Pandas是什么?
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
利器之一:Series
它是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
利器之一:DataFrame
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
一、Series类型可以由如下类型创建:
Series类型由一组数据及与之相关的数据索引组成
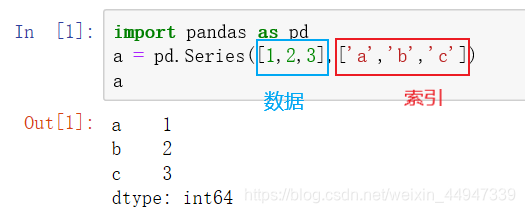
Series类型可以由如下类型创建:
• Python列表,index与列表元素个数一致
• 标量值,index表达Series类型的尺寸
• Python字典,键值对中的“键”是索引,index从字典中进行选择操作
• ndarray,索引和数据都可以通过ndarray类型创建
• 其他函数,range()函数等
1、从标量值创建
In [2]: import pandas as pd
a = pd.Series(25,index=['a','b','c'])#不能省略index
a
Out[2]:
a 25
b 25
c 25
dtype: int64
2、从字典类型创建
In [3]: import pandas as pd
s = pd.Series({'a':5,'b':6,'c':7})
s
Out[3]:
a 5
b 6
c 7
dtype: int64
In [4]: import pandas as pd
s = pd.Series({'a':5,'b':6,'c':7},index=['c','a','b','d'])#index从字典中进行选择操作
s
Out[4]:
c 7.0
a 5.0
b 6.0
d NaN
dtype: float64
3、从ndarray类型创建
In [5]: import pandas as pd
import numpy as np
n = pd.Series(np.arange(5))
n
Out[5]:
0 0
1 1
2 2
3 3
4 4
dtype: int32
二、Series类型的基本操作
1、Series类型包括index和values两部分
In [6]:import pandas as pd
s = pd.Series({'a':5,'b':6,'c':7,'d':8},index=['c','a','b','d']) #改变索引
s
Out[6]:
c 7
a 5
b 6
d 8
dtype: int64
In [7]:s.index #.index 获得索引
Out[7]:Index(['c', 'a', 'b', 'd'], dtype='object')
In [8]:s.values #.values 获得数据
Out[8]:array([7, 5, 6, 8], dtype=int64)
2、Series类型的操作类似ndarray类型:
• 索引方法相同,采用 [ ]
• NumPy中运算和操作可用于Series类型
• 可以通过自定义索引的列表进行切片
• 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
In [9]:import pandas as pd
s = pd.Series([1,2,3,4],['a','b','c','d'])
s
Out[9]:
a 1
b 2
c 3
d 4
dtype: int64
In [10]:s[3] #输出第4个索引的值
Out[10]:4
In [11]:s[:3] #输出第1~3个索引的值
Out[11]:
a 1
b 2
c 3
dtype: int64
In [12]:s[s>s.median()]#输出比中位数大的
Out[12]:
c 3
d 4
dtype: int64
3、Series类型的操作类似Python字典类型:
• 通过自定义索引访问
• 保留字in操作
• 使用.get()方法
In [13]:import pandas as pd
b = pd.Series([5,6,7,8],['a','b','c','d'])
b
Out[13]:
a 5
b 6
c 7
d 8
dtype: int64
In [14]:b['b'] #输出索引为b的值
Out[14]:8
In [15]:'c'in b #判断索引c是否在b中
Out[15]:True
In [16]:2 in b #判断数值2是否在b中
Out[16]:False
In [17]:b.get('b') #获取索引为b的值
Out[17]:6
4、Series 类型的name属性
Series对象和索引都可以有一个名字,存储在属性.name中
In [18]:import pandas as pd
b = pd.Series([5,6,7,8],['a','b','c','d'])
b
Out[18]:
a 5
b 6
c 7
d 8
dtype: int64
In [19]:b.name
In [20]:b.name = 'series对象'
In [21]:b.index.name = '索引列'
In [23]:b
Out[23]:
索引列
a 5
b 6
c 7
d 8
Name: series对象, dtype: int64
5、Series类型的修改
Series对象可以随时修改并即刻生效
In [24]:import pandas as pd
b = pd.Series([5,6,7,8],['a','b','c','d'])
b
Out[24]:
a 5
b 6
c 7
d 8
dtype: int64
In [25]:b['a','b']=1 #把索引为a,b的值该为1
In [26]:b
Out[26]:
a 1
b 1
c 7
d 8
dtype: int64
三、DataFrame类型可以由如下类型创建:
• 二维ndarray对象
• 由一维ndarray、列表、字典、元组或Series构成的字典
• Series类型
• 其他的DataFrame类型
1、从二维ndarray对象创建
In [27]:import pandas as pd
import numpy as np
d = pd.DataFrame(np.arange(10).reshape(2,5))
d
Out[27]:
0 1 2 3 4 #0 1 2 3 4是自动列索引 0,1是自动行索引
0 0 1 2 3 4
1 5 6 7 8 9
2、从一维ndarray对象字典创建
In [28]:import pandas as pd
dt = {'one': pd.Series([1,2,3],index=['a','b','c']),
'two': pd.Series([9,8,7,6],index=['a','b','c','d'])}
d = pd.DataFrame(dt)
d
Out[28]:
one two
a 1.0 9
b 2.0 8
c 3.0 7
d NaN 6
In [29]:pd.DataFrame(dt,index=['b','c','d'],columns=['two','three'])
Out[29]:
two three #数据根据行列索引自动补齐
b 8 NaN
c 7 NaN
d 6 NaN
3、从列表类型的字典创建
In [30]import pandas as pd
dt = {'one': [1,2,3,4], 'two':[5,6,7,8]}
d = pd.DataFrame(dt,index =['a','b','c','d'])
d
Out[30]:
one two
a 1 5
b 2 6
c 3 7
d 4 8
