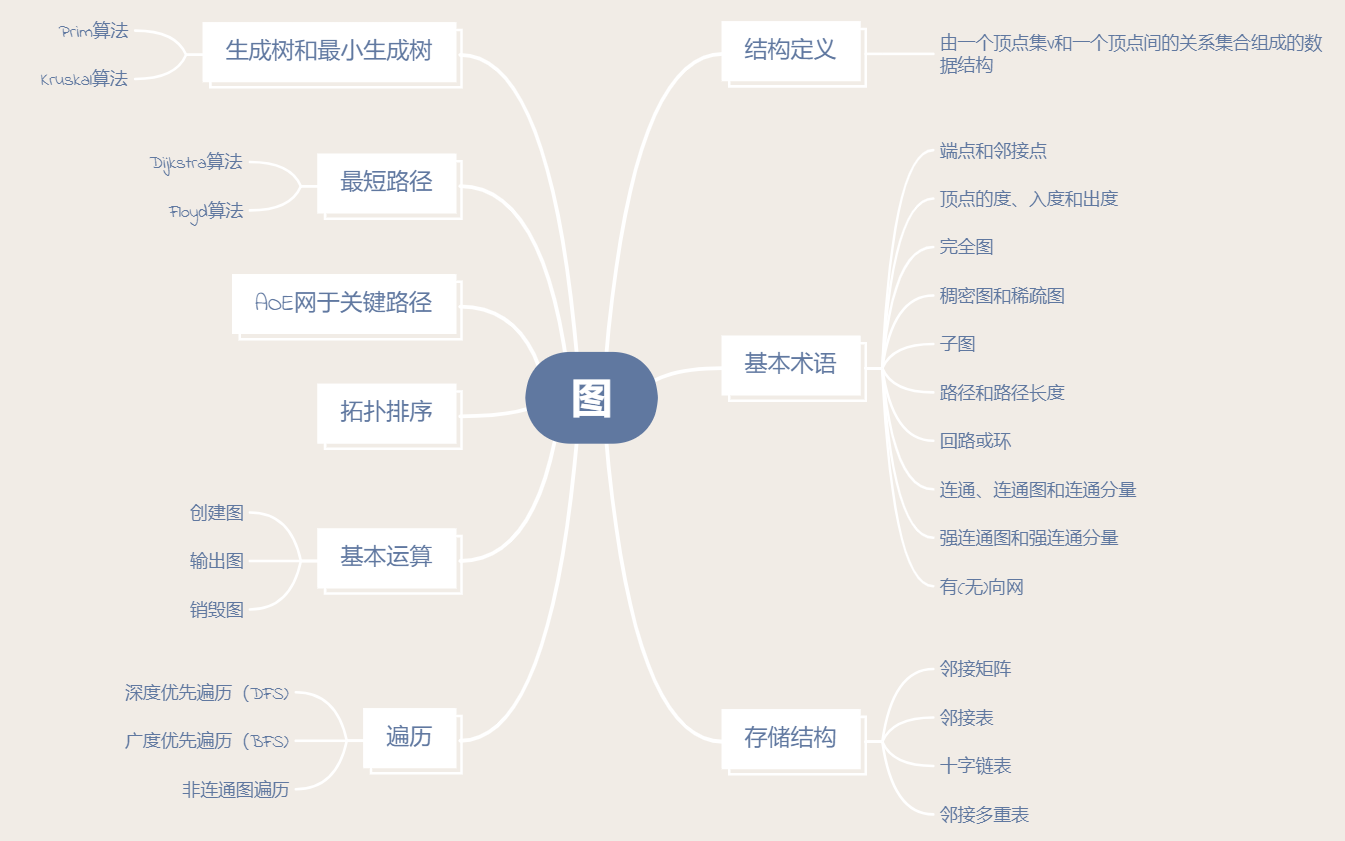
图
一.思维导图
二.重要概念的笔记
1.假设图中有n个顶点,e条边
含有e=n(n-1)/2条边的无向图称为完全图;
含有e=n(n-1)条弧的有向图称为有向完全图;
若边或弧的个数e<nlogn,则称作稀疏图,否则称为稠密图。
2.
3.无向图的领接矩阵是对称的,有向图的领接矩阵可能是不对称的
4.在有向图中 统计第i行1的个数可得顶点i的出度(以顶点为头的弧的数目);
统计第j列1的个数可得顶点j的入度(以顶点为尾的弧的数目)
5.性质:任意无向图中,若有n个顶点和小于n-1条边,则必是非连通图;若有多于n-1条边,则一定有环
6.有向树:有向图中恰有一个顶点的入度为0,其余顶点的入度均为1
7.


8.结点i的度=邻接矩阵中第i行或第i列之和
9.构造无向图算法
O(n²+e*n)
Status CreateUDN(MGraph &G) {//采用数组(邻接矩阵)表示法,构造无向网G
scanf(&G.vexnum, &G.arcnum, &Inclnfo);//Inclnfo为0则各弧不含其他信息
for (i = 0;i < G.vexnum;++i)scanf(&G.vexs[i]);//构造顶点向量
for (i = 0; i < G.vexnum; ++i) //初始化邻接矩阵
for (j = 0;j < G.vexnum;++j)
G.arcs[i][j] = { INFINITYNULL }; //(adj, info)
for (k = 0;k < G.arcnum;++k) {//构造邻接矩阵
scanf(&v1, &v2, &w); //输入一条边依附的顶点及权值
i = LocateVex(Gv1);j = LocateVex(G, v2); //确定v1和v2在G中位置
G.arcs[i][j].adj = w; //弧<v1,v2>的权值
if (Inclnfo)Input(*G.arcs[i]j].info); //若弧含有相关信息,则输入
G.arcs[j][i] = G.arcs[i][j]; //置<vl,v2>的对称弧<v2,v1>
}
return OK;
}// CreateUDN
10.对于稀疏图而言,邻接表比邻接矩阵节省存储空间
11.构造有向图算法
O(e*n)
Status CreateDG(OLGraph& G) { //采用十字链表存储表示,构造有向G(G.kind=DG)
scanf(&G.vexnum, &G.arcnum, &Inclnfo); //lnclnfo为0则各弧不含其他信息
for (i = 0; i < G.vexnum;++i) { //构造表头向量
scanf(&G.xlist[i].data); //输入顶点值
G.xlist[i].firstin = NULL;G.xlist[i].firstout = NULL; //初始化指针
}
for (k = 0;k < G.arcnum;++k) {//输入各弧并构造十字链表
scanf(&v1, &v2); //输入一条弧的始点和终点
i = LocateVex(G, v1); j = LocateVex(G, v2);//确定v1和v2在G中位置
p = (ArcBox*)malloc(sizeof(ArcBox)); //假定有足够空间
*p = (ijG.xlist[j].firstin, G.xlist[i].firstout, NULL);//对弧结点赋值
// { tailvex,headvex,hlink,tlink,info )
G.xlist[j].firstin = G.xlist[i].firstout = p;//完成在入弧和出弧链头的插入
if (Inclnfo)Input(*p->info); //若弧含有相关信息,则输入
}
}//CreateDG
12.四种存储结构的优缺点:
(1)邻接矩阵
【优点】容易实现图的各种基本操作,比如判断顶点之间是否存在边,仅耗费O(1)时间;
【缺点】即使边数<<n²,也需要占用O(n²)存储单元,读入数据也需耗费同等时间
(2)邻接表
【优点】存储空间相当于结点数和边数相加
【缺点】有向图求入度和出度或者查找进入某顶点不易需遍历整个邻接表;
无向图同一条边对应两个表结点浪费存储空间;
【改进】建立逆邻接表
(3)十字链表
【优点】查找进入或离开顶点的弧都容易;求顶点的出度和入度方便;建立十字链表时间复杂度与邻接表相同
(4)邻接多重表
【优点】同一条边只对应一个边结点,避免数据冗余;建立邻接多重表时间复杂度与邻接表相同,且各种基本操作实现也与邻接表相似
13.深度优先搜索相当于树的先根遍历:利用递归
邻接矩阵:O(n²)
邻接表:O(n+e)
Boolean visited[MAX]; //访问标志数组
Status(*VisitFunc) (int v); //(全局)函数指针变量
void DFSTraverse(Graph G, Status(*Visit) (int v)) {
VisitFunc = Visit;
for (v = 0;v < G.vexnum;++v) visited[v] = false;
for (v = 0;v < G.vexnum;++v)
if (!Visited[v]) DFS(G, v);
}
void DFS(Graph G, int v) {
Visited[v] = true;
VisitFunc(v);
for (w = FirstAdjVex(G, v);w;w = NextAdjVex(G, v, w))
if (!Visited[w]) DFS(G, w);
}
14.广度优先搜索类似于树的层序遍历:利用队列
Boolean visited[MAX]; //访问标志数组
Status(*Visit) (int v); //(全局) 函数指针变量 一次;
void BFSTraverse(Graph G, Status(*Visit) (int v)) {
for (v = 0;v < G.vexnum;++v)visited[v] = FALSE;
InitQueue(Q);
for (v = 0;v < G.vexnum; ++v)
if (Visited[v]) {
Visited[v] = TRUE;Visit(v);EnQueue(Q,v);
while (!EmptyQueue(Q)) {
DeQueue(Q,u);
for (w = FirstAdjVex(G, u);w; w = NextAdjVex(G, u, w))
if (!Visited[w])(Visited[w] = TRUE;Visit(w);EnQueue(Q,w);
}
}
}
}
15.算法:生成非连通图的深度优先森林
以孩子兄弟链表作为生成森林的存储结构
void DFSForest(Graph G, CSTree& T) {
T = NULL;
for (v = 0;v < G.vexnum;++v)visited[v] = false;
for (v = 0;v < G.vexnum;++v)
if (!Visited[v]) {
p = (CSTree)malloc(sizeof(CSNode));
*p = [GetVex(G, V), NULL, NULL];
if (!T) T = p;
else q->nextsibling = p;
q = p;
DFSTree(G, v, p);
}
}
void DFSTraverse(Graph G, Status(*Visit) (int v)) {
VisitFunc = Visit;
for (v = 0;v < G.vexnum;++v)visited[v] = false;
for (v = 0;v < G.vexnum; ++v)
if (!Visited[V]) DFS(G, v);
}
16.求强连通分量

17.
18.普里姆(Prim)算法:
【基本思想】
第一步:取图中任意一个顶点 v 作为生成树的根;
第二步:往生成树上添加新的顶点 w。在添加的顶点
w 和已经在生成树上的顶点v 之间必定存在一条边,
并且该边的权值在所有连通顶点 v 和 w 之间的边
中取值最小;
第三步:继续往生成树上添加顶点,直至生成树上
含有 n 个顶点为止。
void MiniSpanTree_P(MGraph G, VertexType u) {
//用普里姆算法从顶点u出发构造网G的最小生成树
k = LocateVex(G, u);
for (j = 0; j < G.vexnum; ++j)//辅助数组初始化
if (j != k)
closedge[j] = { u,G.arcs[k][j].adj };
closedge[k].lowcost = 0; //初始,U={u}
for (i = 0; i < G.vexnum; ++i) {
继续向生成树上添加顶点;
}
k = Min(closedge);//求出加入生成树的下一个顶点k
printf(closedge[k].adjvex, G.vexs[k]);
//输出生成树上一条边
closedge[k].lowcost = 0;//第k顶点并入U集
for (j = 0; j < G.vexnum; ++j)
//修改其它顶点的最小边
if (G.arcs[k][j].adj < closedge[j].lowcost)
closedge[j] = { G.vexs[k], G.arcs[k][j].adj };
19.克鲁斯卡尔(Kruscal)算法:
【 基本思想】
第一步:构造一个只含 n 个顶点的子图 SG;
第二步:从权值最小的边开始,若它的添加不使SG
中产生回路,则在 SG 上加上这条边;
第三步:如此重复,直至加上 n-1 条边为止。
构造非连通图 ST = (V, { });
k = i = 0; // k 计选中的边数
while (k < n - 1) {
++i;
检查边集 E 中第 i 条权值最小的边(u, v);
若(u, v)加入ST后不使ST中产生回路,则输出边(u, v);
且k++;
}
20.普里姆算法:O(n2)、适用于稠密图
克鲁斯卡尔算法:O(eloge)、适用于稀疏图
21.拓扑排序: 从有向图中选取一个没有前驱的顶点,并输出之; 从有向图中删去此顶点以及所有以它为尾的弧;重复上述两步,直至图空,或者图不空但找不到无前驱的顶点为止。
CountInDegree(G, indegree); //对各顶点求入度
InitStack(S);
for (i = 0; i < G.vexnum; ++i)
if (!indegree[i]) Push(S, i); //入度为零的顶点入栈
count = 0; //对输出顶点计数
while (!EmptyStack(S)) {
Pop(S, v); ++count; printf(v);
for (w = FirstAdj(v); w; w = NextAdj(G, v, w)) {
--indegree(w); // 弧头顶点的入度减一
if (!indegree[w]) Push(S, w);//新出度的入度为零的顶点入栈
}
}
if (count < G.vexnum) printf("图中有回路");
22.整个工程完成的时间为:从有向图的源点到汇点的最长路径;
“关键活动”指的是:该弧上的权值增加将使有向图上的最长路径的长度增加;
事件vi的最早发生时间:从开始点v1到vi的最长路 径长度,用ve(i)表示;
事件vi的最迟发生时间:在不推迟整个工期的前提 下,事件vi允许的最晚发生时间,用vl(i)表示
ve(j) = Max{ve(i) +dut(<i,j>)}
vl(i) = Min{vl(j) - dut(<i,j>)}
23.关键路径的算法:
⑴输入e条弧,建立AOE-网。
⑵从源点v0出发,令ve[0] = 0, 按拓扑有序求各顶点的最早发生时间vei,如果得到的拓扑序列中顶点个数小于网中顶点数n,说明网中存在环,不能求关键路径,算法终止;否则执行步骤 ⑶
⑶从汇点v**n出发,令vl[n-1] = ve[n-1]; 按逆拓扑有序求其余各顶点的最迟发生时间vl[i](n- 2≥i≥2);
⑷根据各个顶点的ve和vl值,求每条弧s的e(s)和 l(s)。若某条弧满足e(s) == l(s*),则为关键活动。
24.Floyd算法: 【基本思想】逐个顶点试探
O(n³)
void ShortestPath_FLOYD(MGraph G, PathMatrix& [], DistancMatrix& D) {
//用 Floyd算法求有向网G中各对顶点v和w之间的最短路径P[V][w]及其带权
//长度D[v][w]。若P[v][w][u]为TRUE,u是从v到w当前求得最短路径上的顶点。
for (v = 0;v < G.vexnum;++v) //各对结点之间初始已知路径及距离
for (w = 0;w < G.vexnum;++w) {
D[v][w] = G.arcs[v][w];
for (u = 0;u < G.vexnum;++u) P[v][w][u] = FALSE;
if (D[v][w] < INFINITY) {//从v到w有直接路径
P[v][w][v] = TRUE; P[v][w][w] = TRUE;
}// if
}//for
for (u = 0;u < G.vexnum;++u)
for (v = 0;v < G.vexnum;++v)
for (w = 0;w < G.vexnum;++w)
if (D[v][u] + D[u][w] < D[v][w]) {//从v经u到w的一条路径更短
D[v][w] = D[v][u] + D[u][w];
for (i = 0; i < G.vexnum;++i)
P[v][w][i] = P[v][u][i]l P[u][w][i];
}//if
}//ShorttestPath_FLOYD
25.Dijkstra:【基本思想】按路径长度递增次序产生最短路径算法
O(n³)
void ShortestPath_DIJ(AMGraph G, int v0) {
//初始化
n = G.vexnum;
for (v = 0; v < n; ++v) {
S[v] = false; //s初始为空集
D[v] = G.arcs[v0][v]; //v0到各个顶点的弧的权值
if (D[v] < MaxInt)
Path[v] = v0; //v0和v之间有弧
else Path[v] = -1; //v0和v之间无弧
}
S[v0] = true; //v0加入s
D[v0] = 0; //源点到源点距离为0
for (i = 1;i < n; ++i) {
min = MaxInt;
for (w = 0; w < n; ++w)
if (!S[w] && D[w] < min)
{
v = w; min = D[w];
}//选择一条当前最短路径
S[v] = true; //将v加入s
for (w = 0; w < n; ++w)//加入v后,v0到其他节点需更新
if (!S[w] && (D[v] + G.arcs[v][w] < D[w]) {
D[w] = D[v] + G.arcs[v][w];
Path[w] = v;
}
}
三.疑难问题及解决方案
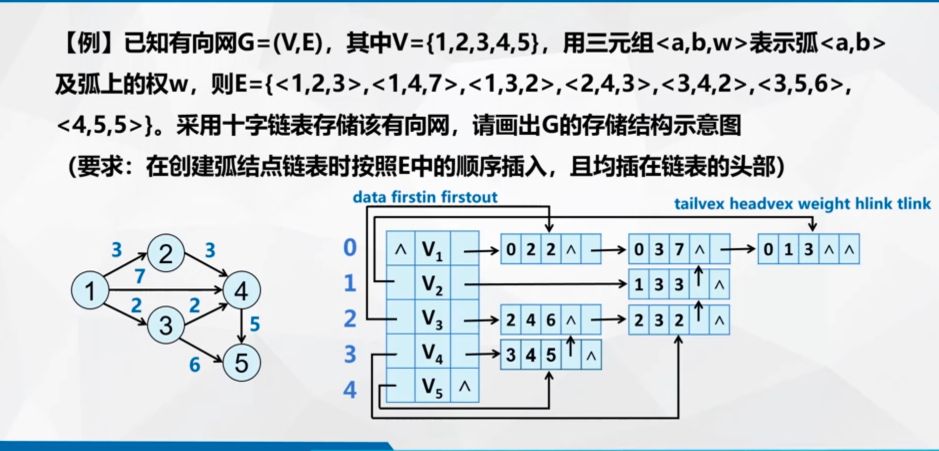
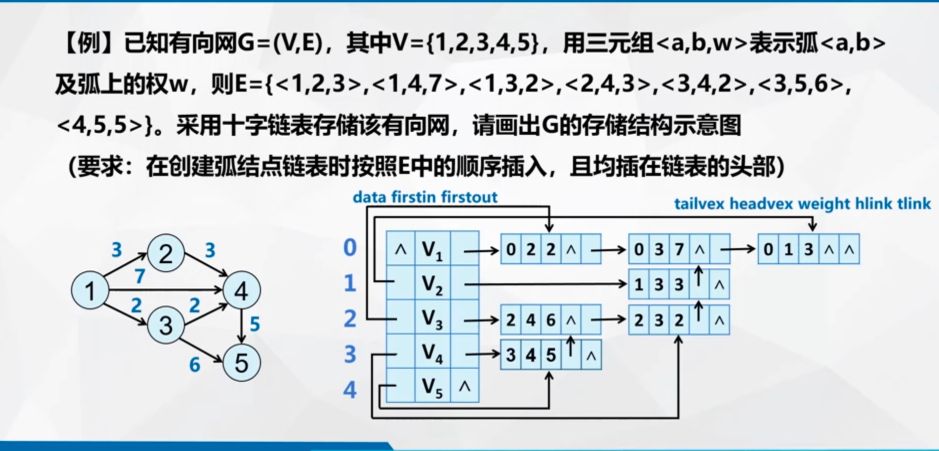
1.十字链表示例
2.无向图的连通分量
3.强连通分量示例
