动态规划
动态规划思想:将原问题拆解成若干子问题,同时保存子问题的答案,使得每个子问题只求解一次,最终获得原问题的答案。
求解思路

- 大多数动态规划问题都是一个递归问题;
- 在递归的过程中会发现很多重叠子问题(出现重复计算子问题的情况);
- 可以使用记忆化搜索的方式来解决问题;
- 通常解决动态规划问题时,先自顶向下的思考问题,最后再通过自底向上的动态规划解决问题。
在动态规划中都是通过这种思路来解决问题的。
下面以求解斐波那契数列来说明上面的过程。
斐波那契数列
递归问题
这个式子可以很容易的写成递归形式。
def fib(n):
if n == 0:
return 0
if n == 1:
return 1
return fib(n-1) + fib(n-2)
递归形式的思路虽然简单,但是这段代码的耗时是指数增长的。
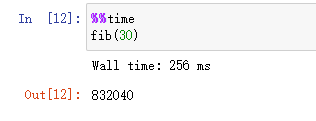
在jupyter上求fib(30)就耗时256毫秒。
重叠子问题
下面我们来看下为什么计算这么慢。
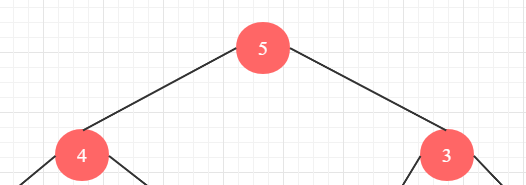
如果我们想要计算fib(5),那么根据定义,我们要计算fib(4)和fib(3)。

如果要计算4,那么就要计算3和2。以此类推,我们可以画出整个计算斐波那契数列的递归树。
在这个递归树种,每个叶子节点都到了1或0的终止条件。这里每个节点都是一次计算。
从上图可以发现,我们进行了多次的重复计算。

拿求解fib(2)来说,我们计算了3次。
记忆化搜索-自顶向下的解决问题
对于这些重复计算,是否可以只计算一次呢。很简单的思路是用一个数据结构将之前的计算结果保存起来。
memo = {} #保存计算结果
def fib(n):
if n == 0:
return 0
if n == 1:
return 1
if n not in memo: # 如果没有计算过再去计算
memo[n] = fib(n-1) + fib(n-2)
return memo[n]
这种方式就是记忆化搜索。我们使用了递归搜索的方式,但是使用了memo进行记忆。

现在计算起来就非常快了。

fib(1000)也可以计算了。
记忆化搜索的实质是在递归的基础上加上记忆化的过程。
递归是一种自顶向下的解决问题。也就是说,我们没有从最基本的问题开始解决,而是假设最基本的问题已经解决了。我们已经会求fib(n-1)和fib(n-2)了,那么求fib(n)就是把它们加起来就好了。
通常如果我们能自顶向下的解决问题的话,我们也能自底向上的解决问题。
动态规划-自底向上的解决问题
memo = {}
def fib(n):
memo = {0:0,1:1} #memo中存的就是第i个斐波那契数列
for i in range(2,n+1):
memo[i] = memo[i-1] + memo[i-2]
return memo[n]
这样的一个过程就是自底向上的解决问题,我们先解决小数据量上的结果(i是从2开始的),然后层层递推来解决更大的数据量的问题。
这样的过程就是动态规划。那动态规划和记忆化搜索有什么区别呢,一个最重要的区别就是动态规划去掉了记忆化搜索中的递归调用。我们知道执行递归方法时在操作系统底层会进入入栈出栈操作,实会有一些性能和时间上的开销的。并且动态规划的代码非常简短,高效。
通常解决动态规划问题时,先自顶向下的思考问题,最后再通过自底向上的动态规划解决问题。

 博客专家
博客专家