哈夫曼树(数据结构)
前言
哈夫曼树是二叉树的应用
一.几个术语定义

1.路径
由一结点到另一结点间的分支所构成。
(如1到4的路径为1到3,3到4这两个分支构成)
2.路径长度
路径上的分支数目。
(如1到6的路径长度为3, 即1到3,3到5,5到6)
3.树的外部路径长度(EPL)
各叶结点(外结点)到根结点的路径长度之和。
(如这棵树的叶子结点为2、4、8、7,2的路径长度为1,4的路径长度是2,8的路径长度为4,7的路径长度是3,所以树的外部路径长度为1+2+4+3=10)
4.树的内部路径长度( IPL )
各非叶结点(内结点)到根结点的路径长度之和。
5.树的路径长度(PL)
PL= EPL+ IPL
IPL = 0+1+2+3 = 6
EPL = 1+2+3+4 = 10
PL = 16

6.权值
为树的叶结点赋予一个权值,一般用于表示出现频度、概率值等。
(就是用于表示叶结点的那个圆圈里的树)
7.扩充二叉树
只有度为 2 的内结点和度为 0的外结点。
(没有度为1的结点的二叉树叫做扩充二叉树)
8.结点的带权路径长度
结点到根的路径长度与结点上权的乘积 (wi*li)。
(结点的带权路径长度就是该结点权值与该结点的路径长度的乘积
如5那个结点的带权路经长度为 5*3=15)
9.树的带权路径长度(WPL)
(我们一般关注的是树的带权路径长度)
树中所有叶子结点的带权路径长度之和。
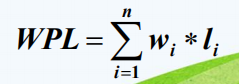
二.哈夫曼树的定义
对于具有不同带权路径长度的扩充二叉树:
(具有相同权值的叶子结点,它组成了不同的二叉树,那么这四个结点形成的二叉树它的带权路径长度是不同的)

• 对于同样一组权值,放在外结点上,组织方式不同,带权路径长度也不同;
• 带权路径长度最小的扩充二叉树叫做哈夫曼树;
• 哈夫曼树中权值大的结点离根最近。
(权值最大的叶子结点越靠近根结点,权值最小的叶子结点越远离根结点)
三.哈夫曼树的构造
1.基本思想
使权大的结点靠近根
2.构造过程
例:
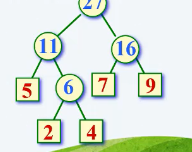
(1)以5个叶子结点为例,我们把这个五个权值的结点作为叶子,构成了一棵有五棵树的森林。

(2)首先我们从这五棵树的森林的集合中选取权值最小的两棵树,对它进行合并,2、4合并得到了6这个内结点,接下来把2,4删掉,把6加入进这个集合,此时,这个森林中就包括4棵树7、5、9、6。
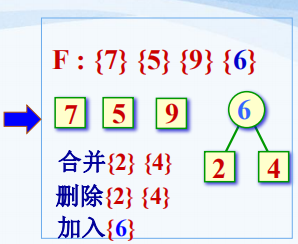
(3)接下来,重复,从新的集合中找的最小的两棵树,一个是5,一个是6,在进行合并得到11,再把5、6从集合中删除,把11加入,这个森林就包括7,9,11三棵树。

(4)重复,仍然合并两个最小的7、9得到16,把7、9删除,插入16,这个森林包含两棵树11、16。

(5)同样,把11和16合并得到27,把11和16删除,再加入合并后的27,此时这个森林中只剩下一棵树,这棵树是一棵二叉树,我们把这可树叫做哈夫曼树。

总结:
操作要点:对权值的合并、删除与替换,总是合并当前值最小的两个。
3.构造算法
前提:
性质:一棵有n个叶子结点的Huffman树有 2*n-1 个结点(2*n-1包括叶子结点和内结点)
存储定义:
① 采用顺序存储结构(一维数组)
② 结点类型定义
typedef struct //用顺序存储结构(一维数组)来描述结点的定义
{
int weght; //权值
int parent,lch,rch; //指向父结点,还有左孩子、右孩子标识的地址
}*HuffmanTree;
例:
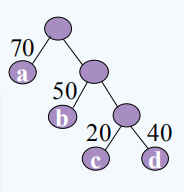
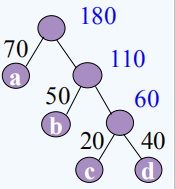
设n=4, w={70,50,20,40},m=2*4-1=7
①进行存储四个叶子结点,并且把双亲左孩子右孩子的初始化都是零

②从中选出两个最小的合并,删除,插入重读操作,改变各结点双亲、左孩子、右孩子的值。
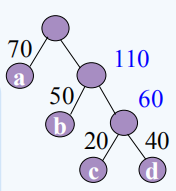

③

代码描述:
(把创建哈夫曼树的过程封装为函数)
typedef struct //用顺序存储结构(一维数组)来描述结点的定义
{
int weght; //权值
int parent,lch,rch; //指向父节点,还有左孩子、右孩子标识的地址
}*HuffmanTree;
void CreatHuffmanTree (HuffmanTree HT,int n)
{
if(n<=1) return; //叶子小于等于1,不合适,不是哈夫曼树
m=2*n-1; //先算出m,m表示总的结点个数
HT=new HTNode[m+1]; //然后动态分配了m+1个结点
//为什么创建m+1个呢?因为0号单元未用,HT[m]表示根结点,从1到m表示这m个结点
for(i=1;i<=m;++i) //对m个结点,对它的每一个左孩子右孩子双亲都初始化为0
{
HT[i].lch=0;
HT[i].rch=0;
HT[i].parent=0;
}
for(i=1;i<=n;++i) //输入所有叶子结点的权值
cin>>HT[i].weight;
for( i=n+1;i<=m;++i) //构造 Huffman树:每次选两个最小的,然后把它们的双亲、左孩子、右孩子改一下
{
Select(HT,i-1, s1, s2);
//每次(在这棵树的叶子结点中)在HT[k](1≤k≤i-1)中选择两个其双亲域为0,
// 并且权值最小的结点,
// 并返回它们在HT(数组)中的序号s1和s2
HT[s1].parent=i; HT[s2] .parent=i;
//表示从F中删除s1,s2 (改s1的双亲,改s2的双亲)
HT[i].lch=s1; HT[i].rch=s2 ;
//s1,s2分别作为i的左右孩子 (改新创建的第i个的左孩子、右孩子)
HT[i].weight=HT[s1].weight + HT[s2] .weight;
//i 的权值为左右孩子权值之和 (它的权值是s1的权值加上s2的权值的和)
}
}
四.哈夫曼编码
1.主要用途
实现数据压缩
例:给出一段报文(报文就是在网络上传输的一些数据),报文中只包含字符集合 { C, A, S, T,H },各个字符出现的频度(次数)是 W={ 2, 7, 4, 5,9 }(也就是权值)。
✓若给每个字符以等长编码(3位二进制)
(因为一共有5个字符,五个字符用二进制编码肯定是要用三位才能编码的,因为2的3次方是8,5是小于8的但5也是大于4的)
✓ C : 000 A : 001 S : 010 T : 011 H:100
✓则发送这27(因为5个字符一共出现了27次)个字符时,总编码长度为 ( 2+7+4+5+9 ) * 3 = 81。
✓能否减少总编码长度,使得发出同样报文,可以用最少的二进制代码?
↓↓↓(我们考虑用哈夫曼树)
2.设计哈夫曼编码
例:字符集合 { C, A, S, T,H },出现的频度(次数)是 W={ 2, 7, 4, 5,9 }。
(1)基本思想:
概率大的字符用短码,概率小的用长码,构造哈夫曼树,写出哈夫曼编码。
(2)构造Huffman树
①字符出现的概率{ 2/27, 7/27, 4/27, 5/27,9/27 },化整为 { 2, 7, 4, 5,9 }作为叶结点上的权值, 建立Huffman树。
② 建好以后,左分支赋 0,右分支赋 1,得Huffman编码(变长编码)。

③写出哈夫曼编码
(概率就是权值)

✓总编码长度(7+5+9)*2+( 2+4 )*3 = 60
✓比等长编码的情形(81)要短。
(所以就实现了数据的压缩)
(3)注意:
Huffman编码是一种前缀编码
即:任一个二进制编码不是其它二进制编码的前缀。解码时不会混淆。
3.哈夫曼编码小结
(1)哈夫曼编码是不等长编码。
(2)哈夫曼编码是前缀编码,即任一字符的编码都不是另一字符编码的前缀。
(3)哈夫曼编码树中没有度为1的结点。若叶子结点的个数为n,则哈夫曼编码树的结点总数为 2n-1。
(4)发送过程:根据由哈夫曼树得到的编码表送出字符数据。
(5)接收过程:按左0、右1的规定,从根结点走到一个叶结点,完成一个字符的译码。反复此过程,直到接收数据结束。
后续

