选择合适的机器学习算法和模型需要考虑多个因素,包括以下几个步骤:

-
理解问题:首先,要清楚地理解你要解决的问题是什么,以及问题的性质(如分类、回归、聚类等)。这将有助于缩小算法选择的范围。
-
数据分析:对数据进行分析是选择适当算法和模型的关键步骤。了解数据的属性、规模、质量以及特征之间的关系,可以帮助确定适合的算法类型。
-
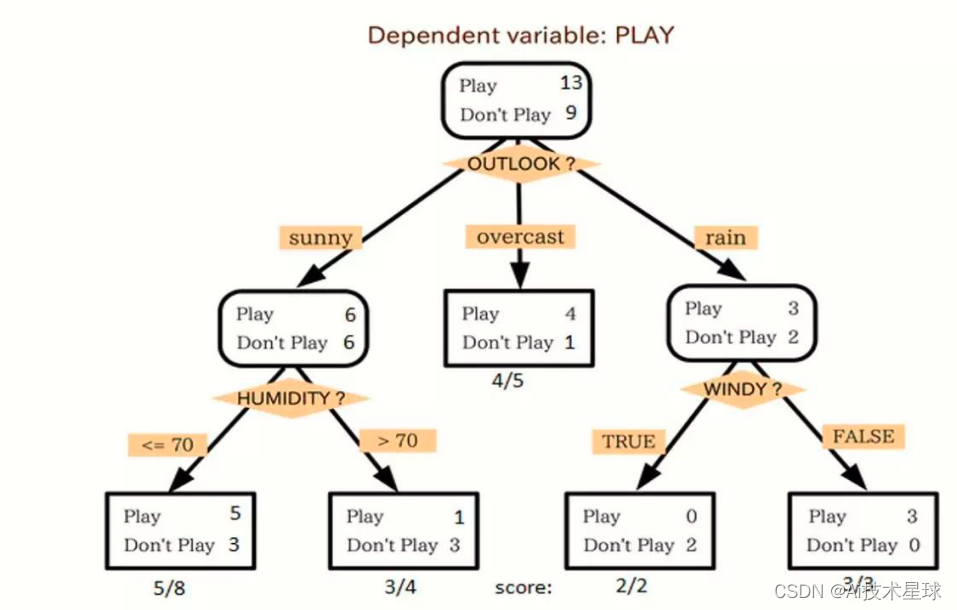
算法选择:根据问题的性质和数据的特点,选择适合的机器学习算法。如果是监督学习问题,考虑使用分类算法(如逻辑回归、决策树)或回归算法(如线性回归、支持向量回归)。对于无监督学习问题,可以考虑使用聚类算法(如K均值聚类、层次聚类)或关联规则挖掘算法。如果问题涉及序列数据或时间依赖关系,可以考虑使用循环神经网络(RNN)或长短期记忆网络(LSTM)等算法。
-
模型训练和评估:选择了算法和模型后,需要进行模型的训练和评估。一般的步骤是将数据划分为训练集和测试集,使用训练集来训练模型,然后使用测试集来评估模型的性能。常用的评估指标包括准确率、精确率、召回率、F1值等,具体指标的选择取决于问题的性质和需求。
-
调参和优化:根据模型的性能评估结果,可以进行模型的调参和优化。这包括调整算法的超参数(如学习率、正则化参数等)和模型的结构(如神经网络的层数、节点数等),以提高模型的性能和泛化能力。

在进行模型选择、训练和评估时,可以遵循以下几个最佳实践:
-
数据预处理:对数据进行清洗、缺失值处理、特征选择和特征缩放等预处理步骤,以提高模型的性能和鲁棒性。
-
交叉验证:除了划分训练集和测试集外,还可以使用交叉验证方法来更全面地评估模型的性能。常见的交叉验证方法包括k折交叉验证和留一交叉验证。
-
防止过拟合:过拟合是模型在训练集上表现很好,但在测试集上性能较差的现象。为了防止过拟合,可以采用正则化技术(如L1、L2正则化)、提前停止训练、增加训练数据量等方法。
-
模型比较:在选择模型时,可以尝试多个算法和模型,并进行比较。这可以通过交叉验证或使用独立的验证集来进行。
-
持续监控和更新:一旦模型被部署和使用,应该定期监控模型的性能,并根据新数据的特点进行模型更新和改进。
-
感谢大家对文章的喜欢,欢迎关注威
❤公众号【AI技术星球】回复(123)
白嫖配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频
内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等
关于机器学习算法和模型的选择、训练和评估的更详细信息,可以参考相关的机器学习教程、书籍和论文。