465 |
示例:用特定于分组的值填充缺失值
s=Series(np.random.randn(6))
s[::2]=np.nan
s
0 NaN 1 0.480519 2 NaN 3 0.994221 4 NaN 5 0.324907 dtype: float64
s.fillna(s.mean())
0 0.599882 1 0.480519 2 0.599882 3 0.994221 4 0.599882 5 0.324907 dtype: float64
states=['Ohio','New York','Vermont','Florida','Oregon','Nevada','California','Idaho']
group_key=['East']*4+['West']*4
data=Series(np.random.randn(8),index=states)
data[['Vermont','Nevada','Idaho']]=np.nan
data
Ohio -0.714495 New York -0.484234 Vermont NaN Florida -0.485962 Oregon 0.399898 Nevada NaN California -0.956605 Idaho NaN dtype: float64
data.groupby(group_key).mean()
East -0.561564 West -0.278353 dtype: float64
fill_mean=lambda g:g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
Ohio -0.714495 New York -0.484234 Vermont -0.561564 Florida -0.485962 Oregon 0.399898 Nevada -0.278353 California -0.956605 Idaho -0.278353 dtype: float64
fill_values={'East':0.5,'West':-1}
fill_func=lambda g:g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
Ohio -0.714495
New York -0.484234
Vermont 0.500000
Florida -0.485962
Oregon 0.399898
Nevada -1.000000
California -0.956605
Idaho -1.000000
dtype: float64
示例:随机采样和排列
suits=['H','S','C','D']
card_val=( list(range(1,11))+ [10]*3)*4
base_names=['A']+list(range(2,11))+['J','Q','K']
cards=[]
for suit in ['H','S','C','D']:
cards.extend(str(num)+suit for num in base_names)
deck=Series(card_val,index=cards)
deck[:13]
AH 1 2H 2 3H 3 4H 4 5H 5 6H 6 7H 7 8H 8 9H 9 10H 10 JH 10 QH 10 KH 10 dtype: int64
def draw(deck,n=5):
return deck.take(np.random.permutation(len(deck))[:n])
draw(deck)
10D 10 5D 5 10H 10 3S 3 8C 8 dtype: int64
get_suit=lambda card:card[-1]
deck.groupby(get_suit).apply(draw,n=2)
C 7C 7 3C 3 D 10D 10 KD 10 H 5H 5 10H 10 S 10S 10 4S 4 dtype: int64
deck.groupby(get_suit,group_keys=False).apply(draw,n=2)
7C 7
10C 10
KD 10
QD 10
QH 10
JH 10
3S 3
KS 10
dtype: int64
示例:分组加权平均数和相关系数
根据groupby的“拆分-应用-合并”范式,DataFrame的列与列之间或两个Series之间的运算(比如分组加权平均)成为一种标准作业。
以下面这个数据集为例,它含有分组键、值以及一些权重值
df=DataFrame({'category':['a','a','a','a','b','b','b','b'],'data':np.random.randn(8),
'weights':np.random.rand(8)})
df
|
category |
data |
weights |
| 0 |
a |
-1.279366 |
0.262668 |
| 1 |
a |
-0.993197 |
0.124788 |
| 2 |
a |
-0.092631 |
0.644840 |
| 3 |
a |
0.216670 |
0.413393 |
| 4 |
b |
-0.697899 |
0.621993 |
| 5 |
b |
-0.568083 |
0.190767 |
| 6 |
b |
-0.963962 |
0.587816 |
| 7 |
b |
0.637361 |
0.522886 |
grouped=df.groupby('category')
get_wavg=lambda g:np.average(g['data'],weights=g['weights'])
grouped.apply(get_wavg)
category a -0.297540 b -0.403348 dtype: float64
close_px=pd.read_csv('ch09/stock_px.csv',parse_dates=True,index_col=0)
close_px[-4:]
|
AAPL |
MSFT |
XOM |
SPX |
| 2011-10-11 |
400.29 |
27.00 |
76.27 |
1195.54 |
| 2011-10-12 |
402.19 |
26.96 |
77.16 |
1207.25 |
| 2011-10-13 |
408.43 |
27.18 |
76.37 |
1203.66 |
| 2011-10-14 |
422.00 |
27.27 |
78.11 |
1224.58 |
rets=close_px.pct_change().dropna()
spx_corr=lambda x:x.corrwith(x['SPX'])
by_year=rets.groupby(lambda x:x.year)
by_year.apply(spx_corr)
|
AAPL |
MSFT |
XOM |
SPX |
| 2003 |
0.541124 |
0.745174 |
0.661265 |
1.0 |
| 2004 |
0.374283 |
0.588531 |
0.557742 |
1.0 |
| 2005 |
0.467540 |
0.562374 |
0.631010 |
1.0 |
| 2006 |
0.428267 |
0.406126 |
0.518514 |
1.0 |
| 2007 |
0.508118 |
0.658770 |
0.786264 |
1.0 |
| 2008 |
0.681434 |
0.804626 |
0.828303 |
1.0 |
| 2009 |
0.707103 |
0.654902 |
0.797921 |
1.0 |
| 2010 |
0.710105 |
0.730118 |
0.839057 |
1.0 |
| 2011 |
0.691931 |
0.800996 |
0.859975 |
1.0 |
by_year.apply(lambda g:g['AAPL'].corr(g['MSFT']))
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64
示例:面向分组的线性回归
顺着上一个例子继续,你可以用groupby执行更为复杂的分组统计分析,只要函数返回的是一个pandas对象或标量值即可。
例如,我们可以定义下面这个regress函数(利用statsmodels库)对各数据块执行普通最小二乘法(Ordinary Least Squares,OLS)回归
import statsmodels.api as sm
def regress(data,yvar,xvars):
Y=data[yvar]
X=data[xvars]
X['intercetp']=1.
result=sm.OLS(Y,X).fit()
return result.params
by_year.apply(regress,'AAPL',['SPX'])
|
SPX |
intercetp |
| 2003 |
1.195406 |
0.000710 |
| 2004 |
1.363463 |
0.004201 |
| 2005 |
1.766415 |
0.003246 |
| 2006 |
1.645496 |
0.000080 |
| 2007 |
1.198761 |
0.003438 |
| 2008 |
0.968016 |
-0.001110 |
| 2009 |
0.879103 |
0.002954 |
| 2010 |
1.052608 |
0.001261 |
| 2011 |
0.806605 |
0.001514 |
#透视表和交叉表 透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列的分组键将数据分配到各个矩形区域中。 在Python和pandas中,可以通过本章所介绍的groupby功能以及重塑运算制作透视表。DataFrame有一个pivot_table方法,此外,还有一个顶级的pandas.pivot_table函数。除能为groupby提供便利之外,pivot_table还可以添加分项小计(也叫做margins) 回到小费数据集,假设我想要根据sex和smoker计算分组平均数(pivot_table的默认集合类型),并将sex和smoker放到行上。。
tips.pivot_table(index=['sex','smoker'])
|
|
size |
tip |
tip_pct |
total_bill |
| sex |
smoker |
|
|
|
|
| Female |
No |
2.592593 |
2.773519 |
0.156921 |
18.105185 |
| Yes |
2.242424 |
2.931515 |
0.182150 |
17.977879 |
| Male |
No |
2.711340 |
3.113402 |
0.160669 |
19.791237 |
| Yes |
2.500000 |
3.051167 |
0.152771 |
22.284500 |
tips.pivot_table(['tip_pct','size'],index=['sex','day'],columns=['smoker'])
|
|
tip_pct |
size |
|
smoker |
No |
Yes |
No |
Yes |
| sex |
day |
|
|
|
|
| Female |
Fri |
0.165296 |
0.209129 |
2.500000 |
2.000000 |
| Sat |
0.147993 |
0.163817 |
2.307692 |
2.200000 |
| Sun |
0.165710 |
0.237075 |
3.071429 |
2.500000 |
| Thur |
0.155971 |
0.163073 |
2.480000 |
2.428571 |
| Male |
Fri |
0.138005 |
0.144730 |
2.000000 |
2.125000 |
| Sat |
0.162132 |
0.139067 |
2.656250 |
2.629630 |
| Sun |
0.158291 |
0.173964 |
2.883721 |
2.600000 |
| Thur |
0.165706 |
0.164417 |
2.500000 |
2.300000 |
tips.pivot_table(['tip_pct','size'],index=['sex','day'],columns=['smoker'],margins=True)
|
|
tip_pct |
size |
|
smoker |
No |
Yes |
All |
No |
Yes |
All |
| sex |
day |
|
|
|
|
|
|
| Female |
Fri |
0.165296 |
0.209129 |
0.199388 |
2.500000 |
2.000000 |
2.111111 |
| Sat |
0.147993 |
0.163817 |
0.156470 |
2.307692 |
2.200000 |
2.250000 |
| Sun |
0.165710 |
0.237075 |
0.181569 |
3.071429 |
2.500000 |
2.944444 |
| Thur |
0.155971 |
0.163073 |
0.157525 |
2.480000 |
2.428571 |
2.468750 |
| Male |
Fri |
0.138005 |
0.144730 |
0.143385 |
2.000000 |
2.125000 |
2.100000 |
| Sat |
0.162132 |
0.139067 |
0.151577 |
2.656250 |
2.629630 |
2.644068 |
| Sun |
0.158291 |
0.173964 |
0.162344 |
2.883721 |
2.600000 |
2.810345 |
| Thur |
0.165706 |
0.164417 |
0.165276 |
2.500000 |
2.300000 |
2.433333 |
| All |
|
0.159328 |
0.163196 |
0.160803 |
2.668874 |
2.408602 |
2.569672 |
tips.pivot_table('tip_pct',index=['sex','smoker'],columns=['day'],aggfunc=len,margins=True)
|
day |
Fri |
Sat |
Sun |
Thur |
All |
| sex |
smoker |
|
|
|
|
|
| Female |
No |
2.0 |
13.0 |
14.0 |
25.0 |
54.0 |
| Yes |
7.0 |
15.0 |
4.0 |
7.0 |
33.0 |
| Male |
No |
2.0 |
32.0 |
43.0 |
20.0 |
97.0 |
| Yes |
8.0 |
27.0 |
15.0 |
10.0 |
60.0 |
| All |
|
19.0 |
87.0 |
76.0 |
62.0 |
244.0 |
tips.pivot_table('size',index=['time','sex','smoker'],columns=['day'],aggfunc='sum',fill_value=0)
|
|
day |
Fri |
Sat |
Sun |
Thur |
| time |
sex |
smoker |
|
|
|
|
| Dinner |
Female |
No |
2 |
30 |
43 |
2 |
| Yes |
8 |
33 |
10 |
0 |
| Male |
No |
4 |
85 |
124 |
0 |
| Yes |
12 |
71 |
39 |
0 |
| Lunch |
Female |
No |
3 |
0 |
0 |
60 |
| Yes |
6 |
0 |
0 |
17 |
| Male |
No |
0 |
0 |
0 |
50 |
| Yes |
5 |
0 |
0 |
23 |
交叉表: crosstab
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表
pd.crosstab([tips.time,tips.day],tips.smoker,margins=True)
|
smoker |
No |
Yes |
All |
| time |
day |
|
|
|
| Dinner |
Fri |
3 |
9 |
12 |
| Sat |
45 |
42 |
87 |
| Sun |
57 |
19 |
76 |
| Thur |
1 |
0 |
1 |
| Lunch |
Fri |
1 |
6 |
7 |
| Thur |
44 |
17 |
61 |
| All |
|
151 |
93 |
244 |
示例:2012联邦选举委员会数据库
fec=pd.read_csv('ch09/P00000001-ALL.csv')
fec.head()
C:\Users\ZJL\AppData\Local\Programs\Python\Python35\lib\site-packages\IPython\core\interactiveshell.py:2717: DtypeWarning: Columns (6) have mixed types. Specify dtype option on import or set low_memory=False. interactivity=interactivity, compiler=compiler, result=result)
|
cmte_id |
cand_id |
cand_nm |
contbr_nm |
contbr_city |
contbr_st |
contbr_zip |
contbr_employer |
contbr_occupation |
contb_receipt_amt |
contb_receipt_dt |
receipt_desc |
memo_cd |
memo_text |
form_tp |
file_num |
| 0 |
C00410118 |
P20002978 |
Bachmann, Michelle |
HARVEY, WILLIAM |
MOBILE |
AL |
3.6601e+08 |
RETIRED |
RETIRED |
250.0 |
20-JUN-11 |
NaN |
NaN |
NaN |
SA17A |
736166 |
| 1 |
C00410118 |
P20002978 |
Bachmann, Michelle |
HARVEY, WILLIAM |
MOBILE |
AL |
3.6601e+08 |
RETIRED |
RETIRED |
50.0 |
23-JUN-11 |
NaN |
NaN |
NaN |
SA17A |
736166 |
| 2 |
C00410118 |
P20002978 |
Bachmann, Michelle |
SMITH, LANIER |
LANETT |
AL |
3.68633e+08 |
INFORMATION REQUESTED |
INFORMATION REQUESTED |
250.0 |
05-JUL-11 |
NaN |
NaN |
NaN |
SA17A |
749073 |
| 3 |
C00410118 |
P20002978 |
Bachmann, Michelle |
BLEVINS, DARONDA |
PIGGOTT |
AR |
7.24548e+08 |
NONE |
RETIRED |
250.0 |
01-AUG-11 |
NaN |
NaN |
NaN |
SA17A |
749073 |
| 4 |
C00410118 |
P20002978 |
Bachmann, Michelle |
WARDENBURG, HAROLD |
HOT SPRINGS NATION |
AR |
7.19016e+08 |
NONE |
RETIRED |
300.0 |
20-JUN-11 |
NaN |
NaN |
NaN |
SA17A |
736166 |
fec.ix[123456]
cmte_id C00431445 cand_id P80003338 cand_nm Obama, Barack contbr_nm ELLMAN, IRA contbr_city TEMPE contbr_st AZ contbr_zip 852816719 contbr_employer ARIZONA STATE UNIVERSITY contbr_occupation PROFESSOR contb_receipt_amt 50 contb_receipt_dt 01-DEC-11 receipt_desc NaN memo_cd NaN memo_text NaN form_tp SA17A file_num 772372 Name: 123456, dtype: object
unique_cands=fec.cand_nm.unique()
unique_cands
array([‘Bachmann, Michelle’, ‘Romney, Mitt’, ‘Obama, Barack’, “Roemer, Charles E. ‘Buddy’ III”, ‘Pawlenty, Timothy’, ‘Johnson, Gary Earl’, ‘Paul, Ron’, ‘Santorum, Rick’, ‘Cain, Herman’, ‘Gingrich, Newt’, ‘McCotter, Thaddeus G’, ‘Huntsman, Jon’, ‘Perry, Rick’], dtype=object)
unique_cands[2]
‘Obama, Barack’
parties={'Bachmann, Michelle':'Republican',
'Cain, Herman':'Republican',
'Gingrich, Newt':'Republican',
'Johnson, Gary Earl':'Republican',
'McCotter, Thaddeus G':'Republican',
'Obama, Barack':'Democrat',
'Paul, Ron':'Republican',
'Pawlenty, Timothy':'Republican',
'Perry, Rick':'Republican',
"Roemer, Charles E. 'Buddy' III":'Republican',
'Romney, Mitt':'Republican',
'Cain, Herman':'Republican',
'Santorum, Rick':'Republican'
}
fec.cand_nm[123456:123461]
123456 Obama, Barack 123457 Obama, Barack 123458 Obama, Barack 123459 Obama, Barack 123460 Obama, Barack Name: cand_nm, dtype: object
fec.cand_nm[123456:123461].map(parties)
123456 Democrat 123457 Democrat 123458 Democrat 123459 Democrat 123460 Democrat Name: cand_nm, dtype: object
fec['party']=fec.cand_nm.map(parties)
fec['party'].value_counts()
Democrat 593746 Republican 403829 Name: party, dtype: int64
(fec.contb_receipt_amt>0).value_counts()
True 991475 False 10256 Name: contb_receipt_amt, dtype: int64
fec=fec[fec.contb_receipt_amt>0]
fec_mrbo=fec[fec.cand_nm.isin(['Obama, Barack','Romney, Mitt'])]
fec_mrbo.head()
|
cmte_id |
cand_id |
cand_nm |
contbr_nm |
contbr_city |
contbr_st |
contbr_zip |
contbr_employer |
contbr_occupation |
contb_receipt_amt |
contb_receipt_dt |
receipt_desc |
memo_cd |
memo_text |
form_tp |
file_num |
party |
| 411 |
C00431171 |
P80003353 |
Romney, Mitt |
ELDERBAUM, WILLIAM |
DPO |
AA |
3.4023e+08 |
US GOVERNMENT |
FOREIGN SERVICE OFFICER |
25.0 |
01-FEB-12 |
NaN |
NaN |
NaN |
SA17A |
780124 |
Republican |
| 412 |
C00431171 |
P80003353 |
Romney, Mitt |
ELDERBAUM, WILLIAM |
DPO |
AA |
3.4023e+08 |
US GOVERNMENT |
FOREIGN SERVICE OFFICER |
110.0 |
01-FEB-12 |
NaN |
NaN |
NaN |
SA17A |
780124 |
Republican |
| 413 |
C00431171 |
P80003353 |
Romney, Mitt |
CARLSEN, RICHARD |
APO |
AE |
9.128e+07 |
DEFENSE INTELLIGENCE AGENCY |
INTELLIGENCE ANALYST |
250.0 |
13-APR-12 |
NaN |
NaN |
NaN |
SA17A |
785689 |
Republican |
| 414 |
C00431171 |
P80003353 |
Romney, Mitt |
DELUCA, PIERRE |
APO |
AE |
9.128e+07 |
CISCO |
ENGINEER |
30.0 |
21-AUG-11 |
NaN |
NaN |
NaN |
SA17A |
760261 |
Republican |
| 415 |
C00431171 |
P80003353 |
Romney, Mitt |
SARGENT, MICHAEL |
APO |
AE |
9.01201e+07 |
RAYTHEON TECHNICAL SERVICES CORP |
COMPUTER SYSTEMS ENGINEER |
100.0 |
07-MAR-12 |
NaN |
NaN |
NaN |
SA17A |
780128 |
Republican |
根据职业和雇主统计赞助信息
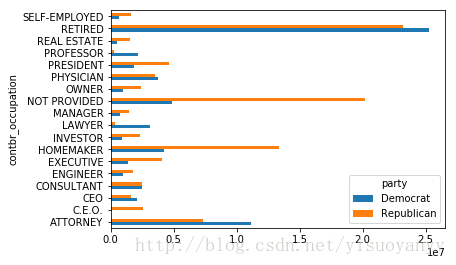
fec.contbr_occupation.value_counts()[:10]
RETIRED 233990 INFORMATION REQUESTED 35107 ATTORNEY 34286 HOMEMAKER 29931 PHYSICIAN 23432 INFORMATION REQUESTED PER BEST EFFORTS 21138 ENGINEER 14334 TEACHER 13990 CONSULTANT 13273 PROFESSOR 12555 Name: contbr_occupation, dtype: int64
occ_mapping={'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'INFORMATION REQUESTED (BEST EFFORTS)':'NOT PROVIDED',
'C.E.O':'CEO'}
f=lambda x:occ_mapping.get(x,x)
fec.contbr_occupation=fec.contbr_occupation.map(f)
emp_mapping={'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF':'SELF-EMPLOYED',}
f=lambda x:emp_mapping.get(x,x)
fec.contbr_employer=fec.contbr_employer.map(f)
by_occupation=fec.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='party',aggfunc='sum')
over_2mm=by_occupation[by_occupation.sum(1)>2000000]
over_2mm
| party |
Democrat |
Republican |
| contbr_occupation |
|
|
| ATTORNEY |
11141982.97 |
7.333637e+06 |
| C.E.O. |
1690.00 |
2.543933e+06 |
| CEO |
2074284.79 |
1.598978e+06 |
| CONSULTANT |
2459912.71 |
2.502470e+06 |
| ENGINEER |
951525.55 |
1.812534e+06 |
| EXECUTIVE |
1355161.05 |
4.057645e+06 |
| HOMEMAKER |
4248875.80 |
1.338025e+07 |
| INVESTOR |
884133.00 |
2.356671e+06 |
| LAWYER |
3160478.87 |
3.394023e+05 |
| MANAGER |
762883.22 |
1.430643e+06 |
| NOT PROVIDED |
4866973.96 |
2.018997e+07 |
| OWNER |
1001567.36 |
2.376829e+06 |
| PHYSICIAN |
3735124.94 |
3.555067e+06 |
| PRESIDENT |
1878509.95 |
4.622173e+06 |
| PROFESSOR |
2165071.08 |
2.839557e+05 |
| REAL ESTATE |
528902.09 |
1.567552e+06 |
| RETIRED |
25305116.38 |
2.320195e+07 |
| SELF-EMPLOYED |
672393.40 |
1.621010e+06 |
import matplotlib.pyplot as plt
over_2mm.plot(kind='barh')
plt.show()
def get_top_amounts(group,key,n=5):
totals=group.groupby(key)['contb_receipt_amt'].sum()
return totals.sort_values(ascending=False)[:n]
grouped=fec_mrbo.groupby('cand_nm')
grouped.apply(get_top_amounts,'contbr_occupation',n=7)
cand_nm contbr_occupation Obama, Barack RETIRED 25305116.38 ATTORNEY 11141982.97 INFORMATION REQUESTED 4866973.96 HOMEMAKER 4248875.80 PHYSICIAN 3735124.94 LAWYER 3160478.87 CONSULTANT 2459912.71 Romney, Mitt RETIRED 11508473.59 INFORMATION REQUESTED PER BEST EFFORTS 11396894.84 HOMEMAKER 8147446.22 ATTORNEY 5364718.82 PRESIDENT 2491244.89 EXECUTIVE 2300947.03 C.E.O. 1968386.11 Name: contb_receipt_amt, dtype: float64
grouped.apply(get_top_amounts,'contbr_employer',n=10)
cand_nm contbr_employer Obama, Barack RETIRED 22694358.85 SELF-EMPLOYED 17080985.96 NOT EMPLOYED 8586308.70 INFORMATION REQUESTED 5053480.37 HOMEMAKER 2605408.54 SELF 1076531.20 SELF EMPLOYED 469290.00 STUDENT 318831.45 VOLUNTEER 257104.00 MICROSOFT 215585.36 Romney, Mitt INFORMATION REQUESTED PER BEST EFFORTS 12059527.24 RETIRED 11506225.71 HOMEMAKER 8147196.22 SELF-EMPLOYED 7409860.98 STUDENT 496490.94 CREDIT SUISSE 281150.00 MORGAN STANLEY 267266.00 GOLDMAN SACH & CO. 238250.00 BARCLAYS CAPITAL 162750.00 H.I.G. CAPITAL 139500.00 Name: contb_receipt_amt, dtype: float64
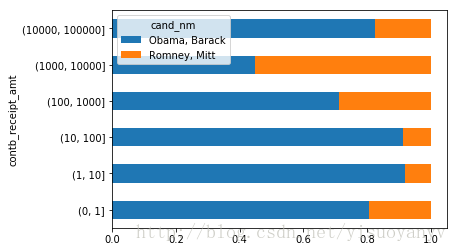
对出资额分组
利用cut函数根据出资额的大小将数据离散化到多个面元中
bins=np.array([0,1,10,100,1000,10000,100000,1000000,10000000])
labels=pd.cut(fec_mrbo.contb_receipt_amt,bins)
labels.head()
411 (10, 100] 412 (100, 1000] 413 (100, 1000] 414 (10, 100] 415 (10, 100] Name: contb_receipt_amt, dtype: category Categories (8, object): [(0, 1]
grouped=fec_mrbo.groupby(['cand_nm',labels])
grouped.size().unstack(0)
| cand_nm |
Obama, Barack |
Romney, Mitt |
| contb_receipt_amt |
|
|
| (0, 1] |
493.0 |
77.0 |
| (1, 10] |
40070.0 |
3681.0 |
| (10, 100] |
372280.0 |
31853.0 |
| (100, 1000] |
153991.0 |
43357.0 |
| (1000, 10000] |
22284.0 |
26186.0 |
| (10000, 100000] |
2.0 |
1.0 |
| (100000, 1000000] |
3.0 |
NaN |
| (1000000, 10000000] |
4.0 |
NaN |
bucket_sums=grouped.contb_receipt_amt.sum().unstack(0)
bucket_sums
| cand_nm |
Obama, Barack |
Romney, Mitt |
| contb_receipt_amt |
|
|
| (0, 1] |
318.24 |
77.00 |
| (1, 10] |
337267.62 |
29819.66 |
| (10, 100] |
20288981.41 |
1987783.76 |
| (100, 1000] |
54798531.46 |
22363381.69 |
| (1000, 10000] |
51753705.67 |
63942145.42 |
| (10000, 100000] |
59100.00 |
12700.00 |
| (100000, 1000000] |
1490683.08 |
NaN |
| (1000000, 10000000] |
7148839.76 |
NaN |
normed_sums=bucket_sums.div(bucket_sums.sum(axis=1),axis=0)
normed_sums
| cand_nm |
Obama, Barack |
Romney, Mitt |
| contb_receipt_amt |
|
|
| (0, 1] |
0.805182 |
0.194818 |
| (1, 10] |
0.918767 |
0.081233 |
| (10, 100] |
0.910769 |
0.089231 |
| (100, 1000] |
0.710176 |
0.289824 |
| (1000, 10000] |
0.447326 |
0.552674 |
| (10000, 100000] |
0.823120 |
0.176880 |
| (100000, 1000000] |
1.000000 |
NaN |
| (1000000, 10000000] |
1.000000 |
NaN |
normed_sums[:-2].plot(kind='barh',stacked=True)
plt.show()
根据州统计赞助信息
grouped=fec_mrbo.groupby(['cand_nm','contbr_st'])
totals=grouped.contb_receipt_amt.sum().unstack(0).fillna(0)
totals=totals[totals.sum(1)>100000]
totals[:10]
| cand_nm |
Obama, Barack |
Romney, Mitt |
| contbr_st |
|
|
| AK |
281840.15 |
86204.24 |
| AL |
543123.48 |
527303.51 |
| AR |
359247.28 |
105556.00 |
| AZ |
1506476.98 |
1888436.23 |
| CA |
23824984.24 |
11237636.60 |
| CO |
2132429.49 |
1506714.12 |
| CT |
2068291.26 |
3499475.45 |
| DC |
4373538.80 |
1025137.50 |
| DE |
336669.14 |
82712.00 |
| FL |
7318178.58 |
8338458.81 |
percent=totals.div(totals.sum(1),axis=0)
percent[:10]
| cand_nm |
Obama, Barack |
Romney, Mitt |
| contbr_st |
|
|
| AK |
0.765778 |
0.234222 |
| AL |
0.507390 |
0.492610 |
| AR |
0.772902 |
0.227098 |
| AZ |
0.443745 |
0.556255 |
| CA |
0.679498 |
0.320502 |
| CO |
0.585970 |
0.414030 |
| CT |
0.371476 |
0.628524 |
| DC |
0.810113 |
0.189887 |
| DE |
0.802776 |
0.197224 |
| FL |
0.467417 |
0.532583 |
from mpl_toolkits.basemap import Basemap,cm
from matplotlib import rcParams
from matplotlib.collections import LineCollection
from shapelib import ShapeFile
import dbflib
obama=percent['Obama, Barack']
fig=plt.figure(figsize=(12,12))
ax=fig.add_axes[0.1,0.1,0.8,0.8]
lllat=21;urlat=53;lllon=-118,urlon=-62
m=Basemap(ax=ax,projection='stere',lon_0=(urlon+lllon)/2,lat_0=(urlat+lllat)/2,
llcrnrlat=lllat,urcrnrlat=urlat,llcrnrlon=lllon,
urcrnrlon=urlon,resolution='l')
m.drawcoastlines()
m.drawcounties()
shp=ShapeFile('../states/statespo2o')
dbf=dblib.open('../states/statespo2o')
for nploy in range(shp.info()[0]):
shpsegs=[]
shp_object=shp.read_object(npoly)
verts=shp_object.vertices()
rings=len(verts)
for ring in range(rings):
lons,lats=zip(*verts[ring])
x,y=m(lons,lats)
shpsegs.append(zip(x,y))
if ring==0:
shapedict=dbf.read_record(npoly)
name=shapedict['STATE']
lines=LineCollection(shpsegs,antialiaseds=(1,))
try:
per=obama[state_to_code[name.upper()]]
except KeyError:
continue
lines.set_facecolors('k')
lines.set_alpha(0.75*per)
lines.set_edgecolors('k')
lines.set_linewidth(0.3)
plt.show()