决策树
import pandas as pd
import numpy as np
import graphviz
from sklearn.tree import DecisionTreeRegressor
from sklearn import tree
X = np.array(data[['C', 'E']]) # Create an array
y = np.array(data['NOx'])
regt = DecisionTreeRegressor(max_depth=4)
regt = regt.fit(X, y) # Build a decision tree regressor from the training set (X, y)
dot_data = tree.export_graphviz(regt, out_file=None) # Export a decision tree in DOT format
graph = graphviz.Source(dot_data)
graph.render("tree") # Save the source to file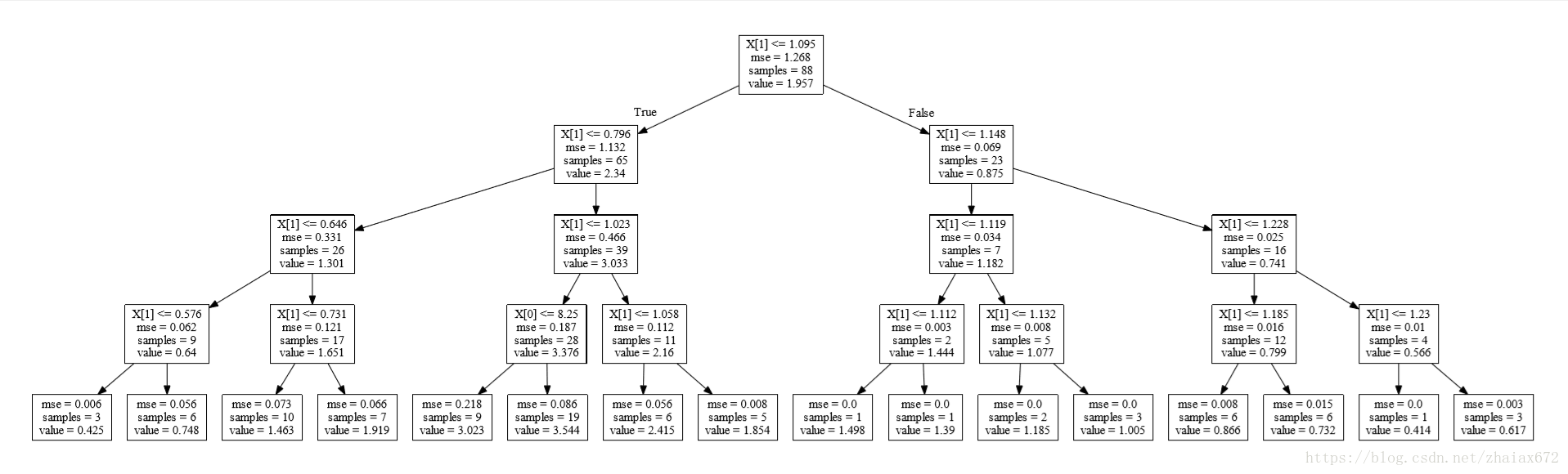
[注]
节点属性:
X[1]:X = np.array(data[['C', 'E']])中的E列,为特征值samples:样本的数量mse:均方误差(mean-square error, MSE)是反映估计量与被估计量之间差异程度的一种问题:节点 value 代表?
print(regt.score(X, y))
------------------------------------
0.949306568162regt1 = regt.fit(X[:, 1].reshape(-1, 1), y) # reshape(-1, 1) 将数组改为 多行1列
dot_data = tree.export_graphviz(regt, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("tree1")
regt1.score(X[:, 1].reshape(-1, 1), y)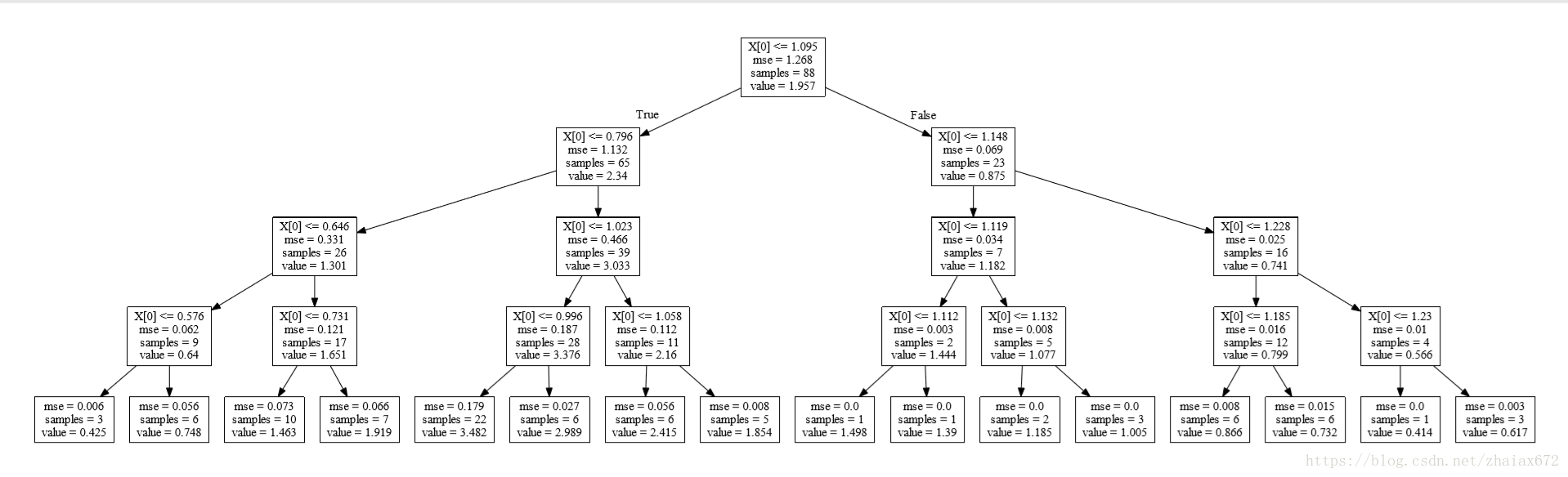
对比过后,发现 tree 和 tree1 完全相同
问题:tree 和 tree1 的关系?
u = np.sort(np.unique(X[:, 1]))
t = np.diff(u)/2+u[:-1] # diff() 后一个元素减去前一个元素
#
mse = []
mse1 = []
mse2 = []
for i in t:
m1 = (y[X[:, 1] < i]-np.mean(y[X[:, 1] < i]))**2 # X[:, 1] 取该二维数组第二列所有数据
m2 = (y[X[:, 1] > i]-np.mean(y[X[:, 1] > i]))**2
mse1.append(np.mean(m1)) # “拍脑袋”平方和
mse2.append(np.mean(m2)) # “拍脑袋”平方和
mse.append((np.sum(m1)+np.sum(m2))/len(y))
I = np.argmin(mse) # 求mse最小值的index
MSE0 = np.mean((y-np.mean(y))**2)
print("Original total MSE={}\nSplit point={}\nMin mse={}\nLeft mse={}\nRight mse={}".format(MSE0, I, mse[I], mse1[I], mse2[I]))
-------------------------------------------------------------------------------
Original total MSE=1.26845241619
Split point=60
Min mse=0.854108834661
Left mse=1.13202721562
Right mse=0.0686873232514上述代码的函数形式
def spl(X, y):
u = np.sort(np.unique(X))
t = np.diff(u)/2+u[:-1]
mse = []
mse1 = []
mse2 = []
for i in t:
m1 = (y[X < i]-np.mean(y[X < i]))**2
m2 = (y[X > i]-np.mean(y[X > i]))**2
mse1.append(np.mean(m1))
mse2.append(np.mean(m2))
mse.append((np.sum(m1)+np.sum(m2))/len(y))
i = np.argmin(mse)
return mse[i], t[i], mse1[i], mse2[i]
print(spl(X[:, 1], y))
print(spl(X[:,0], y))
------------------------------------------------------------------
(0.8541088346609912, 1.0945, 1.1320272156213018, 0.06868732325141778)
(1.264189318071551, 13.5, 1.103670472054112, 1.5072607134693878)def FCV(x, y, regr, cv=10, seed=2015):
np.random.seed(seed)
ind = np.arange(len(y))
np.random.shuffle(ind) # 随机化下标
X_folds = np.array_split(x[ind], cv)
y_folds = np.array_split(y[ind], cv)
X2 = np.empty((0, X.shape[1]), float)
y2 = np.empty((0, y.shape[0]), float)
yp = np.empty((0, y.shape[0]), float)
for k in range(cv):
X_train = list(X_folds) # 只有list才能pop
X_test = X_train.pop(k) # 从中取出第k份
X_train = np.concatenate(X_train) # 合并剩下的cv-1份
y_train = list(y_folds)
y_test = y_train.pop(k)
y_train = np.concatenate(y_train)
regr.fit(X_train, y_train) # 拟合选中的regr模型
y2 = np.append(y2, y_test)
X2 = np.append(X2, X_test)
yp = np.append(yp, regr.predict(X_test))
nmse = np.sum((y2-yp)**2)/np.sum((y2-np.mean(y2))**2)
r2 = 1-nmse
return np.array([nmse, r2])求出 线性回归 LinearRegression 和 决策树 DecisionTreeRegressor 所对应的 NMSE 和 R^2
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
names = ["Linear Regression", "Decision Tree"]
regressors = [LinearRegression(), DecisionTreeRegressor(max_depth=4)]
A = np.empty((0, 2), float)
for reg in regressors:
tt = np.array(FCV(X, y, reg, 8))
tt.shape = (1, 2) # 一行二列
A = np.append(A, tt, axis=0) # 把各种方法的回归结果合并
print(A)
-----------------------------------------------------------------
[[ 1.06233633 -0.06233633]
[ 0.15896376 0.84103624]]import matplotlib.pyplot as plt
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(121)
ax.bar(np.arange(np.array(A).shape[0]), np.array(A)[:, 0])
ax.set_xticklabels(names) # 标注回归方法
fig.autofmt_xdate() # 回归方法标注斜放
ax.set_ylabel('NMSE')
ax.set_title('NMSE')
ax.set_xticks(np.arange(np.array(A).shape[0]) + 0.35)
bx = fig.add_subplot(122)
bx.bar(np.arange(np.array(A).shape[0]), np.array(A)[:, 1])
bx.set_xticklabels(names)
fig.autofmt_xdate()
bx.set_ylabel('Score')
bx.set_title('Score')
bx.set_xticks(np.arange(np.array(A).shape[0]) + 0.35)
plt.savefig("examples.jpg")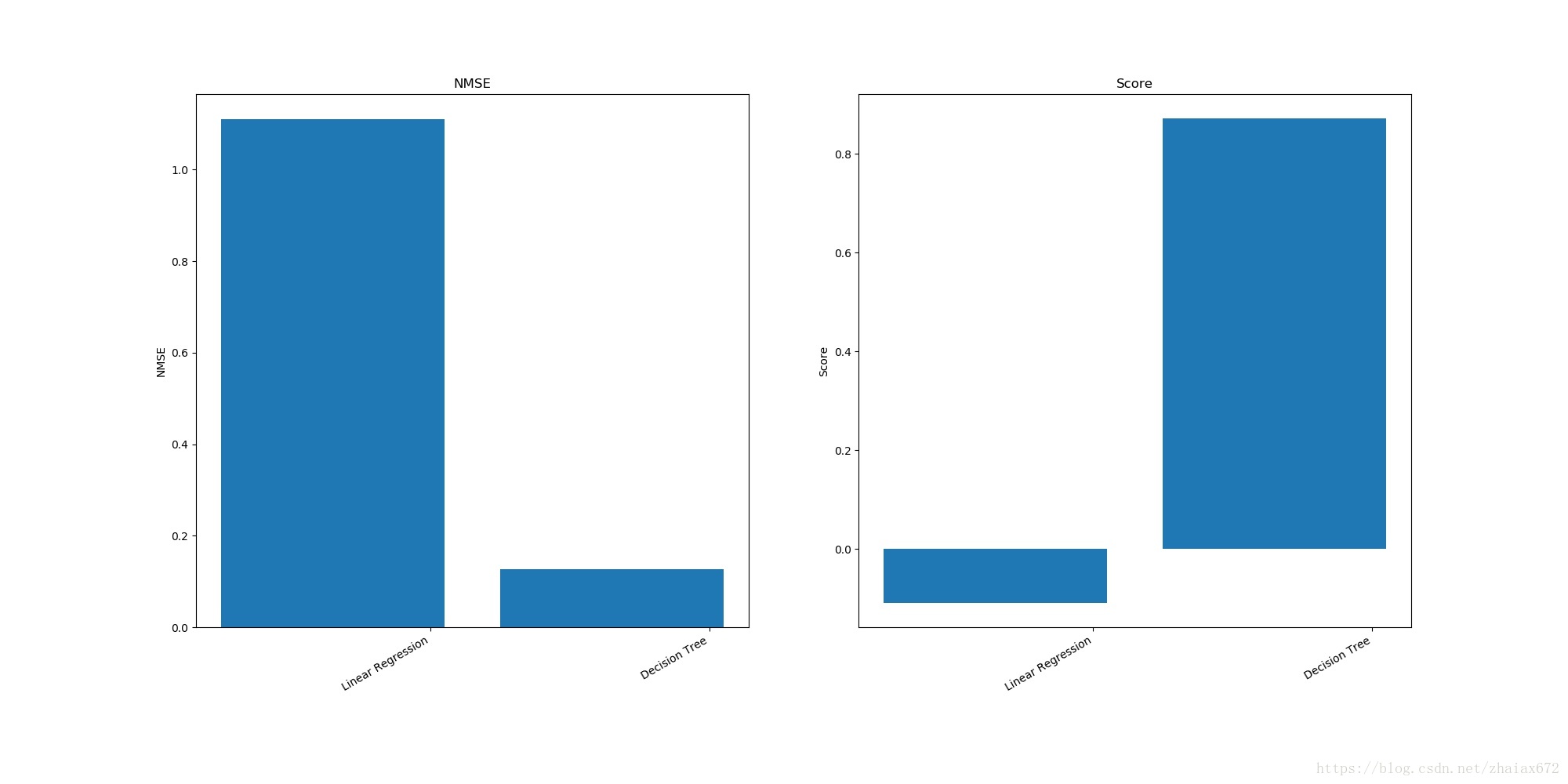
问题:上述图表现的是?

bagging 是由 Breiman 提出的一个简单的组合模型, 它对原始数据集做很多次放回抽样, 每次抽取和样本量同样多的观测值, 放回抽样使得每次都有大约百分之三十多的观测值没有抽到, 另一些观测值则会重复抽到, 如此得到很多不同的数据集, 然后对于每个数据集建立一个决策树, 因此产生大量决策树. 对于回归来说, 一个新的观测值通过如此多的决策树得到很多预测值, 最终结果为这些预测值的简单平均.
from sklearn.ensemble import BaggingRegressor
regr = BaggingRegressor(n_estimators=100, oob_score=True, random_state=1010)
regr.fit(X, y.ravel())
print("Score:", regr.score(X, y)) # Score为可决系数R^2
print("NMSE:", 1-regr.score(X, y)) # 标准化均方误差 NMSEBreiman 发明的随机森林的原理并不复杂, 和 bagging 类似, 它对原始数据集做很多次放回抽样, 每次抽取和样本量同样多的观测值, 由于是放回抽样, 每次都有一些观测值没有抽到, 一些观测值会重复抽到, 如此会得到很多不同的数据集, 然后对于每个数据集建立一个决策树, 因此产生大量决策树. 和 bagging 不同的是, 在随机森林每棵树的每个节点, 拆分变量不是由所有变量竞争, 而是由随机挑选的少数变量竞争, 而且每棵树都长到底. 拆分变量候选者的数目限制可以避免由于强势变量主宰而忽略的数据关系中的细节, 因而大大提高了模型对数据的代表性. 随机森林的最终结果是所有树的结果的平均, 也就是说, 一个新的观测值, 通过许多棵树(比如 n 棵)得到 n 个预测值, 最终用这 n 个预测值的平均作为最终结果.
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
regr = RandomForestRegressor(n_estimators=500, oob_score=True, random_state=1010)
regr.fit(X, y.ravel())
print("Variable importance:\n", regr.feature_importances_)
print("Score:\n", regr.oob_score_)
---------------------------------------------------------------------]
('Variable importance:\n', array([0.03731845, 0.00096088, 0.00580794, 0.00074913, 0.02247829,
0.43575755, 0.01257118, 0.06612205, 0.00307613, 0.01341358,
0.01549635, 0.0116068 , 0.37464165]))
('Score:\n', 0.8829155069608635)
<font color=red >问题:score 代表的是 可决系数R^2 吗?</font>哑元:
某个参数如果在子程序或函数中没有用到,那就被称为哑元。
函数的形参又称“哑元”,实参又称“实元”。