Panoptic Feature Pyramid Networks
Panoptic Segmentation
在介绍Panoptic Feature Pyramid Networks之前首先介绍一下,Panoptic Segmentation(全景分割)。在论文中经常提出的一个概念就是联合。全景分割的本意就是将Instanse segmentation和semantic segmention进行一种联合,下面是效果的比较图

Panoptic Segmentation 中的几个概念
这是接下来经常会出现的一些单词,我在这里先预热一下
- stuff(填充物):画面中的背景如Sky、Road、Building在Panoptic Segmentation的方法下这一类事物实例ID将会忽略
- things:画面中识别的物体,物体不仅进行了语义分割还进行了实例检测
- panotic quality(PQ):用于识别与分割以及东西与东西性能的详细分类,下面会详细介绍
- TP(true positives):正确的标签与错误标签组成一组
- FN(false negatives):漏报率
- FP(false positives):错误的标签
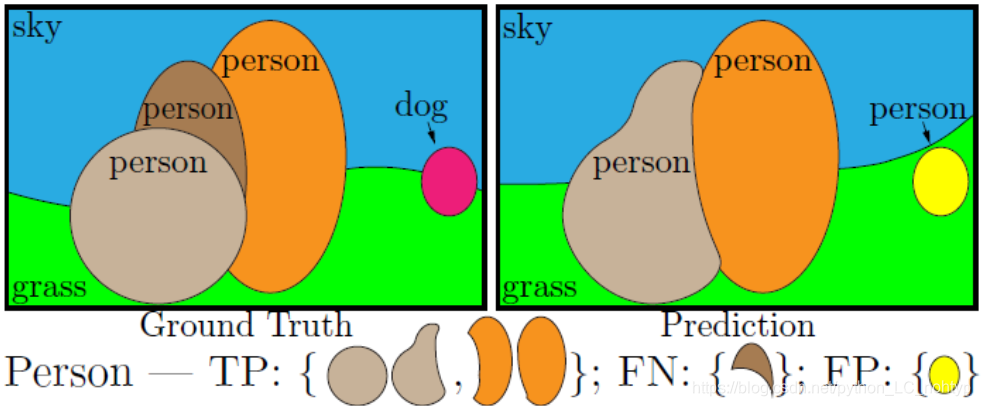
下面用一张图来解释TP、FN和FP
Panoptic Segmentation的核心思想
语义分割的任务为简单地理解为一个图像中的每个像素分配一个类标签(注意,语义分割将事物类视为东西)。实例分割的任务可以简单的理解为将检测对象并分别用包围框或分割掩码对其进行描述。语义和实例分割之间的分裂导致了这些任务方法的并行裂缝。Stuff的语义分割通常建立在全卷积网络上。Things的分类检测就基于区域去进行检测,举个例子Yolo中采取的思想便是将像素点分割,然后确认出有物体的像素点,然后对于有物体的像素设置预选框,然后通过IOU等指标去对框进行筛选,留下一个最为准确的框。然后基于这个框,或者说基于这个区域去进行物体分类。
那么一个自然而然的问题就诞生了,Stuff和things就不可以达成“和解”,两个都要不行吗?一个能产生丰富而连贯的场景分割的统一视觉系统最有效的设计是什么? 于是PanopticSegmentation就出来了。这种方法对于图像中的每个像素打上两个标签,一个是分类标签一个是实例ID并将像素分为两类,stuff和things,stuff的实例ID会被忽略,具有相同标签和id的像素都属于同一个对象,对于无法确定的像素,比如不在分类范围内模糊的像素则会给一个void标签。
PS于实例分割和语义分割之间的关系
- PS是对语义分割的严格概括,PS要求每一个像素都有一个语义标签,如果ground truth没有指定实例,或者所有类都是stuff,那么任务格式是相同的(尽管任务度量不同),此外,包含thing类(每个映像可能有多个实例)可以区分任务
- 实例分割任务需要一种方法来分割图像中的每个对象实例。然而,它允许重叠片段,而全景分割任务只允许为每个像素分配一个语义标签和一个实例id。因此,对于PS,不可能通过构造来实现重叠,之后我们会说明到之中设计对于PS的量度标准有很重要的影响。
Panoptic Sementation的量度标准
现在对于量度实例分割和语义分割有很多的量度标准,这些量度标准都很适合Stuff和things但不是同时。也就是说目前研究实例分割和语义分割会使用不同的量度标准。论文中指出何大神他们认为使用不同的量度标准是目前实例分割和语义分割不能很好的统一的一个主要原因。
所以论文中提出了Panoptic quality(PQ)这种量度标准,论文中介绍PQ既简单又有用,最重要的是它可以用统一的方式来衡量stuff和things的性能。
Panoptic Segmentation Format
任务的格式
Panoptic Segmentation Format的格式可以很简单的进行定义
首先给定一组预先确定的L语义类 ,算法要求一种全景分割的算法可以给每一个像素的图片打上一对标签 , 表示对于像素点的语义分割, 表示对于像素点的实例分割,将用一个class的像素划分为不同的个体
Stuff和物体的标签
语义的标签集由 and 组成,比如 和 ,这些子集分别对应于stuff和thing标签。当像素的标签 ,的时候这个像素就和实例分割的id 就没有关系了,同一个class的stuff全部属于同一个标签。当 的时候所有的且具有相同的 的时候当前像素就会被归类了一个实例。
Panoptic Segmentation的细分指标
Panoptic Segmentation提出一种新的指标,前面也提到过这种指标将把实例分割和语义分割进行一种联合。PQ是用来评估分割的进度和识别的精度的量度。先分别对每一类计算 PQ,再计算所有类的平均值. 对于类别不平衡问题,所以PQ 对此不敏感.但是要注意PQ是对实例分割和语义分割的一种统一,而不是实例分割和语义分割指标的一种结合。也就是说这是这一种新的概念。这种指标就是PQ(Panoptic Quite)使用PQ作为指标主要包括两部(1)片段匹配 (2) 给定匹配的PQ进行计算。接下来分别介绍这两部:
片段匹配(Segment Matching)
在PS中也使用了IoU的概念,并且规定预测和正值的IoU大于0.5的时候才会进行匹配。这个要求,再加上全景分割的非重叠特性,提供了一个独特的匹配:最多可以有一个预测片段与每个ground truth片段匹配。
Theorem 1:下面对计算的方法进一步的解释
加入g是真实的Segment, and 是预测的Segment,之前又提到过 and 是不重合的所以有 ,如果 ,所以我们就可以得到:
由上面几个关系我们又可以得到:
因此我们可以得到如果 那么 就必须小于0.5 ,可以用p和g的作用来证明只有一个ground truth Segment可以有严格大于0.5的预测Segment的IoU。
匹配的IoU必须大于0.5,这就产生了唯一匹配定理,实现了我们想要的两个属性。注意,由于IoU > 0.5的唯一性,任何合理的匹配策略(包括贪婪匹配和最优匹配)都会产生相同的匹配。
PQ 的计算
我们在计算PQ的时候对于每个一个class是独立的并对每一个类取平均值。这样就可以让PQ对于种类的平衡没有那么的敏感。对于任何一个类,唯一的匹配规则会把预测结果分为三组,TP、FP和FN如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ijjxXPdr-1587737073227)(Panopric_Feature_Pyamid_Networks.assets/image-20200424215353324.png)]](https://img-blog.csdnimg.cn/2020042422053148.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3B5dGhvbl9MQ19ub2h0eXA=,size_16,color_FFFFFF,t_70)
PQ可以被这样定义:
这样我们就可以发现了,PQ就是匹配Sement的平均IoU,然后 是用来惩罚匹配错了的,你可以理解为准确度,FP和FN是用来表示识别错的部分的,在分母上加上这部分必然会降低PQ的值啦。注意:所有Sements不论在什么领域都同等重要。此外,如果我们将PQ乘以并除以TP集的大小,则PQ可以看作是分割质量的乘法(SQ)项和认可质量(RQ)项
注:第一项是SQ,第二项是RQ
RQ是我们熟悉的F1分数,广泛用于评估模型精确度的一种指标。SQ只是匹配段的平均IoU。我们找到了PQ = SQ RQ的分解,为分析提供了思路。然而,这两个值不是独立的,因为SQ只在匹配的片段上测量
Void labels
现在我们讨论一下如果处理空白的像素点吧,这一类像素点在之前聊过,不是不在分类范围内的就是模糊的。由于我们经常无法区分这两种情况,所以我们不评估对空像素的预测。
但是注意两点:1. 在匹配的过程中,所有的预测范围内的Void label的像素点是不影响IoU的计算的
2. 在匹配之后,超过匹配阈值的部分空白像素的未匹配的预测段将被删除,并且不会被算作FP
detectron2中的PS
dectron2是FaceBook提出的一个框架,里面内置非常多种模型,你可以使用这个框架去对自己的数据集去进行一个训练,在Panoptic Sementation的论文中提到了我们现在已经把PS运用在了一部分小型的数据集上,将来我们会把他运用在COCO数据上,没错在dectron2上就已经把PS运用在COCO数据集上了并提供了网络模型参数,你可以拿着这个参数去直接的进行图片的预测
Panoptic Feature Pyramid Networks
PS终于介绍完啦,下面来介绍Panoptic FPN吧,前面PS讲了那么多相比你们也有这样这样一个以后,就是这个PS应该怎么运用到网络当中啊,各种参数都要怎么获取啊。虽然接下来不涉及到代码的部分,但是我会尽可能的说明清楚的,不了解FPN的读者可以先去了解一下FPN再来读会更有利于去理解Panoptic FPN的网络结构
在论文中何大神他们介绍到,我们的工作是赋予Mask R-CNN一个结合了实例分割和语义分割的FPN 主干网络,
让人吃惊的是这个简单的baseline在保留了实例分割的效率的同时也实现了语义分割的相关参数。Panoptic FPN就相当于Mask R-NN的一个插件一样。
虽然在概念上很简单,但是在实现的过程中还算有很多的有挑战性的点。虽然有统一语义和实例分割的尝试,考虑到它们的并行发展和独立的基准,目前要在每一个领域取得最好的成绩所必需的专业化也许是不可避免的。考虑到这些顶级方法在架构上的差异,在为这两个任务设计单个网络时,可能需要考虑实例或语义分段的准确性,相反,我们展示了一个简单、灵活、有效的体系结构,它可以使用一个单独的网络同时生成基于区域的输出(例如分割)和稠密像素输出(用于语义分割)来匹配两个任务的准确性。下面先来简单的介绍一下这个网络

我们从一个FPN网络开始,在Mask R-CNN中,我们使用FPN之上的一个基于区域的分支来进行实例分割,同时,我们在相同的FPN特性上添加了一个轻量级的denseprediction分支,用于语义分割。这个简单的扩展带FPN的掩码RCNN对于这两个任务来说都是快速而准确的baseline。在添加dense-prediction branch时,我们不改变FPN主干,使其与现有的实例分割方法兼容。
Panoptic FPN是基于FPN的Mask RCNN的一种直观扩展,正确地训练这两个分支同时进行基于区域和密度像素的预测对于获得良好的结果是很重要的。同时在联合设置中仔细研究如何平衡两个分支的损失,有效地构建bach size,调整学习率调度,并进行数据扩充。
Model Architecture (网络结构)
FPN(Feature Pyramid Network)
我们先简单的回顾一下FPN,FPN采用具有多种空间分辨率特征的标准网络(如ResNet),并增加了具有横向连接的轻自顶向下通路,可以参考一下我在上面放的图。自顶向下的路径从网络的最深层开始,逐步地对其进行向上采样,同时从自底向上的路径添加高分辨率特性的转换版本。FPN生成一个金字塔,通常具有从1/32到1/4的分辨率,其中每个金字塔级别具有相同的通道维数(缺省为256)。
实例分割分支
FPN的设计,特别是对所有金字塔级别使用相同的通道维数,使得附加基于区域的对象检测器(如Faster R-CNN)变得很容易。Fast R-CNN执行不同金字塔级别的RoI(region of interest)池,并应用一个共享的网络分支来预测每个区域的细化框和类标签。为了输出实例分段,使用了Mask R-CNN
Panoptic FPN
正如之前讨论的,Panoptic FPN的目的是让Mask R-CNN结合FPN让它有能力去对每一个像素点进行语义分割。但是,要实现准确的预测,此任务所使用的特性应该是:
1.具有适当的高分辨率以捕捉精细结构
2.编码足够丰富的语义来准确预测类标签
3.捕获多尺度信息,预测多分辨率下的材料区域
及时FPN是被设计用来进行物体检测的,这些要求——高分辨率、丰富的、多尺度的特征——非常符合FPN的特征。因此,我们建议在FPN上附加一个简单、快速的语义分割分支。
语义分割分支
前面已经提到了,我们可以在FPN上附加一个简单、快速的语义分割分支。为了从FPN特征中生成语义分割输出,论文中提出了一个简单的设计,将来自FPN金字塔各个层次的信息合并到一个单独的输出中,如下图所示。

从最深处的FPN级(at)开始(1/32比例),我们执行3个上采样阶段来生成1/4比例的特征图,其中每个上采样阶段由3x3的卷积、group norm、ReLU和双线性插值。这里我简单的说明一下什么是group norm,group norm就是组归一化,通常我们听到的都是批归一化就是BN层。其实归一化还有很多种分类

- BatchNorm:batch方向做归一化,算NHW的均值
- LayerNorm:channel方向做归一化,算CHW的均值
- InstanceNorm:一个channel内做归一化,算H*W的均值
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值
还有一点就是双线性插值的方法,以前我们做上采样的时候大致就是把像素点扩大,这样会造成图片的模糊,边缘也不是太清楚,采用双线性插值的方法可以让物体的边缘更加的信息。这也是为什么我们看到Panoptic FPN生成的图片为什么边缘都处理的那么好的一个原因。
好的说回网络结构,这种策略在1/16、1/8和1/4的FPN范围内重复(向上采样阶段逐渐减少),结果可以得到一组相同的特征映射1/4比例,然后按元素求和。最后一个使用1 x 1个卷积、4个双线性上采样和softmax生成原始图像分辨率下的每像素类标签。此外对于stuff类,这个分支同时输出了一个特殊的other类,这是为了避免去对预测每个stuff class所在的像素的类。
Training
联合训练
在训练实例分割三个loss, (classification loss), (bounding-box loss)和 (mask loss). 基本所有的的实例分割损失值是这些损失的总和。语义分割损失(Ls)的计算方法是,根据已标记图像像素的数目进行归一化,计算出预测的与地面真值标签之间的每像素的交叉熵损失。
可以发现,这两个分支的损失规模不同,政策也不同。简单地添加它们会降低其中一个任务的最终性能。这可以通过一个简单的损失重新加权的方法其实就可以完成这个功能。 通过调节权重就有可能让训练出的效果在语义分割和实例分割上都取得不错的效果。
Analysis
我们的动机是预测语义分割使用FPN是创建一个简单的单网络基线,它可以执行实例和语义分割。然而,考虑我们的方法相对于流行于语义分割的模型架构的内存和计算占用空间也很有趣。产生高分辨率输出的最常见设计是膨胀卷积和具有横向连接的镜像解码器的对称编码器解码器模型。虽然我们的主要动机是与Mask R-CNN兼容,但我们注意到FPN比通常使用的dilation-8网络要轻得多,比对称的译码器更有效率。大致相当于一个16倍放大的网络(同时产生4倍高分辨率的输出)

这个图是增加图片分辨率的主骨干网络下面 ,每一个网络在下面都有对应的解释我这里就不写了。
在训练之后之前说了那么久的PQ到底干了啥呢?注意,在将后处理合并过程应用于语义分支和实例分支的输出之后,PQ用于评估网络层的预测。
到这里大致的介绍终于是写完了,觉得写的还不错的可以点个赞啥的。
