1. tensorflow 的数据读取机制
以图像数据为例,数据读取过程如下所示:

假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
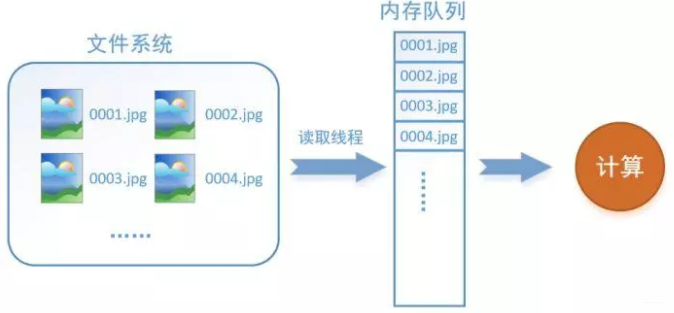
读取线程源源不断地将文件系统中的图片读入到内存队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面用图片的形式来说明这个机制的运行方式。还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束,如下图。

程序运行后,内存队列首先读入A(此时A从文件名队列中出队),然后再读取B和C。



此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
2. TensorFlow数据读取机制对应的函数
如何在TensorFlow中创建这两个内存?
- 创建文件名队列 - tf.train.string_input_producer 阻塞态 + tf.train.start_queue_runners 激活态
tf.train.string_input_producer(
string_tensor,
num_epochs=None,
shuffle=True,
seed=None,
capacity=32,
shared_name=None,
name=None,
cancel_op=None
)把输入的数据进行按照要求排序成一个队列。最常见的是把一堆文件名整理成一个队列。如下操作:
filenames = [os.path.join(data_dir,'data_batch%d.bin' % i ) for i in xrange(1,6)]
filename_queue = tf.train.string_input_producer(filenames)tf.train.string_input_producer有两个重要的参数,一个是num_epochs,它就是上文中提到的epoch数。另一个是shuffle,shuffle是指在epoch内文件顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变。如果设置shuffle=True,那么在epoch内,数据的前后顺序就会被打乱,具体如下图所示。


其实,仅仅应用tf.train.string_input_producer构建的文件名队列是处于阻塞态的,并没有真正的将文件名读入到相应的文件名队列内存中,如下左图所示。为了完成在文件名队列内存中构建文件名队列(也就是我们说的读入数据),我们还需要tf.train.start_queue_runners进行启动,如下右图所示。


我们通常也把tf.train.start_queue_runners叫做‘入栈线程启动器’,使用tf.train.start_queue_runners之后,才会真正启动填充队列的线程,这时系统就不再“阻塞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了。
- 创建数据内存序列
在tensorflow中,数据内存队列不需要自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了。所以TensorFlow高效读取数据机制中,最重要的是完成文件名队列的设计。
3. 为什么要使用TFRecords来进行文件的读写?
在tensorflow中数据的传入方式主要包含以下几种:
- 供给数据(feed): 在tensorflow程序运行的每一步, 让Python代码来供给数据。
- 从文件读取数据: 在tensorflow graph的起始, 让一个输入pipeline从文件中读取数据。
- 预加载数据: 在tensorflow graph中定义常量或变量来保存所有数据(仅适用于数据量比较小的情况)。
当我们遇到数据集比较大的情况时,第一种和最后一种方法会极其占内存,效率很差。那么为什么使用TFRecords会比较快?在于其使用二进制存储文件,也就是将数据存储在一个内存块中,相比其它文件格式要快很多,特别是如果你使用hdd(Hard Disk Drive)而不是ssd(Solid State Disk),因为它涉及移动磁盘阅读器头并且需要相当长的时间。总体而言,通过使用二进制文件,可以更轻松地分发数据,使数据更好地对齐,以实现高效的读取。
- 官方文档:
Another approach is to convert whatever data you have into a supported format. This approach makes it easier to mix and match data sets and network architectures. The recommended format for TensorFlow is a TFRecords file containing tf.train.Example protocol buffers (which contain Features as a field). You write a little program that gets your data, stuffs it in an Example protocol buffer, serializes the protocol buffer to a string, and then writes the string to a TFRecords file using the tf.python_io.TFRecordWriter. For example, tensorflow/examples/how_tos/reading_data/convert_to_records.py converts MNIST data to this format.
To read a file of TFRecords, use tf.TFRecordReader with the tf.parse_single_example decoder. The parse_single_example op decodes the example protocol buffers into tensors. An MNIST example using the data produced by convert_to_records can be found in tensorflow/examples/how_tos/reading_data/fully_connected_reader.py, which you can compare with the fully_connected_feed version.
整个过程其实两部分,一是使用tf.train.Example协议流将文件保存成TFRecords格式的.tfrecords文件,这里主要涉及到使用tf.python_io.TFRecordWriter("train.tfrecords")和tf.train.Example以及tf.train.Features三个函数,第一个是生成需要对应格式的文件,后面两个函数主要是将我们要传入的数据按照一定的格式进行规范化。
另一部分就是在训练模型时将我们生成的.tfrecords文件读入并传到模型中进行使用。这部分主要涉及到使用tf.TFRecordReader("train.tfrecords")和tf.parse_single_example两个函数。第一个函数是将我们的二进制文件读入,第二个则是进行解析然后得到我们想要的数据。
#### 生成train.tfrecords文件 ####
import os
import tensorflow as tf
from PIL import Image
cwd = os.getcwd()
''' 数据目录
-- img1.jpg
img2.jpg
img3.jpg
...
-- img1.jpg
img2.jpg
...
-- ...
'''
writer = tf.python_io.TFRecordWriter("train.tfrecords") # 定义train.tfrecords文件
for index, name in enumerate(classes): # 遍历每一个文件夹
class_path = cwd + name + "/" # 每一个文件夹的路径
for img_name in os.listdir(class_path): # 遍历每个文件夹中所有的图像
img_path = class_path + img_name # 每一张图像的路径
img = Image.open(img_path) # 打开图像
img = img.resize((224, 224)) # 图像裁剪
img_raw = img.tobytes() # 将图像转化为bytes
# 调用Example 和 Feature函数将数据格式化保存起来
# 注意:Features 传入参数为一个字典,方便后续读取数据时的操作
example = tf.train.Example(features=tf.train.Features(feature={
"label": tf.train.Feature(int64_list=tf.train.Int64List(value=[index])),
'img_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
#序列化为字符串,并写入数据
writer.write(example.SerializeToString())
writer.close()基本的,一个Example中包含Features,Features里包含Feature(这里没s)的字典。最后,Feature里包含有一个 FloatList,或者ByteList,或者Int64List
就这样,我们把相关的信息都存到了一个文件中,不用单独的label文件,读取也很方便。
# 从tfrecords文件中读取记录的迭代器
for serialized_example in tf.python_io.tf_record_iterator("train.tfrecords"):
example = tf.train.Example()
example.ParseFromString(serialized_example)
image = example.features.feature['image'].bytes_list.value
label = example.features.feature['label'].int64_list.value
# 可以做一些预处理之类的
print( image, label )3. 使用队列读取tfrecords数据
从TFRecords文件中读取数据, 首先需要用tf.train.string_input_producer生成一个解析队列。之后调用tf.TFRecordReader的tf.parse_single_example解析器。其原理如下图:

解析器首先读取解析队列,返回serialized_example对象,之后调用tf.parse_single_example操作将Example协议缓冲区(protocol buffer)解析为张量。
def read_and_decode(filename):
# 根据文件名生成文件名队列
filename_queue = tf.train.string_input_producer([filename])
# 定义reader
reader = tf.TFRecordReader()
# 返回文件名和文件
_, serialized_example = reader.read(filename_queue)
# 将协议缓冲区Protocol Buffer解析为张量tensor
# 注意到:我们写文件就是采用了字典的方式进行存储的,所以解析的时候依然用字典进行数据提取
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw' : tf.FixedLenFeature([], tf.string),
})
# 将编码为字符串的变量重新变回来,因为写进tfrecord里用to_bytes的形式,也就是字符串
img = tf.decode_raw(features['img_raw'], tf.uint8)
# 检查张量形状是否对齐
img = tf.reshape(img, [224, 224, 3])
# 图像数据格式化为tf.float32
img = tf.cast(img, tf.float32) * (1. / 255) - 0.5
# 标签数据格式化为tf.int32
label = tf.cast(features['label'], tf.int32)
return img, label之后,在训练模型过程中,我们就会很方便用这些数据了,例如:
# 解析tfrecords文件的数据
img, label = read_and_decode("train.tfrecords")
# 通过随机打乱张量的顺序创建batch
# capacity = ( min_after_dequeue + (num_threads + aSmallSafetyMargin * batch_size) )
img_batch, label_batch = tf.train.shuffle_batch(
[img, label], # 入队的张量列表
batch_size=30, # 进行一次批处理的tensor数
capacity=2000, # 队列中最大的元素数
min_after_dequeue=1000,# 一次出列操作完成后,队列中元素的最小数量
num_threads=4 #使用多个线程在tensor_list中读取文件
)
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
# 队列-入栈线程启动器
threads = tf.train.start_queue_runners(sess=sess)
for i in range(3):
val, loss= sess.run([img_batch, label_batch])三个要点作为总结:
- tensorflow里的graph能够记住状态,这使得TFRecordReader能够记住tfrecord的位置,并且始终能返回下一个。而这就要求我们在使用之前,必须初始化整个graph,这里使用了函数tf.initialize_all_variables()来进行初始化
- tensorflow中的队列和普通的队列差不多,不过它里面的operation和tensor都是符号型的,在调用sess.run()时才执行。
- TFRecordReader会一直弹出队列中文件的名字,直到队列为空
4. 参考文章
1. https://zhuanlan.zhihu.com/p/27238630
2. https://blog.csdn.net/liuchonge/article/details/73649251
3. https://www.cnblogs.com/upright/p/6136265.html
4. https://blog.csdn.net/happyhorizion/article/details/77894055