一. 如何评估泛化能力
在机器学习中,我们用训练数据集去训练一个模型,通常会定义一个Loss误差函数。通过梯度下降等算法将这个Loss最小化,来提高模型的性能。然而我们学习一个模型的目的是为了解决实际的问题,单纯地将训练数据集的loss最小化,并不能保证它在泛化一般问题时仍然是最优,甚至不能保证模型是可用的。所以我们要定义一种方式,来评估模型的泛化能力,也就是预测能力。
通常来说,我们会将数据集分成,训练集和测试集,比例一般是7:3。使用训练集去训练模型,使用测试集去评估模型的泛化能力。
对于回归问题:我们可以直接在测试集上计算代价函数,来评估泛化能力。
对于分类问题:
1.可以使用在测试集上计算代价函数,来评估泛化能力。
2.还可以计算误分类比率:当发生误判时,err=1;正确判定时,err=0;
然后对测试集上的所有元素的err求和,做平均值。
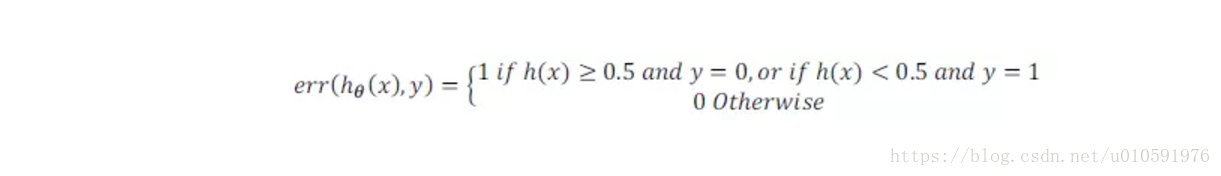
二. 模型选择
有的时候,我们在开始时,可能有多个模型可以选择,我们需要选择一个最优的模型,然后再优化。
假设我们要在10个不同次数的二项式模型之间进行选择:
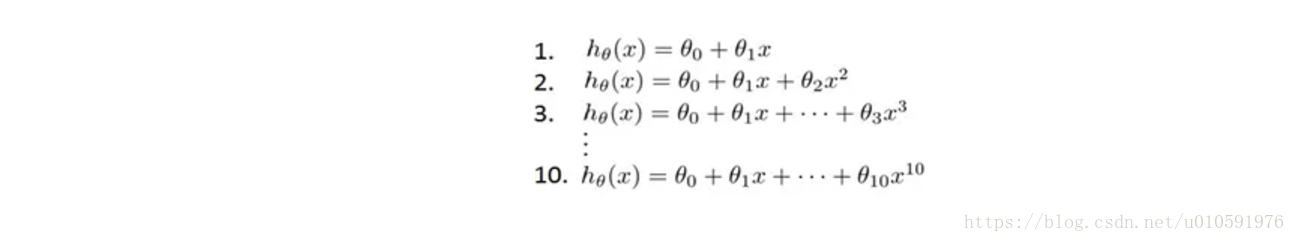
如果我们使用训练集训练这10个模型,然后用测试集评估出一个泛化能力最好的模型,假设选定模型3。这看似很有道理,但是在选定模型后,调节参数的过程中,还能使用测试集吗?我们已经用测试集来选择模型了,这有失公平性。
因此,我们将数据集划分为 训练集:验证集:测试集=6:2:2,用验证集去选择模型,用测试集去调节参数。
总结:
在有多个备选模型,多个备选正则参数,多种神经网络隐藏层结构,等情况下,我们可以使用验证集来选择模型,然后用测试集评估泛化能力。

三. 偏差与方差
假设:数据集是D,数据集元素个数是m,经过模型预测的输出是f(x),样本客观真实标记是yi,数据集中的标记是yDi。有可能由于数据错误,导致数据集中的标记与实际不同。

由公式可以看出:
偏差度量了学习算法的期望预测与真实标记的偏离程度,刻画了算法的准确性。
方差度量了学习算法预测值的波动情况。
噪声则表示任何学习算法在泛化能力的下界,描述了学习问题本身的难度。
假设我们现在有一组训练数据,需要训练一个模型。在训练过程的最初,bias很大,因为我们的模型还没有来得及开始学习,也就是与“真实模型”差距很大。然而此时variance却很小,因为训练数据集(training data)还没有来得及对模型产生影响,所以此时将模型应用于“不同的”训练数据集也不会有太大差异。而随着训练过程的进行,bias变小了,因为我们的模型变得“聪明”了,懂得了更多关于“真实模型”的信息,输出值与真实值之间更加接近了。但是如果我们训练得时间太久了,variance就会变得很大,因为我们除了学习到关于真实模型的信息,还学到了许多具体的,只针对我们使用的训练集(真实数据的子集)的信息。
总结一下:
偏差:刻画模型预测能力的准确性,如果数据足够多,bias始终过大,则可能模型复杂度不够,欠拟合。
方差:刻画模型预测值的浮动情况,如果方差过大,波动性太强,说明拟合的太好,可能发生过拟合。
四. 误差诊断
假设用d表示多项式的指数(也就是模型复杂程度)
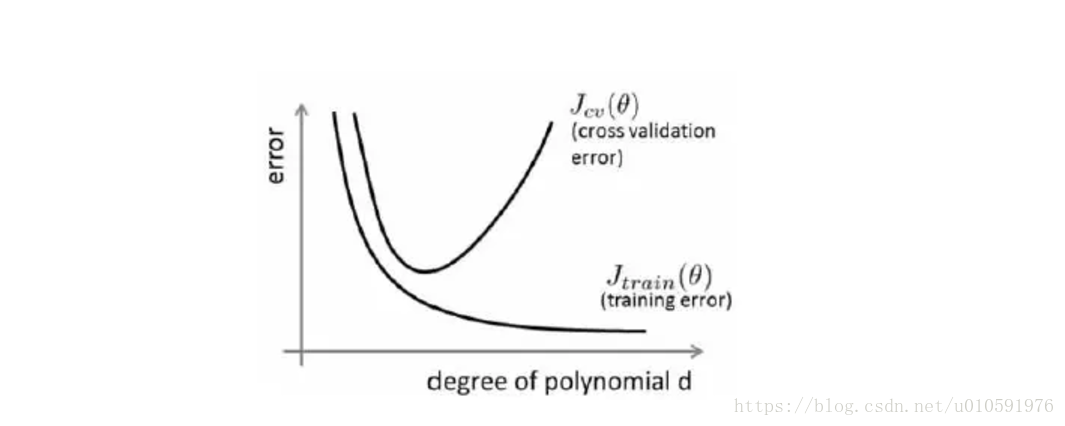
- 对于训练集,当 d 较小时,模型拟合程度更低,误差较大;随着 d 的增长,拟合程度提高,误差减小。 对于验证集,当 d
较小时,模型拟合程度低,误差较大;但是随着 d 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
总结:如果验证集误差较大?如何判断过拟合、欠拟合?
训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
五. 学习曲线
学习曲线就是一种很好的工具,可以使用学习曲线来判断某一个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线通过增加训练集的规模,来判断拟合问题。
即,如果我们有100行数据,我们从1行数据开始,逐渐学习更多行的数据。
错误评估方式依旧使用代价函数:
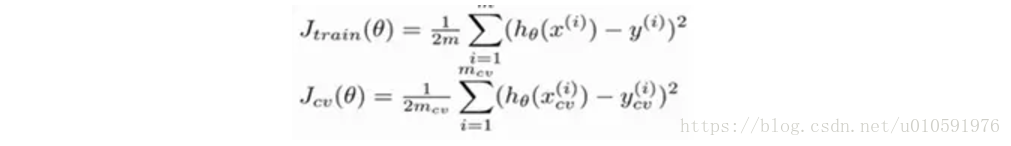
一般来说,当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。随着数据量的增多,泛化能力越来越好,验证集的错误减少,但是训练集的拟合误差变大,毕竟样本越多越难拟合。
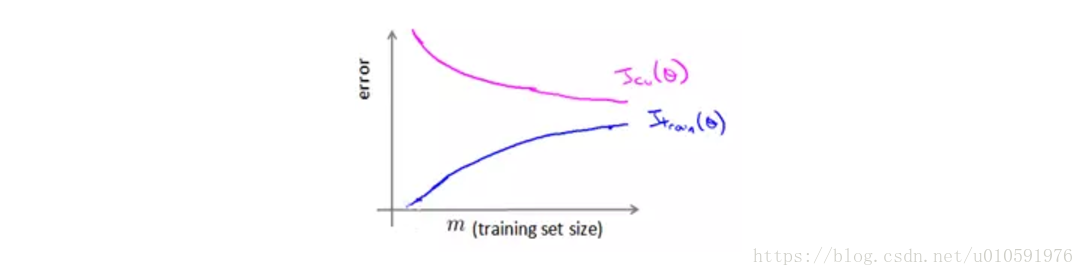
欠拟合
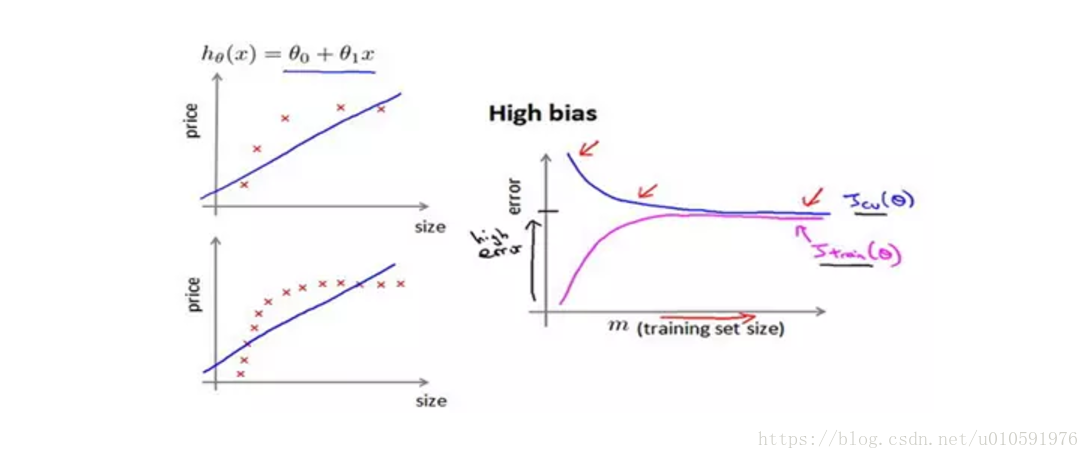
如果选用的模型过于简单,开始阶段,随着样本的增多,验证集的错误会逐渐减少,但是很快维持一个高错误的水平不变。而对于训练集,开始时误差也很小,随着样本增多,很快达到接近验证集的错误水平。也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助,是模型本身制约了学习能力。
总结:训练集与测试集快速变化到一个稳定的高错误水平,且不再变化,很可能发生欠拟合。
过拟合
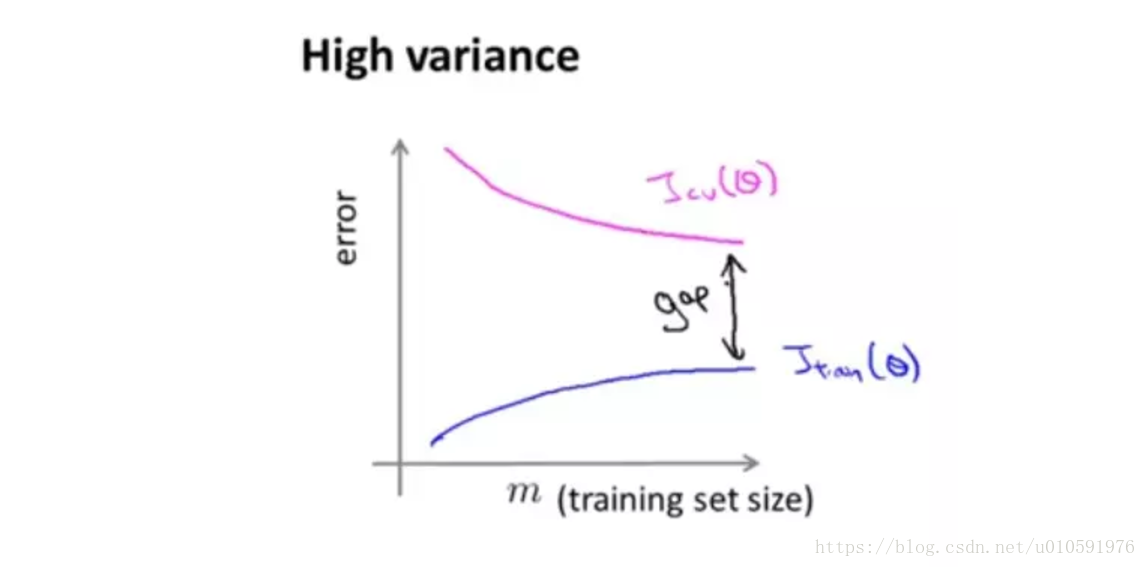
如果选用的模型过于复杂,发生过拟合。验证集的错误会一直维持在高水平,测试集的错误会一直维持在一个较低水平,他们之间差距较大。随着样本的不断增加,验证集错误不断减小,训练集错误不断增加,如果继续增加大量样本,他们将会逐渐靠近。也就是说,在过拟合的情况下,增加样本数量,可以提高算法效果。
总结:训练集维持在较低错误水平,测试集维持在较高错误水平,差距较大,很可能发生过拟合。
六. 改进策略
1. 过拟合:
获得更多的训练实例
尝试减少特征的数量
尝试增加正则化程度λ
增加训练数据可以有限的避免过拟合。
交叉检验,通过交叉检验得到较优的模型参数;
特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间。
正则化,常用的有 L1L1、L2L2 正则。而且 L1L1 正则还可以自动进行特征选择。(即保留特征,但是减小特征变量的数量级)。
如果有正则项则可以考虑增大正则项参数 λ.
增加训练数据可以有限的避免过拟合.
Bagging ,将多个弱学习器Bagging 一下效果会好很多,比如随机森林等;
2. 欠拟合:
尝试获得更多的特征
尝试增加多项式特征
尝试减少正则化程度λ
增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
尝试非线性模型,比如核SVM 等模型;
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小。使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络, 然后选择交叉验证集代价最小的神经网络。
参考博客: