learn from https://www.kaggle.com/learn/pandas
1. Creating, Reading and Writing
1.1 DataFrame 数据框架
- 创建
DataFrame,它是一张表,内部是字典,key :[value_1,...,value_n]
#%%
# -*- coding:utf-8 -*-
# @Python Version: 3.7
# @Time: 2020/5/16 21:10
# @Author: Michael Ming
# @Website: https://michael.blog.csdn.net/
# @File: pandasExercise.ipynb
# @Reference: https://www.kaggle.com/learn/pandas
import pandas as pd
#%%
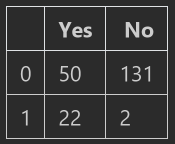
pd.DataFrame({'Yes':[50,22],"No":[131,2]})
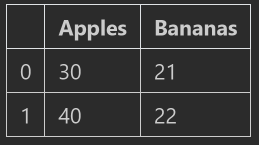
fruits = pd.DataFrame([[30, 21],[40, 22]], columns=['Apples', 'Bananas'])
- 字典内的
value也可以是:字符串
pd.DataFrame({"Michael":['handsome','good'],"Ming":['love basketball','coding']})

- 给数据加索引
index,index=['index1','index2',...]
pd.DataFrame({"Michael":['handsome','good'],"Ming":['love basketball','coding']},
index=['people1 say','people2 say'])

1.2 Series 序列
Series是一系列的数据,可以看成是 list
pd.Series([5,2,0,1,3,1,4])
0 5
1 2
2 0
3 1
4 3
5 1
6 4
dtype: int64
- 也可以把数据赋值给Series,只是Series没有列名称,只有总的名称
- DataFrame本质上是多个Series
粘在一起
pd.Series([30,40,50],index=['2018销量','2019销量','2020销量'],
name='博客访问量')
2018销量 30
2019销量 40
2020销量 50
Name: 博客访问量, dtype: int64
1.3 Reading 读取数据
- 读取csv(
"Comma-Separated Values")文件,pd.read_csv('file'),存入一个DataFrame
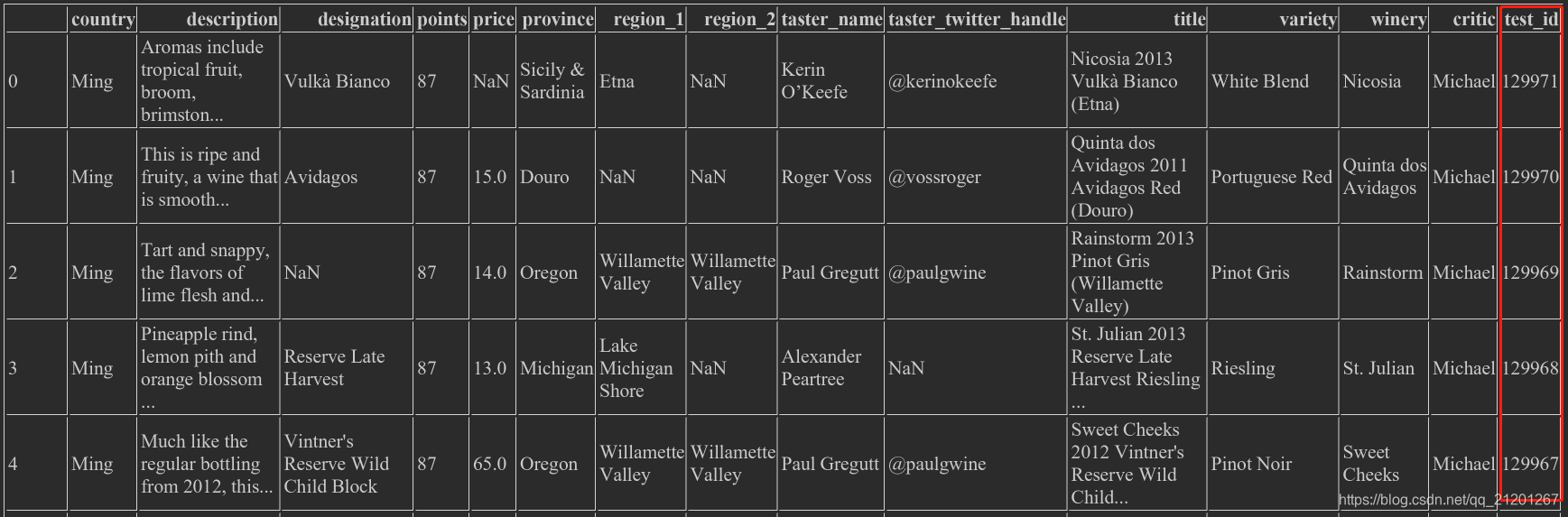
wine_rev = pd.read_csv("winemag-data-130k-v2.csv")
wine_rev.shape # 大小
(129971, 14)
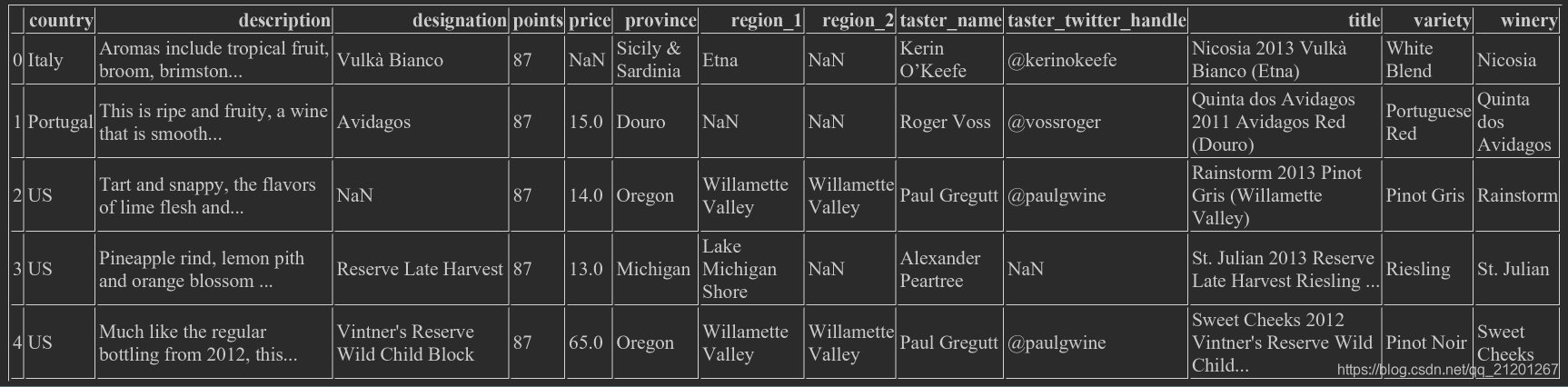
wine_rev.head() # 查看头部5行
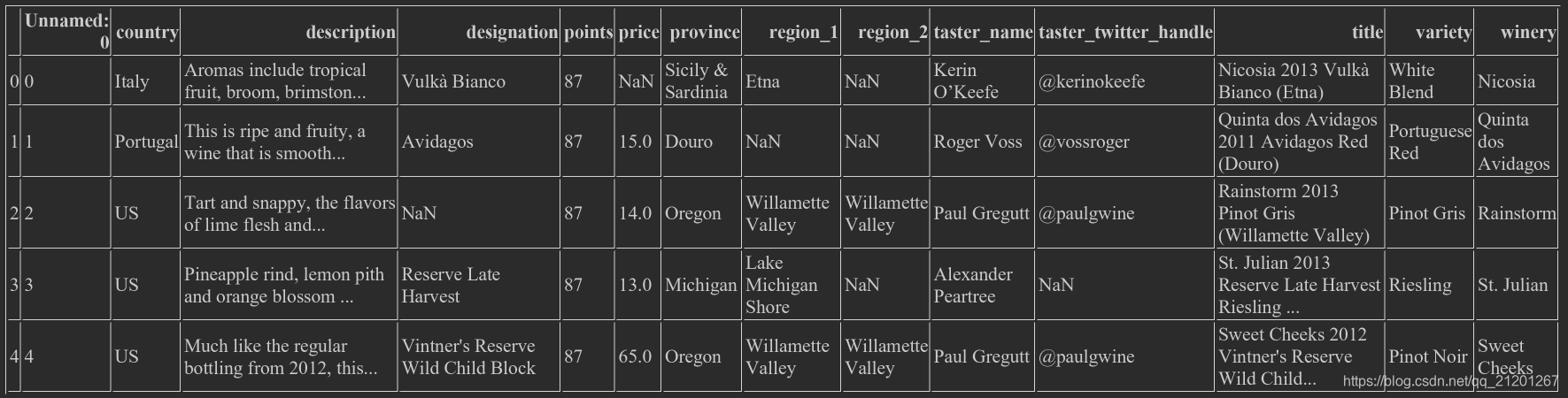
- 可以自定义索引列,
index_col=, 可以是列的序号,或者是列的 name
wine_rev = pd.read_csv("winemag-data-130k-v2.csv", index_col=0)
wine_rev.head()
(下图比上面少了一列,因为定义了index列为0列)
- 保存,
to_csv('xxx.csv')
wine_rev.to_csv('XXX.csv')
2. Indexing, Selecting, Assigning
2.1 类python方式的访问
item.col_name # 缺点,不能访问带有空格的名称的列,[]操作可以
item['col_name']
wine_rev.country
wine_rev['country']
0 Italy
1 Portugal
2 US
3 US
4 US
...
129966 Germany
129967 US
129968 France
129969 France
129970 France
Name: country, Length: 129971, dtype: object
wine_rev['country'][0] # 'Italy',先取列,再取行
wine_rev.country[1] # 'Portugal'
2.2 Pandas特有的访问方式
2.2.1 iloc 基于index访问
-
要选择DataFrame中的第一行数据,我们可以使用以下代码:
-
wine_rev.iloc[0]
country Italy
description Aromas include tropical fruit, broom, brimston...
designation Vulkà Bianco
points 87
price NaN
province Sicily & Sardinia
region_1 Etna
region_2 NaN
taster_name Kerin O’Keefe
taster_twitter_handle @kerinokeefe
title Nicosia 2013 Vulkà Bianco (Etna)
variety White Blend
winery Nicosia
Name: 0, dtype: object
loc和iloc都是行第一,列第二,跟上面python操作是相反的
wine_rev.iloc[:,0],获取第一列,:表示所有的
0 Italy
1 Portugal
2 US
3 US
4 US
...
129966 Germany
129967 US
129968 France
129969 France
129970 France
Name: country, Length: 129971, dtype: object
wine_rev.iloc[:3,0],:3 表示 [0:3)行 0,1,2
0 Italy
1 Portugal
2 US
Name: country, dtype: object
- 也可以用离散的
list,来取行,wine_rev.iloc[[1,2],0]
1 Portugal
2 US
Name: country, dtype: object
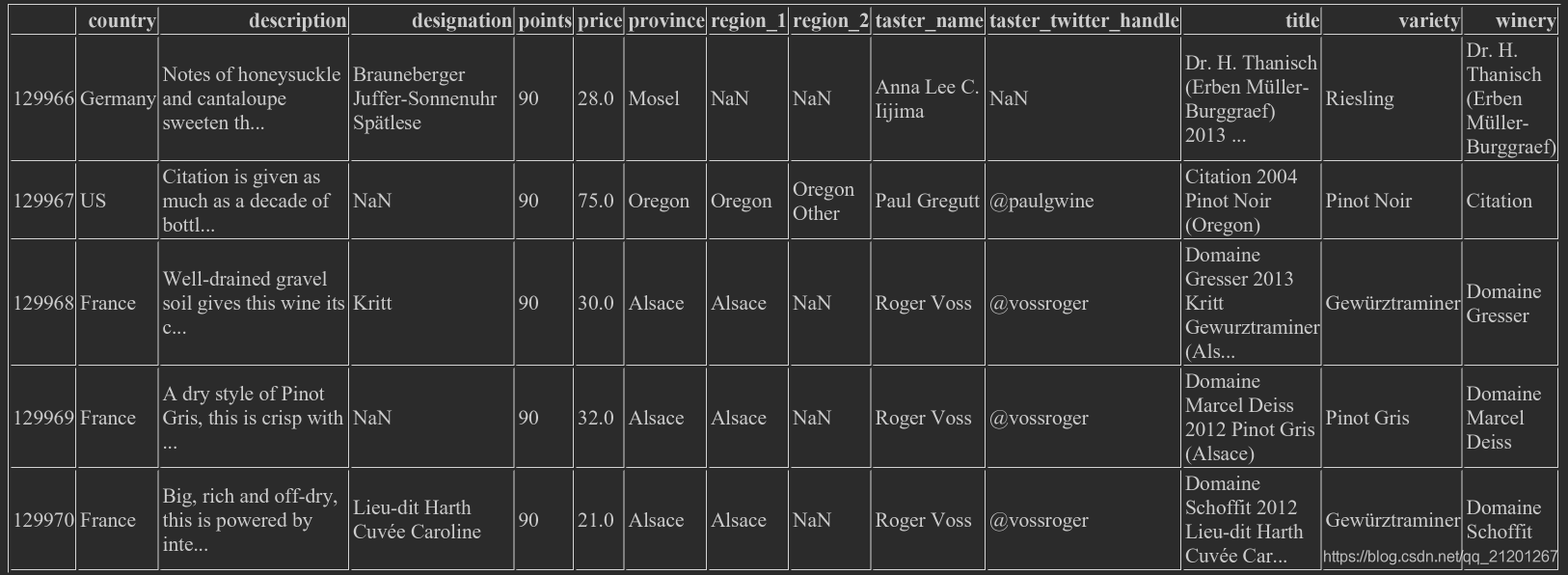
- 取最后几行,
wine_rev.iloc[-5:],倒数第5行到结束
2.2.2 loc 基于label标签访问
wine_rev.loc[0, 'country'],行也可以使用[0,1]表示离散行,列不能使用index
'Italy'
wine_rev.loc[ : 3, 'country'],跟iloc不一样,这里包含了3号行,loc包含末尾的
0 Italy
1 Portugal
2 US
3 US
Name: country, dtype: object
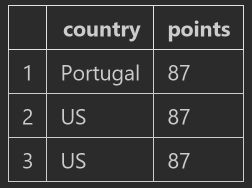
wine_rev.loc[ 1 : 3, ['country','points']],多列用 list 括起来
loc的优势,例如有用字符串 index 的行,df.loc['Apples':'Potatoes']可以选取
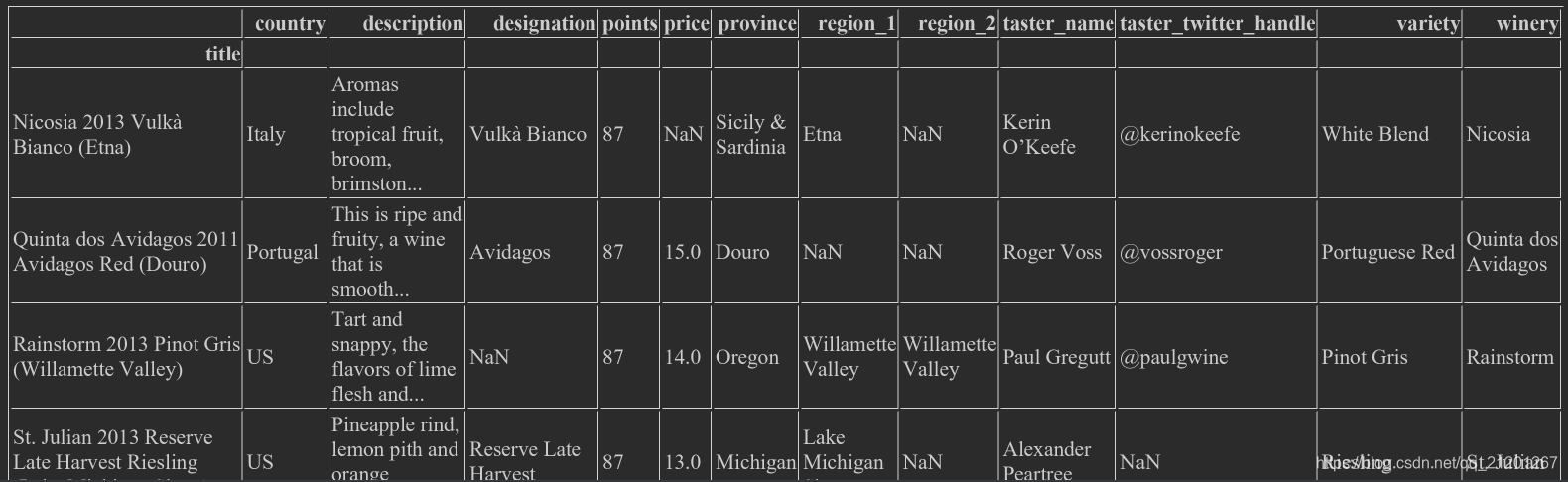
2.3 set_index() 设置索引列
set_index()可以重新设置索引,wine_rev.set_index("title")
2.4 Conditional selection 按条件选择
2.4.1 布尔符号 &,|,==
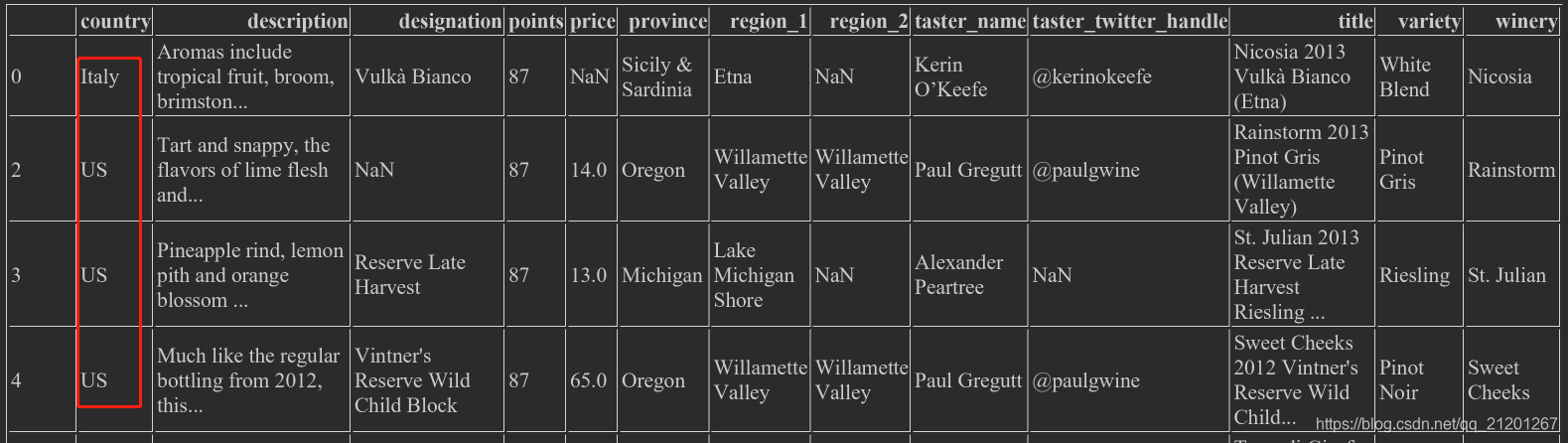
wine_rev.country == 'US',按国家查找, 生成了Seriesof True/False,可用于loc
0 False
1 False
2 True
3 True
4 True
...
129966 False
129967 True
129968 False
129969 False
129970 False
Name: country, Length: 129971, dtype: bool
wine_rev.loc[wine_rev.country == 'US'],把 US 的行全部选出来
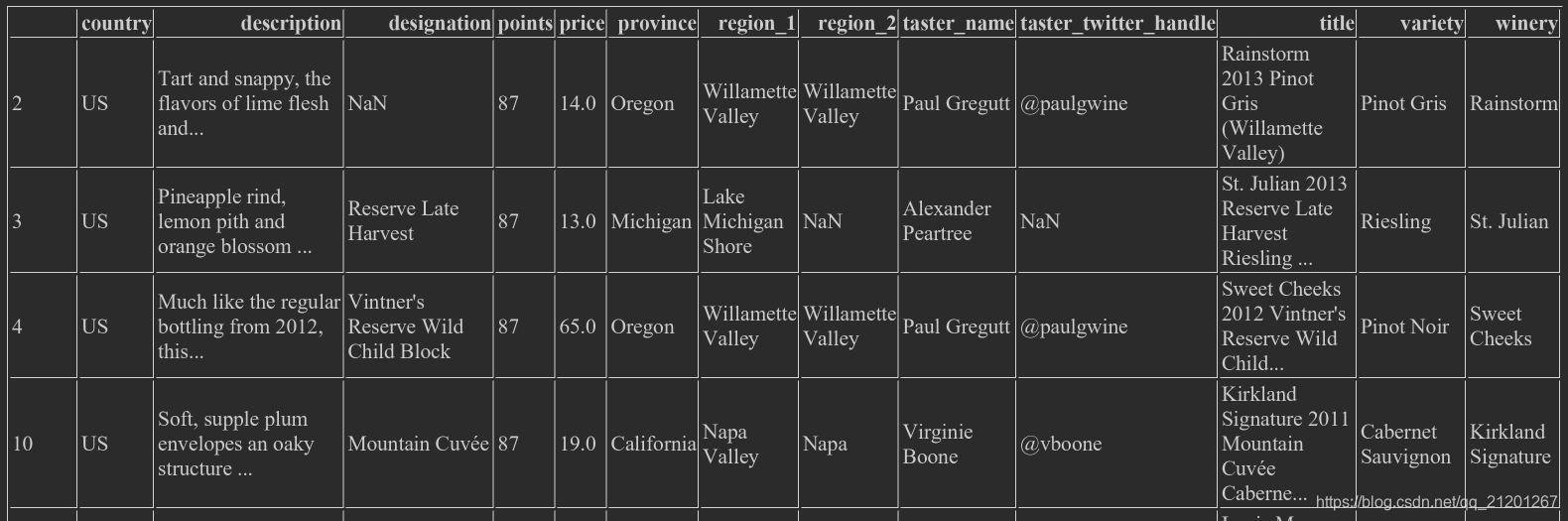
wine_rev.loc[(wine_rev.country == 'US') & (wine_rev.points >= 90)],US的&且得分90以上的- 还可以用
|表示或(像C++的位运算符号)
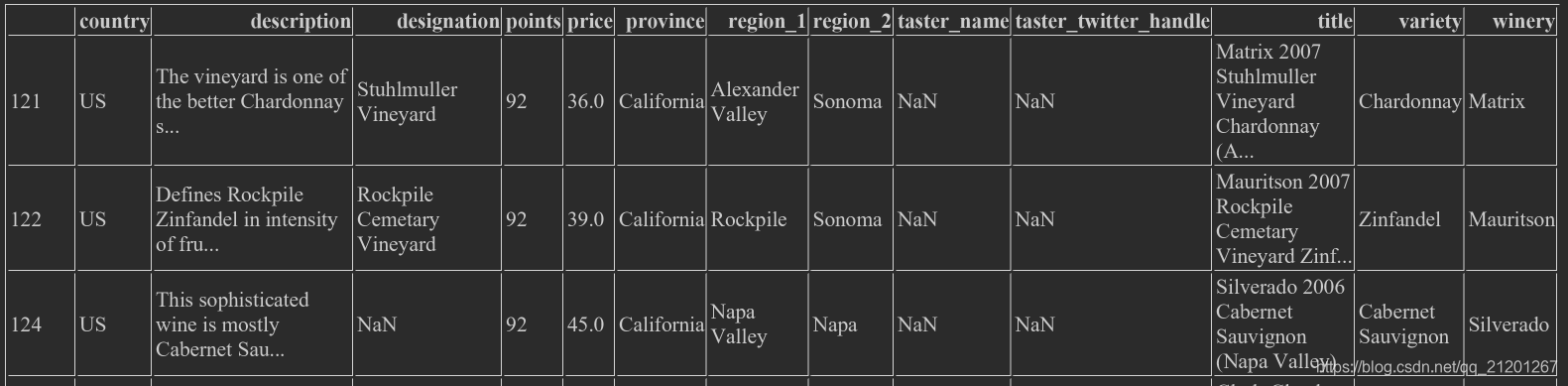
2.4.2 Pandas内置符号 isin,isnull、notnull
wine_rev.loc[wine_rev.country.isin(['US','Italy'])],只选 US 和 Italy 的行
wine_rev.loc[wine_rev.price.notnull()],价格不为空的wine_rev.loc[wine_rev.price.isnull()],价格为NaN的
2.5 Assigning data 赋值
2.5.1 赋值常量
wine_rev['critic'] = 'Michael',新加了一列wine_rev.country = 'Ming',已有的列的value会直接被覆盖

2.5.2 赋值迭代的序列
wine_rev['test_id'] = range(len(wine_rev),0,-1)