当我们在清洗数据时往往会将带有空值的行删除,不论是DataFrame还是Series的index都将不再是连续的索引了,那么这个时候我们可以使用reset_index()方法来重置它们的索引,以便后续的操作。
具体例子:
import pandas as pd import numpy as np df = pd.DataFrame(np.arange(20).reshape(5,4),index=[1,3,4,6,8]) print(df)
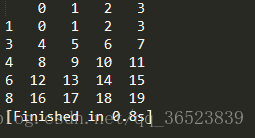
我们使用reset_index()来处理:
print(df.reset_index())
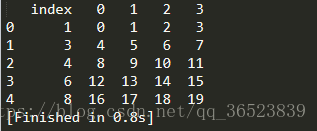
可以看到此时获得了新的index列,而原来的index变成了我们的数据列,保留了下来。
如果我们不想保留原来的index,直接使用重置后的索引,那么可以使用参数drop=True,默认值是False
print(df.reset_index(drop=True))

这里写这个的目的是为了后面对数据处理的应用:
举个例子:
新建一个空的DataFrame,只有列索引,没有对应的数据,当你需要引用对应的Series数据到DataFrame中时
如果每个Series的index都不一样,那么添加时就会出现NaN值,甚至是错误提示:ValueError: cannot reindex from a duplicate axis
import pandas as pd
import numpy as np
df = pd.DataFrame(columns=['a','b'])
print(df)
print("--------------------")
b = pd.Series([1,1,1,1,1],index=[0,1,3,4,5])
a = pd.Series([2,2,2,2,2,2],index=[1,2,3,4,6,7])
df['a'] = a
df['b'] = b
print(df)
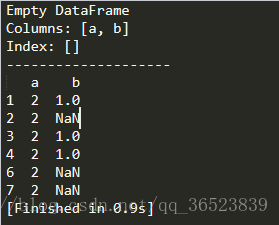
明显看到b的2索引为空值,这是因为b没有2这个索引,如果我们需要它们从0开始按一个顺序排列,那么我们需要使用reset_index()的处理。